Delete content under models/
{kind=link}
|
Before Width: | Height: | Size: 1.0 MiB |
@ -1,129 +0,0 @@
|
||||
# BERT Question and Answer
|
||||
|
||||
Use a pre-trained model to answer questions based on the content of a given
|
||||
passage.
|
||||
|
||||
## Get started
|
||||
|
||||
<img src="images/screenshot.gif" class="attempt-right" style="max-width: 300px">
|
||||
|
||||
If you are new to TensorFlow Lite and are working with Android or iOS, we
|
||||
recommend exploring the following example applications that can help you get
|
||||
started.
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/bert_qa/android">Android
|
||||
example</a>
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/bert_qa/ios">iOS
|
||||
example</a>
|
||||
|
||||
If you are using a platform other than Android/iOS, or you are already familiar
|
||||
with the
|
||||
[TensorFlow Lite APIs](https://www.tensorflow.org/api_docs/python/tf/lite), you
|
||||
can download our starter question and answer model.
|
||||
|
||||
<a class="button button-primary" href="https://tfhub.dev/tensorflow/lite-model/mobilebert/1/metadata/1?lite-format=tflite">Download
|
||||
starter model and vocab</a>
|
||||
|
||||
For more information about metadata and associated fields (e.g. `vocab.txt`) see
|
||||
<a href="https://www.tensorflow.org/lite/convert/metadata#read_the_metadata_from_models">Read
|
||||
the metadata from models</a>.
|
||||
|
||||
## How it works
|
||||
|
||||
The model can be used to build a system that can answer users’ questions in
|
||||
natural language. It was created using a pre-trained BERT model fine-tuned on
|
||||
SQuAD 1.1 dataset.
|
||||
|
||||
[BERT](https://github.com/google-research/bert), or Bidirectional Encoder
|
||||
Representations from Transformers, is a method of pre-training language
|
||||
representations which obtains state-of-the-art results on a wide array of
|
||||
Natural Language Processing tasks.
|
||||
|
||||
This app uses a compressed version of BERT, MobileBERT, that runs 4x faster and
|
||||
has 4x smaller model size.
|
||||
|
||||
[SQuAD](https://rajpurkar.github.io/SQuAD-explorer/), or Stanford Question
|
||||
Answering Dataset, is a reading comprehension dataset consisting of articles
|
||||
from Wikipedia and a set of question-answer pairs for each article.
|
||||
|
||||
The model takes a passage and a question as input, then returns a segment of the
|
||||
passage that most likely answers the question. It requires semi-complex
|
||||
pre-processing including tokenization and post-processing steps that are
|
||||
described in the BERT [paper](https://arxiv.org/abs/1810.04805) and implemented
|
||||
in the sample app.
|
||||
|
||||
## Performance benchmarks
|
||||
|
||||
Performance benchmark numbers are generated with the tool
|
||||
[described here](https://www.tensorflow.org/lite/performance/benchmarks).
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Model Name</th>
|
||||
<th>Model size </th>
|
||||
<th>Device </th>
|
||||
<th>CPU</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tr>
|
||||
<td rowspan = 3>
|
||||
<a href="https://tfhub.dev/tensorflow/lite-model/mobilebert/1/metadata/1?lite-format=tflite">Mobile Bert</a>
|
||||
</td>
|
||||
<td rowspan = 3>
|
||||
100.5 Mb
|
||||
</td>
|
||||
<td>Pixel 3 (Android 10) </td>
|
||||
<td>123ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Pixel 4 (Android 10) </td>
|
||||
<td>74ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>iPhone XS (iOS 12.4.1) </td>
|
||||
<td>257ms** </td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
\* 4 threads used.
|
||||
|
||||
\*\* 2 threads used on iPhone for the best performance result.
|
||||
|
||||
## Example output
|
||||
|
||||
### Passage (Input)
|
||||
|
||||
> Google LLC is an American multinational technology company that specializes in
|
||||
> Internet-related services and products, which include online advertising
|
||||
> technologies, search engine, cloud computing, software, and hardware. It is
|
||||
> considered one of the Big Four technology companies, alongside Amazon, Apple,
|
||||
> and Facebook.
|
||||
>
|
||||
> Google was founded in September 1998 by Larry Page and Sergey Brin while they
|
||||
> were Ph.D. students at Stanford University in California. Together they own
|
||||
> about 14 percent of its shares and control 56 percent of the stockholder
|
||||
> voting power through supervoting stock. They incorporated Google as a
|
||||
> California privately held company on September 4, 1998, in California. Google
|
||||
> was then reincorporated in Delaware on October 22, 2002. An initial public
|
||||
> offering (IPO) took place on August 19, 2004, and Google moved to its
|
||||
> headquarters in Mountain View, California, nicknamed the Googleplex. In August
|
||||
> 2015, Google announced plans to reorganize its various interests as a
|
||||
> conglomerate called Alphabet Inc. Google is Alphabet's leading subsidiary and
|
||||
> will continue to be the umbrella company for Alphabet's Internet interests.
|
||||
> Sundar Pichai was appointed CEO of Google, replacing Larry Page who became the
|
||||
> CEO of Alphabet.
|
||||
|
||||
### Question (Input)
|
||||
|
||||
> Who is the CEO of Google?
|
||||
|
||||
### Answer (Output)
|
||||
|
||||
> Sundar Pichai
|
||||
|
||||
## Read more about BERT
|
||||
|
||||
* Academic paper: [BERT: Pre-training of Deep Bidirectional Transformers for
|
||||
Language Understanding](https://arxiv.org/abs/1810.04805)
|
||||
* [Open-source implementation of BERT](https://github.com/google-research/bert)
|
||||
{kind=link}
|
Before Width: | Height: | Size: 717 KiB |
{kind=link}
|
Before Width: | Height: | Size: 79 KiB |
{kind=link}
|
Before Width: | Height: | Size: 63 KiB |
{kind=link}
|
Before Width: | Height: | Size: 117 KiB |
{kind=link}
|
Before Width: | Height: | Size: 463 KiB |
@ -1,285 +0,0 @@
|
||||
# Image classification
|
||||
|
||||
<img src="../images/image.png" class="attempt-right">
|
||||
|
||||
The task of identifying what an image represents is called _image
|
||||
classification_. An image classification model is trained to recognize various
|
||||
classes of images. For example, you may train a model to recognize photos
|
||||
representing three different types of animals: rabbits, hamsters, and dogs.
|
||||
TensorFlow Lite provides optimized pre-trained models that you can deploy in
|
||||
your mobile applications. Learn more about image classification using TensorFlow
|
||||
[here](https://www.tensorflow.org/tutorials/images/classification).
|
||||
|
||||
The following image shows the output of the image classification model on
|
||||
Android.
|
||||
|
||||
<img src="images/android_banana.png" alt="Screenshot of Android example" width="30%">
|
||||
|
||||
## Get started
|
||||
|
||||
If you are new to TensorFlow Lite and are working with Android or iOS, it is
|
||||
recommended you explore the following example applications that can help you get
|
||||
started.
|
||||
|
||||
You can leverage the out-of-box API from
|
||||
[TensorFlow Lite Task Library](../../inference_with_metadata/task_library/image_classifier)
|
||||
to integrate image classification models in just a few lines of code. You can
|
||||
also build your own custom inference pipeline using the
|
||||
[TensorFlow Lite Support Library](../../inference_with_metadata/lite_support).
|
||||
|
||||
The Android example below demonstrates the implementation for both methods as
|
||||
[lib_task_api](https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android/lib_task_api)
|
||||
and
|
||||
[lib_support](https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android/lib_support),
|
||||
respectively.
