6.1 KiB
Pose estimation

Get started
PoseNet is a vision model that can be used to estimate the pose of a person in an image or video by estimating where key body joints are.
Download starter modelIf you want to experiment this on a web browser, check out the TensorFlow.js GitHub repository.
Example applications and guides
We provide example TensorFlow Lite applications demonstrating the PoseNet model for both Android and iOS.
Android example iOS exampleHow it works
Pose estimation refers to computer vision techniques that detect human figures in images and videos, so that one could determine, for example, where someone’s elbow shows up in an image.
To be clear, this technology is not recognizing who is in an image. The algorithm is simply estimating where key body joints are.
The key points detected are indexed by "Part ID", with a confidence score between 0.0 and 1.0, 1.0 being the highest.
| Id | Part |
|---|---|
| 0 | nose |
| 1 | leftEye |
| 2 | rightEye |
| 3 | leftEar |
| 4 | rightEar |
| 5 | leftShoulder |
| 6 | rightShoulder |
| 7 | leftElbow |
| 8 | rightElbow |
| 9 | leftWrist |
| 10 | rightWrist |
| 11 | leftHip |
| 12 | rightHip |
| 13 | leftKnee |
| 14 | rightKnee |
| 15 | leftAnkle |
| 16 | rightAnkle |
Performance Benchmarks
Performance benchmark numbers are generated with the tool described here.
| Model Name | Model size | Device | GPU | CPU |
|---|---|---|---|---|
| Posenet | 12.7 Mb | Pixel 3 (Android 10) | 12ms | 31ms* |
| Pixel 4 (Android 10) | 12ms | 19ms* | ||
| iPhone XS (iOS 12.4.1) | 4.8ms | 22ms** |
* 4 threads used.
** 2 threads used on iPhone for the best performance result.
Example output

How it performs
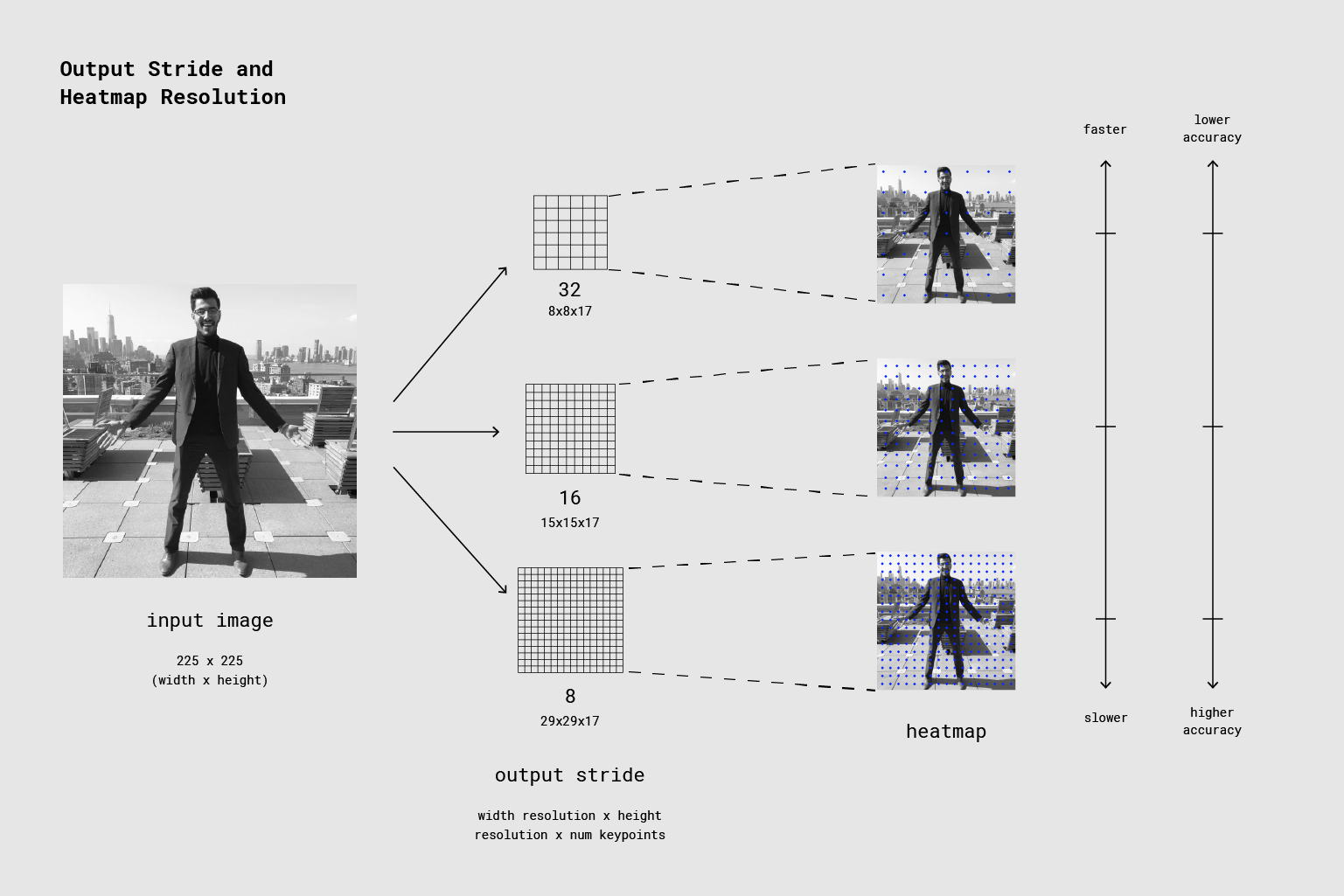
Performance varies based on your device and output stride (heatmaps and offset vectors). The PoseNet model is image size invariant, which means it can predict pose positions in the same scale as the original image regardless of whether the image is downscaled. This means PoseNet can be configured to have a higher accuracy at the expense of performance.
The output stride determines how much we’re scaling down the output relative to the input image size. It affects the size of the layers and the model outputs. The higher the output stride, the smaller the resolution of layers in the network and the outputs, and correspondingly their accuracy. In this implementation, the output stride can have values of 8, 16, or 32. In other words, an output stride of 32 will result in the fastest performance but lowest accuracy, while 8 will result in the highest accuracy but slowest performance. We recommend starting with 16.
The following image shows how the output stride determines how much we’re scaling down the output relative to the input image size. A higher output stride is faster but results in lower accuracy.
Read more about pose estimation
- Blog post: Real-time Human Pose Estimation in the Browser with TensorFlow.js
- TF.js GitHub: Pose Detection in the Browser: PoseNet Model
- Blog post: Track human poses in real-time on Android with TensorFlow Lite