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android">View
|
||||
Android example</a>
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/ios">View
|
||||
iOS example</a>
|
||||
|
||||
If you are using a platform other than Android/iOS, or if you are already
|
||||
familiar with the
|
||||
[TensorFlow Lite APIs](https://www.tensorflow.org/api_docs/python/tf/lite),
|
||||
download the starter model and supporting files (if applicable).
|
||||
|
||||
<a class="button button-primary" href="https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_1.0_224_quant_and_labels.zip">Download
|
||||
starter model</a>
|
||||
|
||||
## Model description
|
||||
|
||||
### How it works
|
||||
|
||||
During training, an image classification model is fed images and their
|
||||
associated _labels_. Each label is the name of a distinct concept, or class,
|
||||
that the model will learn to recognize.
|
||||
|
||||
Given sufficient training data (often hundreds or thousands of images per
|
||||
label), an image classification model can learn to predict whether new images
|
||||
belong to any of the classes it has been trained on. This process of prediction
|
||||
is called _inference_. Note that you can also use
|
||||
[transfer learning](https://www.tensorflow.org/tutorials/images/transfer_learning)
|
||||
to identify new classes of images by using a pre-existing model. Transfer
|
||||
learning does not require a very large training dataset.
|
||||
|
||||
When you subsequently provide a new image as input to the model, it will output
|
||||
the probabilities of the image representing each of the types of animal it was
|
||||
trained on. An example output might be as follows:
|
||||
|
||||
<table style="width: 40%;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Animal type</th>
|
||||
<th>Probability</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>Rabbit</td>
|
||||
<td>0.07</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Hamster</td>
|
||||
<td>0.02</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="background-color: #fcb66d;">Dog</td>
|
||||
<td style="background-color: #fcb66d;">0.91</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Each number in the output corresponds to a label in the training data.
|
||||
Associating the output with the three labels the model was trained on, you can
|
||||
see that the model has predicted a high probability that the image represents a
|
||||
dog.
|
||||
|
||||
You might notice that the sum of all the probabilities (for rabbit, hamster, and
|
||||
dog) is equal to 1. This is a common type of output for models with multiple
|
||||
classes (see
|
||||
<a href="https://developers.google.com/machine-learning/crash-course/multi-class-neural-networks/softmax">Softmax</a>
|
||||
for more information).
|
||||
|
||||
Note: Image classification can only tell you the probability that an image
|
||||
represents one or more of the classes that the model was trained on. It cannot
|
||||
tell you the position or identity of objects within the image. If you need to
|
||||
identify objects and their positions within images, you should use an
|
||||
<a href="../object_detection/overview.md">object detection</a> model.
|
||||
|
||||
<h4>Ambiguous results</h4>
|
||||
|
||||
Since the output probabilities will always sum to 1, if an image is not
|
||||
confidently recognized as belonging to any of the classes the model was trained
|
||||
on you may see the probability distributed throughout the labels without any one
|
||||
value being significantly larger.
|
||||
|
||||
For example, the following might indicate an ambiguous result:
|
||||
|
||||
<table style="width: 40%;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Label</th>
|
||||
<th>Probability</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>rabbit</td>
|
||||
<td>0.31</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>hamster</td>
|
||||
<td>0.35</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>dog</td>
|
||||
<td>0.34</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
If your model frequently returns ambiguous results, you may need a different,
|
||||
more accurate model.
|
||||
|
||||
<h3>Choosing a model architecture</h3>
|
||||
|
||||
TensorFlow Lite provides you with a variety of image classification models which
|
||||
are all trained on the original dataset. Model architectures like MobileNet,
|
||||
Inception, and NASNet are available on the
|
||||
<a href="../../guide/hosted_models.md">hosted models page</a>. To choose the best model for
|
||||
your use case, you need to consider the individual architectures as well as some
|
||||
of the tradeoffs between various models. Some of these model tradeoffs are based
|
||||
on metrics such as performance, accuracy, and model size. For example, you might
|
||||
need a faster model for building a bar code scanner while you might prefer a
|
||||
slower, more accurate model for a medical imaging app.
|
||||
|
||||
Note that the <a href=https://www.tensorflow.org/lite/guide/hosted_models#image_classification>image classification models</a> provided accept varying sizes of input. For some models, this is indicated in the filename. For example, the Mobilenet_V1_1.0_224 model accepts an input of 224x224 pixels. All of the models require three color channels per pixel (red, green, and blue). Quantized models require 1 byte per channel, and float models require 4 bytes per channel. The <a href="https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android/EXPLORE_THE_CODE.md">Android</a> and <a href="https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/ios/EXPLORE_THE_CODE.md">iOS</a> code samples demonstrate how to process full-sized camera images into the required format for each model.
|
||||
|
||||
<h3>Uses and limitations</h3>
|
||||
|
||||
The TensorFlow Lite image classification models are useful for single-label
|
||||
classification; that is, predicting which single label the image is most likely to
|
||||
represent. They are trained to recognize 1000 image classes. For a full list of
|
||||
classes, see the labels file in the
|
||||
<a href="https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_1.0_224_quant_and_labels.zip">model
|
||||
zip</a>.
|
||||
|
||||
If you want to train a model to recognize new classes, see
|
||||
<a href="#customize_model">Customize model</a>.
|
||||
|
||||
For the following use cases, you should use a different type of model:
|
||||
|
||||
<ul>
|
||||
<li>Predicting the type and position of one or more objects within an image (see <a href="../object_detection/overview.md">Object detection</a>)</li>
|
||||
<li>Predicting the composition of an image, for example subject versus background (see <a href="../segmentation/overview.md">Segmentation</a>)</li>
|
||||
</ul>
|
||||
|
||||
Once you have the starter model running on your target device, you can
|
||||
experiment with different models to find the optimal balance between
|
||||
performance, accuracy, and model size.
|
||||
|
||||
<h3>Customize model</h3>
|
||||
|
||||
The pre-trained models provided are trained to recognize 1000 classes of images.
|
||||
For a full list of classes, see the labels file in the
|
||||
<a href="https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_1.0_224_quant_and_labels.zip">model
|
||||
zip</a>.
|
||||
|
||||
You can also use transfer learning to re-train a model to
|
||||
recognize classes not in the original set. For example, you could re-train the
|
||||
model to distinguish between different species of tree, despite there being no
|
||||
trees in the original training data. To do this, you will need a set of training
|
||||
images for each of the new labels you wish to train.
|
||||
|
||||
Learn how to perform transfer learning in the
|
||||
<a href="https://codelabs.developers.google.com/codelabs/recognize-flowers-with-tensorflow-on-android/index.html#0">Recognize
|
||||
flowers with TensorFlow</a> codelab, or with the
|
||||
<a href="https://www.tensorflow.org/lite/tutorials/model_maker_image_classification">Model Maker library</a>.
|
||||
|
||||
<h2>Performance benchmarks</h2>
|
||||
|
||||
Model performance is measured in terms of the amount of time it takes for a
|
||||
model to run inference on a given piece of hardware. The lower the time, the faster
|
||||
the model.
|
||||
|
||||
The performance you require depends on your application. Performance can be
|
||||
important for applications like real-time video, where it may be important to
|
||||
analyze each frame in the time before the next frame is drawn (e.g. inference
|
||||
must be faster than 33ms to perform real-time inference on a 30fps video
|
||||
stream).
|
||||
|
||||
The TensorFlow Lite quantized MobileNet models' performance range from 3.7ms to
|
||||
80.3 ms.
|
||||
|
||||
Performance benchmark numbers are generated with the
|
||||
<a href="https://www.tensorflow.org/lite/performance/benchmarks">benchmarking tool</a>.
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Model Name</th>
|
||||
<th>Model size </th>
|
||||
<th>Device </th>
|
||||
<th>NNAPI</th>
|
||||
<th>CPU</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tr>
|
||||
<td rowspan = 3>
|
||||
<a href="https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_1.0_224_quant_and_labels.zip">Mobilenet_V1_1.0_224_quant</a>
|
||||
</td>
|
||||
<td rowspan = 3>
|
||||
4.3 Mb
|
||||
</td>
|
||||
<td>Pixel 3 (Android 10) </td>
|
||||
<td>6ms</td>
|
||||
<td>13ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Pixel 4 (Android 10) </td>
|
||||
<td>3.3ms</td>
|
||||
<td>5ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>iPhone XS (iOS 12.4.1) </td>
|
||||
<td></td>
|
||||
<td>11ms** </td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
\* 4 threads used.
|
||||
|
||||
\*\* 2 threads used on iPhone for the best performance result.
|
||||
|
||||
### Model accuracy
|
||||
|
||||
Accuracy is measured in terms of how often the model correctly classifies an
|
||||
image. For example, a model with a stated accuracy of 60% can be expected to
|
||||
classify an image correctly an average of 60% of the time.
|
||||
|
||||
The [list of hosted models](../../guide/hosted_models.md) provides Top-1 and
|
||||
Top-5 accuracy statistics. Top-1 refers to how often the correct label appears
|
||||
as the label with the highest probability in the model’s output. Top-5 refers to
|
||||
how often the correct label appears in the 5 highest probabilities in the
|
||||
model’s output.
|
||||
|
||||
The TensorFlow Lite quantized MobileNet models’ Top-5 accuracy range from 64.4
|
||||
to 89.9%.
|
||||
|
||||
### Model size
|
||||
|
||||
The size of a model on-disk varies with its performance and accuracy. Size may
|
||||
be important for mobile development (where it might impact app download sizes)
|
||||
or when working with hardware (where available storage might be limited).
|
||||
|
||||
The TensorFlow Lite quantized MobileNet models' sizes range from 0.5 to 3.4 MB.
|
||||
|
||||
## Further reading and resources
|
||||
|
||||
Use the following resources to learn more about concepts related to image
|
||||
classification:
|
||||
|
||||
* [Image classification using TensorFlow](https://www.tensorflow.org/tutorials/images/classification)
|
||||
* [Image classification with CNNs](https://www.tensorflow.org/tutorials/images/cnn)
|
||||
* [Transfer learning](https://www.tensorflow.org/tutorials/images/transfer_learning)
|
||||
* [Data augmentation](https://www.tensorflow.org/tutorials/images/data_augmentation)
|
||||
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 275 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 15 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB |
{kind=link}
|
Before Width: | Height: | Size: 155 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 724 KiB |
{kind=link}
|
Before Width: | Height: | Size: 675 KiB |
@ -1,388 +0,0 @@
|
||||
# Object detection
|
||||
|
||||
Given an image or a video stream, an object detection model can identify which
|
||||
of a known set of objects might be present and provide information about their
|
||||
positions within the image.
|
||||
|
||||
For example, this screenshot of the <a href="#get_started">example
|
||||
application</a> shows how two objects have been recognized and their positions
|
||||
annotated:
|
||||
|
||||
<img src="images/android_apple_banana.png" alt="Screenshot of Android example" width="30%">
|
||||
|
||||
## Get started
|
||||
|
||||
To learn how to use object detection in a mobile app, explore the
|
||||
<a href="#example_applications_and_guides">Example applications and guides</a>.
|
||||
|
||||
If you are using a platform other than Android or iOS, or if you are already
|
||||
familiar with the
|
||||
<a href="https://www.tensorflow.org/api_docs/python/tf/lite">TensorFlow Lite
|
||||
APIs</a>, you can download our starter object detection model and the
|
||||
accompanying labels.
|
||||
|
||||
<a class="button button-primary" href="https://tfhub.dev/tensorflow/lite-model/ssd_mobilenet_v1/1/metadata/1?lite-format=tflite">Download
|
||||
starter model with Metadata</a>
|
||||
|
||||
For more information about Metadata and associated fields (eg: `labels.txt`) see
|
||||
<a href="https://www.tensorflow.org/lite/convert/metadata#read_the_metadata_from_models">Read
|
||||
the metadata from models</a>
|
||||
|
||||
If you want to train a custom detection model for your own task, see
|
||||
<a href="#model-customization">Model customization</a>.
|
||||
|
||||
For the following use cases, you should use a different type of model:
|
||||
|
||||
<ul>
|
||||
<li>Predicting which single label the image most likely represents (see <a href="../image_classification/overview.md">image classification</a>)</li>
|
||||
<li>Predicting the composition of an image, for example subject versus background (see <a href="../segmentation/overview.md">segmentation</a>)</li>
|
||||
</ul>
|
||||
|
||||
### Example applications and guides
|
||||
|
||||
If you are new to TensorFlow Lite and are working with Android or iOS, we
|
||||
recommend exploring the following example applications that can help you get
|
||||
started.
|
||||
|
||||
#### Android
|
||||
|
||||
You can leverage the out-of-box API from
|
||||
[TensorFlow Lite Task Library](../../inference_with_metadata/task_library/object_detector)
|
||||
to integrate object detection models in just a few lines of code. You can also
|
||||
build your own custom inference pipeline using the
|
||||
[TensorFlow Lite Interpreter Java API](../../guide/inference#load_and_run_a_model_in_java).
|
||||
|
||||
The Android example below demonstrates the implementation for both methods as
|
||||
[lib_task_api](https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/android/lib_task_api)
|
||||
and
|
||||
[lib_interpreter](https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/android/lib_interpreter),
|
||||
respectively.
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/android">View
|
||||
Android example</a>
|
||||
|
||||
#### iOS
|
||||
|
||||
You can integrate the model using the
|
||||
[TensorFlow Lite Interpreter Swift API](../../guide/inference#load_and_run_a_model_in_swift).
|
||||
See the iOS example below.
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/ios">View
|
||||
iOS example</a>
|
||||
|
||||
## Model description
|
||||
|
||||
This section describes the signature for
|
||||
[Single-Shot Detector](https://arxiv.org/abs/1512.02325) models converted to
|
||||
TensorFlow Lite from the
|
||||
[TensorFlow Object Detection API](https://github.com/tensorflow/models/blob/master/research/object_detection/).
|
||||
|
||||
An object detection model is trained to detect the presence and location of
|
||||
multiple classes of objects. For example, a model might be trained with images
|
||||
that contain various pieces of fruit, along with a _label_ that specifies the
|
||||
class of fruit they represent (e.g. an apple, a banana, or a strawberry), and
|
||||
data specifying where each object appears in the image.
|
||||
|
||||
When an image is subsequently provided to the model, it will output a list of
|
||||
the objects it detects, the location of a bounding box that contains each
|
||||
object, and a score that indicates the confidence that detection was correct.
|
||||
|
||||
### Input Signature
|
||||
|
||||
The model takes an image as input.
|
||||
|
||||
Lets assume the expected image is 300x300 pixels, with three channels (red,
|
||||
blue, and green) per pixel. This should be fed to the model as a flattened
|
||||
buffer of 270,000 byte values (300x300x3). If the model is
|
||||
<a href="../../performance/post_training_quantization.md">quantized</a>, each
|
||||
value should be a single byte representing a value between 0 and 255.
|
||||
|
||||
You can take a look at our
|
||||
[example app code](https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/android)
|
||||
to understand how to do this pre-processing on Android.
|
||||
|
||||
### Output Signature
|
||||
|
||||
The model outputs four arrays, mapped to the indices 0-4. Arrays 0, 1, and 2
|
||||
describe `N` detected objects, with one element in each array corresponding to
|
||||
each object.
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Index</th>
|
||||
<th>Name</th>
|
||||
<th>Description</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>0</td>
|
||||
<td>Locations</td>
|
||||
<td>Multidimensional array of [N][4] floating point values between 0 and 1, the inner arrays representing bounding boxes in the form [top, left, bottom, right]</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>1</td>
|
||||
<td>Classes</td>
|
||||
<td>Array of N integers (output as floating point values) each indicating the index of a class label from the labels file</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>2</td>
|
||||
<td>Scores</td>
|
||||
<td>Array of N floating point values between 0 and 1 representing probability that a class was detected</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>3</td>
|
||||
<td>Number of detections</td>
|
||||
<td>Integer value of N</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
NOTE: The number of results (10 in the above case) is a parameter set while
|
||||
exporting the detection model to TensorFlow Lite. See
|
||||
<a href="#model-customization">Model customization</a> for more details.
|
||||
|
||||
For example, imagine a model has been trained to detect apples, bananas, and
|
||||
strawberries. When provided an image, it will output a set number of detection
|
||||
results - in this example, 5.
|
||||
|
||||
<table style="width: 60%;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Class</th>
|
||||
<th>Score</th>
|
||||
<th>Location</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>Apple</td>
|
||||
<td>0.92</td>
|
||||
<td>[18, 21, 57, 63]</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Banana</td>
|
||||
<td>0.88</td>
|
||||
<td>[100, 30, 180, 150]</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Strawberry</td>
|
||||
<td>0.87</td>
|
||||
<td>[7, 82, 89, 163] </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Banana</td>
|
||||
<td>0.23</td>
|
||||
<td>[42, 66, 57, 83]</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Apple</td>
|
||||
<td>0.11</td>
|
||||
<td>[6, 42, 31, 58]</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### Confidence score
|
||||
|
||||
To interpret these results, we can look at the score and the location for each
|
||||
detected object. The score is a number between 0 and 1 that indicates confidence
|
||||
that the object was genuinely detected. The closer the number is to 1, the more
|
||||
confident the model is.
|
||||
|
||||
Depending on your application, you can decide a cut-off threshold below which
|
||||
you will discard detection results. For the current example, a sensible cut-off
|
||||
is a score of 0.5 (meaning a 50% probability that the detection is valid). In
|
||||
that case, the last two objects in the array would be ignored because those
|
||||
confidence scores are below 0.5:
|
||||
|
||||
<table style="width: 60%;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Class</th>
|
||||
<th>Score</th>
|
||||
<th>Location</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>Apple</td>
|
||||
<td>0.92</td>
|
||||
<td>[18, 21, 57, 63]</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Banana</td>
|
||||
<td>0.88</td>
|
||||
<td>[100, 30, 180, 150]</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Strawberry</td>
|
||||
<td>0.87</td>
|
||||
<td>[7, 82, 89, 163] </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="background-color: #e9cecc; text-decoration-line: line-through;">Banana</td>
|
||||
<td style="background-color: #e9cecc; text-decoration-line: line-through;">0.23</td>
|
||||
<td style="background-color: #e9cecc; text-decoration-line: line-through;">[42, 66, 57, 83]</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="background-color: #e9cecc; text-decoration-line: line-through;">Apple</td>
|
||||
<td style="background-color: #e9cecc; text-decoration-line: line-through;">0.11</td>
|
||||
<td style="background-color: #e9cecc; text-decoration-line: line-through;">[6, 42, 31, 58]</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
The cut-off you use should be based on whether you are more comfortable with
|
||||
false positives (objects that are wrongly identified, or areas of the image that
|
||||
are erroneously identified as objects when they are not), or false negatives
|
||||
(genuine objects that are missed because their confidence was low).
|
||||
|
||||
For example, in the following image, a pear (which is not an object that the
|
||||
model was trained to detect) was misidentified as a "person". This is an example
|
||||
of a false positive that could be ignored by selecting an appropriate cut-off.
|
||||
In this case, a cut-off of 0.6 (or 60%) would comfortably exclude the false
|
||||
positive.
|
||||
|
||||
<img src="images/false_positive.png" alt="Screenshot of Android example showing a false positive" width="30%">
|
||||
|
||||
#### Location
|
||||
|
||||
For each detected object, the model will return an array of four numbers
|
||||
representing a bounding rectangle that surrounds its position. For the starter
|
||||
model provided, the numbers are ordered as follows:
|
||||
|
||||
<table style="width: 50%; margin: 0 auto;">
|
||||
<tbody>
|
||||
<tr style="border-top: none;">
|
||||
<td>[</td>
|
||||
<td>top,</td>
|
||||
<td>left,</td>
|
||||
<td>bottom,</td>
|
||||
<td>right</td>
|
||||
<td>]</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
The top value represents the distance of the rectangle’s top edge from the top
|
||||
of the image, in pixels. The left value represents the left edge’s distance from
|
||||
the left of the input image. The other values represent the bottom and right
|
||||
edges in a similar manner.
|
||||
|
||||
Note: Object detection models accept input images of a specific size. This is likely to be different from the size of the raw image captured by your device’s camera, and you will have to write code to crop and scale your raw image to fit the model’s input size (there are examples of this in our <a href="#get_started">example applications</a>).<br /><br />The pixel values output by the model refer to the position in the cropped and scaled image, so you must scale them to fit the raw image in order to interpret them correctly.
|
||||
|
||||
## Performance benchmarks
|
||||
|
||||
Performance benchmark numbers for our
|
||||
<a class="button button-primary" href="https://storage.googleapis.com/download.tensorflow.org/models/tflite/coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.zip">starter
|
||||
model</a> are generated with the tool
|
||||
[described here](https://www.tensorflow.org/lite/performance/benchmarks).
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Model Name</th>
|
||||
<th>Model size </th>
|
||||
<th>Device </th>
|
||||
<th>GPU</th>
|
||||
<th>CPU</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tr>
|
||||
<td rowspan = 3>
|
||||
<a href="https://tfhub.dev/tensorflow/lite-model/ssd_mobilenet_v1/1/metadata/1?lite-format=tflite">COCO SSD MobileNet v1</a>
|
||||
</td>
|
||||
<td rowspan = 3>
|
||||
27 Mb
|
||||
</td>
|
||||
<td>Pixel 3 (Android 10) </td>
|
||||
<td>22ms</td>
|
||||
<td>46ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Pixel 4 (Android 10) </td>
|
||||
<td>20ms</td>
|
||||
<td>29ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>iPhone XS (iOS 12.4.1) </td>
|
||||
<td>7.6ms</td>
|
||||
<td>11ms** </td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
\* 4 threads used.
|
||||
|
||||
\*\* 2 threads used on iPhone for the best performance result.
|
||||
|
||||
## Model Customization
|
||||
|
||||
### Pre-trained models
|
||||
|
||||
Mobile-optimized detection models with a variety of latency and precision
|
||||
characteristics can be found in the
|
||||
[Detection Zoo](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md#mobile-models).
|
||||
Each one of them follows the input and output signatures described in the
|
||||
following sections.
|
||||
|
||||
Most of the download zips contain a `model.tflite` file. If there isn't one, a
|
||||
TensorFlow Lite flatbuffer can be generated using
|
||||
[these instructions](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_on_mobile_tensorflowlite.md).
|
||||
SSD models from the
|
||||
[TF2 Object Detection Zoo](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md)
|
||||
can also be converted to TensorFlow Lite using the instructions
|
||||
[here](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_on_mobile_tf2.md).
|
||||
It is important to note that detection models cannot be converted directly using
|
||||
the [TensorFlow Lite Converter](https://www.tensorflow.org/lite/convert), since
|
||||
they require an intermediate step of generating a mobile-friendly source model.
|
||||
The scripts linked above perform this step.
|
||||
|
||||
Both the
|
||||
[TF1](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_on_mobile_tensorflowlite.md)
|
||||
&
|
||||
[TF2](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_on_mobile_tensorflowlite.md)
|
||||
exporting scripts have parameters that can enable a larger number of output
|
||||
objects or slower, more-accurate post processing. Please use `--help` with the
|
||||
scripts to see an exhaustive list of supported arguments.
|
||||
|
||||
> Currently, on-device inference is only optimized with SSD models. Better
|
||||
> support for other architectures like CenterNet and EfficientDet is being
|
||||
> investigated.
|
||||
|
||||
### How to choose a model to customize?
|
||||
|
||||
Each model comes with its own precision (quantified by mAP value) and latency
|
||||
characteristics. You should choose a model that works the best for your use-case
|
||||
and intended hardware. For example, the
|
||||
[Edge TPU](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md#pixel4-edge-tpu-models)
|
||||
models are ideal for inference on Google's Edge TPU on Pixel 4.
|
||||
|
||||
You can use our
|
||||
[benchmark tool](https://www.tensorflow.org/lite/performance/measurement) to
|
||||
evaluate models and choose the most efficient option available.
|
||||
|
||||
## Fine-tuning models on custom data
|
||||
|
||||
The pre-trained models we provide are trained to detect 90 classes of objects.
|
||||
For a full list of classes, see the labels file in the
|
||||
<a href="https://tfhub.dev/tensorflow/lite-model/ssd_mobilenet_v1/1/metadata/1?lite-format=tflite">model
|
||||
metadata</a>.
|
||||
|
||||
You can use a technique known as transfer learning to re-train a model to
|
||||
recognize classes not in the original set. For example, you could re-train the
|
||||
model to detect multiple types of vegetable, despite there only being one
|
||||
vegetable in the original training data. To do this, you will need a set of
|
||||
training images for each of the new labels you wish to train. Please see our
|
||||
[Few-shot detection Colab](https://github.com/tensorflow/models/blob/master/research/object_detection/colab_tutorials/eager_few_shot_od_training_tflite.ipynb)
|
||||
as an example of fine-tuning a pre-trained model with few examples.
|
||||
|
||||
For fine-tuning with larger datasets, take a look at the these guides for
|
||||
training your own models with the TensorFlow Object Detection API:
|
||||
[TF1](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_training_and_evaluation.md),
|
||||
[TF2](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_training_and_evaluation.md).
|
||||
Once trained, they can be converted to a TFLite-friendly format with the
|
||||
instructions here:
|
||||
[TF1](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_on_mobile_tensorflowlite.md),
|
||||
[TF2](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_on_mobile_tensorflowlite.md)
|
||||
@ -1,214 +0,0 @@
|
||||
# Pose estimation
|
||||
|
||||
<img src="../images/pose.png" class="attempt-right" />
|
||||
|
||||
Pose estimation is the task of using an ML model to estimate the pose of a
|
||||
person from an image or a video by estimating the spatial locations of key body
|
||||
joints (keypoints).
|
||||
|
||||
## Get started
|
||||
|
||||
If you are new to TensorFlow Lite and are working with Android or iOS, explore
|
||||
the following example applications that can help you get started.
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/posenet/android">
|
||||
Android example</a>
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/posenet/ios">
|
||||
iOS example</a>
|
||||
|
||||
If you are familiar with the
|
||||
[TensorFlow Lite APIs](https://www.tensorflow.org/api_docs/python/tf/lite),
|
||||
download the starter PoseNet model and supporting files.
|
||||
|
||||
<a class="button button-primary" href="https://storage.googleapis.com/download.tensorflow.org/models/tflite/posenet_mobilenet_v1_100_257x257_multi_kpt_stripped.tflite">
|
||||
Download starter model</a>
|
||||
|
||||
If you want to try pose estimation on a web browser, check out the
|
||||
<a href="https://github.com/tensorflow/tfjs-models/tree/master/posenet">
|
||||
TensorFlow JS GitHub repository</a>.
|
||||
|
||||
## Model description
|
||||
|
||||
### How it works
|
||||
|
||||
Pose estimation refers to computer vision techniques that detect human figures
|
||||
in images and videos, so that one could determine, for example, where someone’s
|
||||
elbow shows up in an image. It is important to be aware of the fact that pose
|
||||
estimation merely estimates where key body joints are and does not recognize who
|
||||
is in an image or video.
|
||||
|
||||
The PoseNet model takes a processed camera image as the input and outputs
|
||||
information about keypoints. The keypoints detected are indexed by a part ID,
|
||||
with a confidence score between 0.0 and 1.0. The confidence score indicates the
|
||||
probability that a keypoint exists in that position.
|
||||
|
||||
The various body joints detected by the PoseNet model are tabulated below:
|
||||
|
||||
<table style="width: 30%;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Id</th>
|
||||
<th>Part</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>0</td>
|
||||
<td>nose</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>1</td>
|
||||
<td>leftEye</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>2</td>
|
||||
<td>rightEye</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>3</td>
|
||||
<td>leftEar</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>4</td>
|
||||
<td>rightEar</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>5</td>
|
||||
<td>leftShoulder</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>6</td>
|
||||
<td>rightShoulder</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>7</td>
|
||||
<td>leftElbow</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>8</td>
|
||||
<td>rightElbow</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>9</td>
|
||||
<td>leftWrist</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>10</td>
|
||||
<td>rightWrist</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>11</td>
|
||||
<td>leftHip</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>12</td>
|
||||
<td>rightHip</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>13</td>
|
||||
<td>leftKnee</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>14</td>
|
||||
<td>rightKnee</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>15</td>
|
||||
<td>leftAnkle</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>16</td>
|
||||
<td>rightAnkle</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
An example output is shown below:
|
||||
|
||||
<img alt="Animation showing pose estimation" src="https://www.tensorflow.org/images/lite/models/pose_estimation.gif"/>
|
||||
|
||||
## Performance benchmarks
|
||||
|
||||
Performance varies based on your device and output stride (heatmaps and offset
|
||||
vectors). The PoseNet model is image size invariant, which means it can predict
|
||||
pose positions in the same scale as the original image regardless of whether the
|
||||
image is downscaled. This means that you configure the model to have a higher
|
||||
accuracy at the expense of performance.
|
||||
|
||||
The output stride determines how much the output is scaled down relative to the
|
||||
input image size. It affects the size of the layers and the model outputs.
|
||||
|
||||
The higher the output stride, the smaller the resolution of layers in the
|
||||
network and the outputs, and correspondingly their accuracy. In this
|
||||
implementation, the output stride can have values of 8, 16, or 32. In other
|
||||
words, an output stride of 32 will result in the fastest performance but lowest
|
||||
accuracy, while 8 will result in the highest accuracy but slowest performance.
|
||||
The recommended starting value is 16.
|
||||
|
||||
The following image shows how the output stride determines how much the output
|
||||
is scaled down relative to the input image size. A higher output stride is
|
||||
faster but results in lower accuracy.
|
||||
|
||||
<img alt="Output stride and heatmap resolution" src="../images/output_stride.png" >
|
||||
|
||||
Performance benchmark numbers are generated with the tool
|
||||
[described here](https://www.tensorflow.org/lite/performance/benchmarks).
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Model Name</th>
|
||||
<th>Model size </th>
|
||||
<th>Device </th>
|
||||
<th>GPU</th>
|
||||
<th>CPU</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tr>
|
||||
<td rowspan = 3>
|
||||
<a href="https://storage.googleapis.com/download.tensorflow.org/models/tflite/posenet_mobilenet_v1_100_257x257_multi_kpt_stripped.tflite">Posenet</a>
|
||||
</td>
|
||||
<td rowspan = 3>
|
||||
12.7 Mb
|
||||
</td>
|
||||
<td>Pixel 3 (Android 10) </td>
|
||||
<td>12ms</td>
|
||||
<td>31ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Pixel 4 (Android 10) </td>
|
||||
<td>12ms</td>
|
||||
<td>19ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>iPhone XS (iOS 12.4.1) </td>
|
||||
<td>4.8ms</td>
|
||||
<td>22ms** </td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
\* 4 threads used.
|
||||
|
||||
\*\* 2 threads used on iPhone for the best performance result.
|
||||
|
||||
## Further reading and resources
|
||||
|
||||
* Check out this
|
||||
[blog post](https://medium.com/tensorflow/track-human-poses-in-real-time-on-android-with-tensorflow-lite-e66d0f3e6f9e)
|
||||
to learn more about pose estimation using TensorFlow Lite.
|
||||
* Check out this
|
||||
[blog post](https://medium.com/tensorflow/real-time-human-pose-estimation-in-the-browser-with-tensorflow-js-7dd0bc881cd5)
|
||||
to learn more about pose estimation using TensorFlow JS.
|
||||
* Read the PoseNet paper [here](https://arxiv.org/abs/1803.08225)
|
||||
|
||||
Also, check out these use cases of pose estimation.
|
||||
|
||||
<ul>
|
||||
<li><a href="https://vimeo.com/128375543">‘PomPom Mirror’</a></li>
|
||||
<li><a href="https://youtu.be/I5__9hq-yas">Amazing Art Installation Turns You Into A Bird | Chris Milk "The Treachery of Sanctuary"</a></li>
|
||||
<li><a href="https://vimeo.com/34824490">Puppet Parade - Interactive Kinect Puppets</a></li>
|
||||
<li><a href="https://vimeo.com/2892576">Messa di Voce (Performance), Excerpts</a></li>
|
||||
<li><a href="https://www.instagram.com/p/BbkKLiegrTR/">Augmented reality</a></li>
|
||||
<li><a href="https://www.instagram.com/p/Bg1EgOihgyh/">Interactive animation</a></li>
|
||||
<li><a href="https://www.runnersneed.com/expert-advice/gear-guides/gait-analysis.html">Gait analysis</a></li>
|
||||
</ul>
|
||||
{kind=link}
|
Before Width: | Height: | Size: 296 KiB |
@ -1,122 +0,0 @@
|
||||
# Recommendation
|
||||
|
||||
Personalized recommendations are widely used for a variety of use cases on
|
||||
mobile devices, such as media content retrieval, shopping product suggestion,
|
||||
and next app recommendation. If you are interested in providing personalized
|
||||
recommendations in your application while respecting user privacy, we recommend
|
||||
exploring the following example and toolkit.
|
||||
|
||||
## Get started
|
||||
|
||||
<img src="images/screenshot.gif" class="attempt-right" style="max-width: 300px">
|
||||
|
||||
We provide a TensorFlow Lite sample application that demonstrates how to
|
||||
recommend relevant items to users on Android.
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/recommendation/android">Android
|
||||
example</a>
|
||||
|
||||
If you are using a platform other than Android, or you are already familiar with
|
||||
the TensorFlow Lite APIs, you can download our starter recommendation model.
|
||||
|
||||
<a class="button button-primary" href="https://storage.googleapis.com/download.tensorflow.org/models/tflite/recommendation/20200720/recommendation.tar.gz">Download
|
||||
starter model</a>
|
||||
|
||||
We also provide training script in Github to train your own model.
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/recommendation/ml">Training
|
||||
code</a>
|
||||
|
||||
## Understand the model architecture
|
||||
|
||||
We leverage a dual-encoder model architecture, with context-encoder to encode
|
||||
sequential user history and label-encoder to encode predicted recommendation
|
||||
candidate. Similarity between context and label encodings is used to represent
|
||||
the likelihood that the predicted candidate meets the user's needs.
|
||||
|
||||
Three different sequential user history encoding techniques are provided with
|
||||
this code base:
|
||||
|
||||
* Bag-of-words encoder (BOW): averaging user activities' embeddings without
|
||||
considering context order.
|
||||
* Convolutional neural network encoder (CNN): applying multiple layers of
|
||||
convolutional neural networks to generate context encoding.
|
||||
* Recurrent neural network encoder (RNN): applying recurrent neural network to
|
||||
encode context sequence.
|
||||
|
||||
*Note: The model is trained based on
|
||||
[MovieLens](https://grouplens.org/datasets/movielens/1m/) dataset for research
|
||||
purpose.
|
||||
|
||||
## Examples
|
||||
|
||||
Input IDs:
|
||||
|
||||
* Matrix (ID: 260)
|
||||
* Saving Private Ryan (ID: 2028)
|
||||
* (and more)
|
||||
|
||||
Output IDs:
|
||||
|
||||
* Star Wars: Episode VI - Return of the Jedi (ID: 1210)
|
||||
* (and more)
|
||||
|
||||
## Performance benchmarks
|
||||
|
||||
Performance benchmark numbers are generated with the tool
|
||||
[described here](https://www.tensorflow.org/lite/performance/benchmarks).
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Model Name</th>
|
||||
<th>Model Size </th>
|
||||
<th>Device </th>
|
||||
<th>CPU</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tr>
|
||||
<td rowspan = 3>
|
||||
<a href="https://storage.googleapis.com/download.tensorflow.org/models/tflite/recommendation/20200720/model.tar.gz">recommendation</a>
|
||||
</td>
|
||||
<td rowspan = 3>
|
||||
0.52 Mb
|
||||
</td>
|
||||
<td>Pixel 3</td>
|
||||
<td>0.09ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Pixel 4 </td>
|
||||
<td>0.05ms*</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
\* 4 threads used.
|
||||
|
||||
## Use your training data
|
||||
|
||||
In addition to the trained model, we provide an open-sourced
|
||||
[toolkit in GitHub](https://github.com/tensorflow/examples/tree/master/lite/examples/recommendation/ml)
|
||||
to train models with your own data. You can follow this tutorial to learn how to
|
||||
use the toolkit and deploy trained models in your own mobile applications.
|
||||
|
||||
Please follow this
|
||||
[tutorial](https://github.com/tensorflow/examples/tree/master/lite/examples/recommendation/ml/ondevice_recommendation.ipynb)
|
||||
to apply the same technique used here to train a recommendation model using your
|
||||
own datasets.
|
||||
|
||||
## Tips for model customization with your data
|
||||
|
||||
The pretrained model integrated in this demo application is trained with
|
||||
[MovieLens](https://grouplens.org/datasets/movielens/1m/) dataset, you may want
|
||||
to modify model configuration based on your own data, such as vocab size,
|
||||
embedding dims and input context length. Here are a few tips:
|
||||
|
||||
* Input context length: The best input context length varies with datasets. We
|
||||
suggest selecting input context length based on how much label events are
|
||||
correlated with long-term interests vs short-term context.
|
||||
|
||||
* Encoder type selection: we suggest selecting encoder type based on input
|
||||
context length. Bag-of-words encoder works well for short input context
|
||||
length (e.g. <10), CNN and RNN encoders bring in more summarization ability
|
||||
for long input context length.
|
||||
{kind=link}
|
Before Width: | Height: | Size: 298 KiB |
@ -1,116 +0,0 @@
|
||||
# Segmentation
|
||||
|
||||
Image segmentation is the process of partitioning a digital image into multiple
|
||||
segments (sets of pixels, also known as image objects). The goal of segmentation
|
||||
is to simplify and/or change the representation of an image into something that
|
||||
is more meaningful and easier to analyze.
|
||||
|
||||
The following image shows the output of the image segmentation model on Android.
|
||||
The model will create a mask over the target objects with high accuracy.
|
||||
|
||||
<img src="images/segmentation.gif" class="attempt-right" />
|
||||
|
||||
## Get started
|
||||
|
||||
If you are new to TensorFlow Lite and are working with Android or iOS, it is
|
||||
recommended you explore the following example applications that can help you get
|
||||
started.
|
||||
|
||||
You can leverage the out-of-box API from
|
||||
[TensorFlow Lite Task Library](../../inference_with_metadata/task_library/image_segmenter)
|
||||
to integrate image segmentation models within just a few lines of code. You can
|
||||
also integrate the model using the
|
||||
[TensorFlow Lite Interpreter Java API](../../guide/inference#load_and_run_a_model_in_java).
|
||||
|
||||
The Android example below demonstrates the implementation for both methods as
|
||||
[lib_task_api](https://github.com/tensorflow/examples/tree/master/lite/examples/image_segmentation/android/lib_task_api)
|
||||
and
|
||||
[lib_interpreter](https://github.com/tensorflow/examples/tree/master/lite/examples/image_segmentation/android/lib_interpreter),
|
||||
respectively.
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/image_segmentation/android">View
|
||||
Android example</a>
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/image_segmentation/ios">View
|
||||
iOS example</a>
|
||||
|
||||
If you are using a platform other than Android or iOS, or you are already
|
||||
familiar with the
|
||||
<a href="https://www.tensorflow.org/api_docs/python/tf/lite">TensorFlow Lite
|
||||
APIs</a>, you can download our starter image segmentation model.
|
||||
|
||||
<a class="button button-primary" href="https://tfhub.dev/tensorflow/lite-model/deeplabv3/1/metadata/2?lite-format=tflite">Download
|
||||
starter model</a>
|
||||
|
||||
## Model description
|
||||
|
||||
_DeepLab_ is a state-of-art deep learning model for semantic image segmentation,
|
||||
where the goal is to assign semantic labels (e.g. person, dog, cat) to every
|
||||
pixel in the input image.
|
||||
|
||||
### How it works
|
||||
|
||||
Semantic image segmentation predicts whether each pixel of an image is
|
||||
associated with a certain class. This is in contrast to
|
||||
<a href="../object_detection/overview.md">object detection</a>, which detects
|
||||
objects in rectangular regions, and
|
||||
<a href="../image_classification/overview.md">image classification</a>, which
|
||||
classifies the overall image.
|
||||
|
||||
The current implementation includes the following features:
|
||||
<ol>
|
||||
<li>DeepLabv1: We use atrous convolution to explicitly control the resolution at which feature responses are computed within Deep Convolutional Neural Networks.</li>
|
||||
<li>DeepLabv2: We use atrous spatial pyramid pooling (ASPP) to robustly segment objects at multiple scales with filters at multiple sampling rates and effective fields-of-views.</li>
|
||||
<li>DeepLabv3: We augment the ASPP module with image-level feature [5, 6] to capture longer range information. We also include batch normalization [7] parameters to facilitate the training. In particular, we applying atrous convolution to extract output features at different output strides during training and evaluation, which efficiently enables training BN at output stride = 16 and attains a high performance at output stride = 8 during evaluation.</li>
|
||||
<li>DeepLabv3+: We extend DeepLabv3 to include a simple yet effective decoder module to refine the segmentation results especially along object boundaries. Furthermore, in this encoder-decoder structure one can arbitrarily control the resolution of extracted encoder features by atrous convolution to trade-off precision and runtime.</li>
|
||||
</ol>
|
||||
|
||||
## Performance benchmarks
|
||||
|
||||
Performance benchmark numbers are generated with the tool
|
||||
[described here](https://www.tensorflow.org/lite/performance/benchmarks).
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Model Name</th>
|
||||
<th>Model size </th>
|
||||
<th>Device </th>
|
||||
<th>GPU</th>
|
||||
<th>CPU</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tr>
|
||||
<td rowspan = 3>
|
||||
<a href="https://tfhub.dev/tensorflow/lite-model/deeplabv3/1/metadata/2?lite-format=tflite">Deeplab v3</a>
|
||||
</td>
|
||||
<td rowspan = 3>
|
||||
2.7 Mb
|
||||
</td>
|
||||
<td>Pixel 3 (Android 10) </td>
|
||||
<td>16ms</td>
|
||||
<td>37ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Pixel 4 (Android 10) </td>
|
||||
<td>20ms</td>
|
||||
<td>23ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>iPhone XS (iOS 12.4.1) </td>
|
||||
<td>16ms</td>
|
||||
<td>25ms** </td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
\* 4 threads used.
|
||||
|
||||
\*\* 2 threads used on iPhone for the best performance result.
|
||||
|
||||
## Further reading and resources
|
||||
|
||||
<ul>
|
||||
<li><a href="https://ai.googleblog.com/2018/03/semantic-image-segmentation-with.html">Semantic Image Segmentation with DeepLab in TensorFlow</a></li>
|
||||
<li><a href="https://medium.com/tensorflow/tensorflow-lite-now-faster-with-mobile-gpus-developer-preview-e15797e6dee7">TensorFlow Lite Now Faster with Mobile GPUs (Developer Preview)</a></li>
|
||||
<li><a href="https://github.com/tensorflow/models/tree/master/research/deeplab">DeepLab: Deep Labelling for Semantic Image Segmentation</a></li>
|
||||
</ul>
|
||||
{kind=link}
|
Before Width: | Height: | Size: 244 KiB |
@ -1,56 +0,0 @@
|
||||
# Smart reply
|
||||
|
||||
<img src="../images/smart_reply.png" class="attempt-right" />
|
||||
|
||||
## Get started
|
||||
|
||||
Our smart reply model generates reply suggestions based on chat messages. The
|
||||
suggestions are intended to be contextually relevant, one-touch responses that
|
||||
help the user to easily reply to an incoming message.
|
||||
|
||||
<a class="button button-primary" href="https://tfhub.dev/tensorflow/lite-model/smartreply/1/default/1?lite-format=tflite">Download
|
||||
starter model</a>
|
||||
|
||||
### Sample application
|
||||
|
||||
There is a TensorFlow Lite sample application that demonstrates the smart reply
|
||||
model on Android.
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/smart_reply/android">View
|
||||
Android example</a>
|
||||
|
||||
Read the
|
||||
[GitHub page](https://github.com/tensorflow/examples/tree/master/lite/examples/smart_reply/android/)
|
||||
to learn how the app works. Inside this project, you will also learn how to
|
||||
build an app with custom C++ ops.
|
||||
|
||||
## How it works
|
||||
|
||||
The model generates reply suggestions to conversational chat messages.
|
||||
|
||||
The on-device model comes with several benefits. It is:
|
||||
<ul>
|
||||
<li>Fast: The model resides on the device and does not require internet connectivity. Thus, inference is very fast and has an average latency of only a few milliseconds.</li>
|
||||
<li>Resource efficient: The model has a small memory footprint on the device.</li>
|
||||
<li>Privacy-friendly: User data never leaves the device.</li>
|
||||
</ul>
|
||||
|
||||
## Example output
|
||||
|
||||
<img alt="Animation showing smart reply" src="images/smart_reply.gif" style="max-width: 300px"/>
|
||||
|
||||
## Read more about this
|
||||
|
||||
<ul>
|
||||
<li><a href="https://arxiv.org/pdf/1708.00630.pdf">Research paper</a></li>
|
||||
<li><a href="https://github.com/tensorflow/examples/tree/master/lite/examples/smart_reply/android">Source code</a></li>
|
||||
</ul>
|
||||
|
||||
## Users
|
||||
|
||||
<ul>
|
||||
<li><a href="https://www.blog.google/products/gmail/save-time-with-smart-reply-in-gmail/">Gmail</a></li>
|
||||
<li><a href="https://www.blog.google/products/gmail/computer-respond-to-this-email/">Inbox</a></li>
|
||||
<li><a href="https://blog.google/products/allo/google-allo-smarter-messaging-app/">Allo</a></li>
|
||||
<li><a href="https://research.googleblog.com/2017/02/on-device-machine-intelligence.html">Smart Replies on Android Wear</a></li>
|
||||
</ul>
|
||||
@ -1,476 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "g_nWetWWd_ns"
|
||||
},
|
||||
"source": [
|
||||
"##### Copyright 2019 The TensorFlow Authors."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"cellView": "form",
|
||||
"id": "2pHVBk_seED1"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
|
||||
"# you may not use this file except in compliance with the License.\n",
|
||||
"# You may obtain a copy of the License at\n",
|
||||
"#\n",
|
||||
"# https://www.apache.org/licenses/LICENSE-2.0\n",
|
||||
"#\n",
|
||||
"# Unless required by applicable law or agreed to in writing, software\n",
|
||||
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
|
||||
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
|
||||
"# See the License for the specific language governing permissions and\n",
|
||||
"# limitations under the License."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "M7vSdG6sAIQn"
|
||||
},
|
||||
"source": [
|
||||
"# Artistic Style Transfer with TensorFlow Lite"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "fwc5GKHBASdc"
|
||||
},
|
||||
"source": [
|
||||
"\u003ctable class=\"tfo-notebook-buttons\" align=\"left\"\u003e\n",
|
||||
" \u003ctd\u003e\n",
|
||||
" \u003ca target=\"_blank\" href=\"https://www.tensorflow.org/lite/models/style_transfer/overview\"\u003e\u003cimg src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" /\u003eView on TensorFlow.org\u003c/a\u003e\n",
|
||||
" \u003c/td\u003e\n",
|
||||
" \u003ctd\u003e\n",
|
||||
" \u003ca target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/models/style_transfer/overview.ipynb\"\u003e\u003cimg src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /\u003eRun in Google Colab\u003c/a\u003e\n",
|
||||
" \u003c/td\u003e\n",
|
||||
" \u003ctd\u003e\n",
|
||||
" \u003ca target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/models/style_transfer/overview.ipynb\"\u003e\u003cimg src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /\u003eView source on GitHub\u003c/a\u003e\n",
|
||||
" \u003c/td\u003e\n",
|
||||
" \u003ctd\u003e\n",
|
||||
" \u003ca href=\"https://storage.googleapis.com/tensorflow_docs/tensorflow/tensorflow/lite/g3doc/models/style_transfer/overview.ipynb\"\u003e\u003cimg src=\"https://www.tensorflow.org/images/download_logo_32px.png\" /\u003eDownload notebook\u003c/a\u003e\n",
|
||||
" \u003c/td\u003e\n",
|
||||
"\u003c/table\u003e"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "31O0iaROAw8z"
|
||||
},
|
||||
"source": [
|
||||
"One of the most exciting developments in deep learning to come out recently is [artistic style transfer](https://arxiv.org/abs/1508.06576), or the ability to create a new image, known as a [pastiche](https://en.wikipedia.org/wiki/Pastiche), based on two input images: one representing the artistic style and one representing the content.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Using this technique, we can generate beautiful new artworks in a range of styles.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"If you are new to TensorFlow Lite and are working with Android, we\n",
|
||||
"recommend exploring the following example applications that can help you get\n",
|
||||
"started.\n",
|
||||
"\n",
|
||||
"\u003ca class=\"button button-primary\" href=\"https://github.com/tensorflow/examples/tree/master/lite/examples/style_transfer/android\"\u003eAndroid\n",
|
||||
"example\u003c/a\u003e \u003ca class=\"button button-primary\" href=\"https://github.com/tensorflow/examples/tree/master/lite/examples/style_transfer/ios\"\u003eiOS\n",
|
||||
"example\u003c/a\u003e\n",
|
||||
"\n",
|
||||
"If you are using a platform other than Android or iOS, or you are already\n",
|
||||
"familiar with the\n",
|
||||
"\u003ca href=\"https://www.tensorflow.org/api_docs/python/tf/lite\"\u003eTensorFlow Lite\n",
|
||||
"APIs\u003c/a\u003e, you can follow this tutorial to learn how to apply style transfer on any pair of content and style image with a pre-trained TensorFlow Lite model. You can use the model to add style transfer to your own mobile applications.\n",
|
||||
"\n",
|
||||
"The model is open-sourced on [GitHub](https://github.com/tensorflow/magenta/tree/master/magenta/models/arbitrary_image_stylization#train-a-model-on-a-large-dataset-with-data-augmentation-to-run-on-mobile). You can retrain the model with different parameters (e.g. increase content layers' weights to make the output image look more like the content image)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "ak0S4gkOCSxs"
|
||||
},
|
||||
"source": [
|
||||
"## Understand the model architecture"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "oee6G_bBCgAM"
|
||||
},
|
||||
"source": [
|
||||
"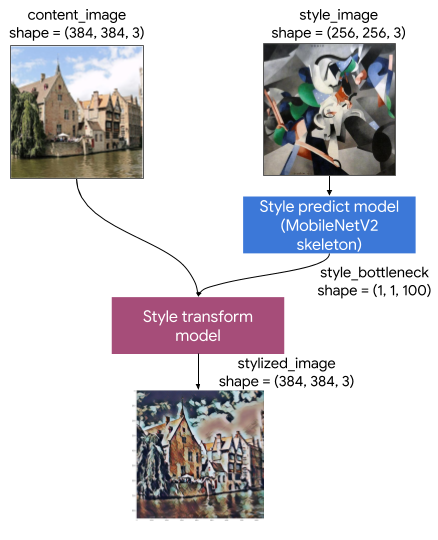\n",
|
||||
"\n",
|
||||
"This Artistic Style Transfer model consists of two submodels:\n",
|
||||
"1. **Style Prediciton Model**: A MobilenetV2-based neural network that takes an input style image to a 100-dimension style bottleneck vector.\n",
|
||||
"1. **Style Transform Model**: A neural network that takes apply a style bottleneck vector to a content image and creates a stylized image.\n",
|
||||
"\n",
|
||||
"If your app only needs to support a fixed set of style images, you can compute their style bottleneck vectors in advance, and exclude the Style Prediction Model from your app's binary."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "a7ZETsRVNMo7"
|
||||
},
|
||||
"source": [
|
||||
"## Setup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "3n8oObKZN4c8"
|
||||
},
|
||||
"source": [
|
||||
"Import dependencies."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "xz62Lb1oNm97"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import tensorflow as tf\n",
|
||||
"print(tf.__version__)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "1Ua5FpcJNrIj"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import IPython.display as display\n",
|
||||
"\n",
|
||||
"import matplotlib.pyplot as plt\n",
|
||||
"import matplotlib as mpl\n",
|
||||
"mpl.rcParams['figure.figsize'] = (12,12)\n",
|
||||
"mpl.rcParams['axes.grid'] = False\n",
|
||||
"\n",
|
||||
"import numpy as np\n",
|
||||
"import time\n",
|
||||
"import functools"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "1b988wrrQnVF"
|
||||
},
|
||||
"source": [
|
||||
"Download the content and style images, and the pre-trained TensorFlow Lite models."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "16g57cIMQnen"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"content_path = tf.keras.utils.get_file('belfry.jpg','https://storage.googleapis.com/khanhlvg-public.appspot.com/arbitrary-style-transfer/belfry-2611573_1280.jpg')\n",
|
||||
"style_path = tf.keras.utils.get_file('style23.jpg','https://storage.googleapis.com/khanhlvg-public.appspot.com/arbitrary-style-transfer/style23.jpg')\n",
|
||||
"\n",
|
||||
"style_predict_path = tf.keras.utils.get_file('style_predict.tflite', 'https://tfhub.dev/google/lite-model/magenta/arbitrary-image-stylization-v1-256/int8/prediction/1?lite-format=tflite')\n",
|
||||
"style_transform_path = tf.keras.utils.get_file('style_transform.tflite', 'https://tfhub.dev/google/lite-model/magenta/arbitrary-image-stylization-v1-256/int8/transfer/1?lite-format=tflite')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "MQZXL7kON-gM"
|
||||
},
|
||||
"source": [
|
||||
"## Pre-process the inputs\n",
|
||||
"\n",
|
||||
"* The content image and the style image must be RGB images with pixel values being float32 numbers between [0..1].\n",
|
||||
"* The style image size must be (1, 256, 256, 3). We central crop the image and resize it.\n",
|
||||
"* The content image must be (1, 384, 384, 3). We central crop the image and resize it."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "Cg0Vi-rXRUFl"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Function to load an image from a file, and add a batch dimension.\n",
|
||||
"def load_img(path_to_img):\n",
|
||||
" img = tf.io.read_file(path_to_img)\n",
|
||||
" img = tf.io.decode_image(img, channels=3)\n",
|
||||
" img = tf.image.convert_image_dtype(img, tf.float32)\n",
|
||||
" img = img[tf.newaxis, :]\n",
|
||||
"\n",
|
||||
" return img\n",
|
||||
"\n",
|
||||
"# Function to pre-process by resizing an central cropping it.\n",
|
||||
"def preprocess_image(image, target_dim):\n",
|
||||
" # Resize the image so that the shorter dimension becomes 256px.\n",
|
||||
" shape = tf.cast(tf.shape(image)[1:-1], tf.float32)\n",
|
||||
" short_dim = min(shape)\n",
|
||||
" scale = target_dim / short_dim\n",
|
||||
" new_shape = tf.cast(shape * scale, tf.int32)\n",
|
||||
" image = tf.image.resize(image, new_shape)\n",
|
||||
"\n",
|
||||
" # Central crop the image.\n",
|
||||
" image = tf.image.resize_with_crop_or_pad(image, target_dim, target_dim)\n",
|
||||
"\n",
|
||||
" return image\n",
|
||||
"\n",
|
||||
"# Load the input images.\n",
|
||||
"content_image = load_img(content_path)\n",
|
||||
"style_image = load_img(style_path)\n",
|
||||
"\n",
|
||||
"# Preprocess the input images.\n",
|
||||
"preprocessed_content_image = preprocess_image(content_image, 384)\n",
|
||||
"preprocessed_style_image = preprocess_image(style_image, 256)\n",
|
||||
"\n",
|
||||
"print('Style Image Shape:', preprocessed_style_image.shape)\n",
|
||||
"print('Content Image Shape:', preprocessed_content_image.shape)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "xE4Yt8nArTeR"
|
||||
},
|
||||
"source": [
|
||||
"## Visualize the inputs"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "ncPA4esJRcEu"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def imshow(image, title=None):\n",
|
||||
" if len(image.shape) \u003e 3:\n",
|
||||
" image = tf.squeeze(image, axis=0)\n",
|
||||
"\n",
|
||||
" plt.imshow(image)\n",
|
||||
" if title:\n",
|
||||
" plt.title(title)\n",
|
||||
"\n",
|
||||
"plt.subplot(1, 2, 1)\n",
|
||||
"imshow(preprocessed_content_image, 'Content Image')\n",
|
||||
"\n",
|
||||
"plt.subplot(1, 2, 2)\n",
|
||||
"imshow(preprocessed_style_image, 'Style Image')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "CJ7R-CHbjC3s"
|
||||
},
|
||||
"source": [
|
||||
"## Run style transfer with TensorFlow Lite"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "euu00ldHjKwD"
|
||||
},
|
||||
"source": [
|
||||
"### Style prediction"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "o3zd9cTFRiS_"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Function to run style prediction on preprocessed style image.\n",
|
||||
"def run_style_predict(preprocessed_style_image):\n",
|
||||
" # Load the model.\n",
|
||||
" interpreter = tf.lite.Interpreter(model_path=style_predict_path)\n",
|
||||
"\n",
|
||||
" # Set model input.\n",
|
||||
" interpreter.allocate_tensors()\n",
|
||||
" input_details = interpreter.get_input_details()\n",
|
||||
" interpreter.set_tensor(input_details[0][\"index\"], preprocessed_style_image)\n",
|
||||
"\n",
|
||||
" # Calculate style bottleneck.\n",
|
||||
" interpreter.invoke()\n",
|
||||
" style_bottleneck = interpreter.tensor(\n",
|
||||
" interpreter.get_output_details()[0][\"index\"]\n",
|
||||
" )()\n",
|
||||
"\n",
|
||||
" return style_bottleneck\n",
|
||||
"\n",
|
||||
"# Calculate style bottleneck for the preprocessed style image.\n",
|
||||
"style_bottleneck = run_style_predict(preprocessed_style_image)\n",
|
||||
"print('Style Bottleneck Shape:', style_bottleneck.shape)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "00t8S2PekIyW"
|
||||
},
|
||||
"source": [
|
||||
"### Style transform"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "cZp5bCj8SX1w"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Run style transform on preprocessed style image\n",
|
||||
"def run_style_transform(style_bottleneck, preprocessed_content_image):\n",
|
||||
" # Load the model.\n",
|
||||
" interpreter = tf.lite.Interpreter(model_path=style_transform_path)\n",
|
||||
"\n",
|
||||
" # Set model input.\n",
|
||||
" input_details = interpreter.get_input_details()\n",
|
||||
" interpreter.allocate_tensors()\n",
|
||||
"\n",
|
||||
" # Set model inputs.\n",
|
||||
" interpreter.set_tensor(input_details[0][\"index\"], preprocessed_content_image)\n",
|
||||
" interpreter.set_tensor(input_details[1][\"index\"], style_bottleneck)\n",
|
||||
" interpreter.invoke()\n",
|
||||
"\n",
|
||||
" # Transform content image.\n",
|
||||
" stylized_image = interpreter.tensor(\n",
|
||||
" interpreter.get_output_details()[0][\"index\"]\n",
|
||||
" )()\n",
|
||||
"\n",
|
||||
" return stylized_image\n",
|
||||
"\n",
|
||||
"# Stylize the content image using the style bottleneck.\n",
|
||||
"stylized_image = run_style_transform(style_bottleneck, preprocessed_content_image)\n",
|
||||
"\n",
|
||||
"# Visualize the output.\n",
|
||||
"imshow(stylized_image, 'Stylized Image')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "vv_71Td-QtrW"
|
||||
},
|
||||
"source": [
|
||||
"### Style blending\n",
|
||||
"\n",
|
||||
"We can blend the style of content image into the stylized output, which in turn making the output look more like the content image."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "eJcAURXQQtJ7"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Calculate style bottleneck of the content image.\n",
|
||||
"style_bottleneck_content = run_style_predict(\n",
|
||||
" preprocess_image(content_image, 256)\n",
|
||||
" )"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "4S3yg2MgkmRD"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Define content blending ratio between [0..1].\n",
|
||||
"# 0.0: 0% style extracts from content image.\n",
|
||||
"# 1.0: 100% style extracted from content image.\n",
|
||||
"content_blending_ratio = 0.5 #@param {type:\"slider\", min:0, max:1, step:0.01}\n",
|
||||
"\n",
|
||||
"# Blend the style bottleneck of style image and content image\n",
|
||||
"style_bottleneck_blended = content_blending_ratio * style_bottleneck_content \\\n",
|
||||
" + (1 - content_blending_ratio) * style_bottleneck\n",
|
||||
"\n",
|
||||
"# Stylize the content image using the style bottleneck.\n",
|
||||
"stylized_image_blended = run_style_transform(style_bottleneck_blended,\n",
|
||||
" preprocessed_content_image)\n",
|
||||
"\n",
|
||||
"# Visualize the output.\n",
|
||||
"imshow(stylized_image_blended, 'Blended Stylized Image')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "9k9jGIep8p1c"
|
||||
},
|
||||
"source": [
|
||||
"## Performance Benchmarks\n",
|
||||
"\n",
|
||||
"Performance benchmark numbers are generated with the tool [described here](https://www.tensorflow.org/lite/performance/benchmarks).\n",
|
||||
"\u003ctable \u003e\u003cthead\u003e\u003ctr\u003e\u003cth\u003eModel name\u003c/th\u003e \u003cth\u003eModel size\u003c/th\u003e \u003cth\u003eDevice \u003c/th\u003e \u003cth\u003eNNAPI\u003c/th\u003e \u003cth\u003eCPU\u003c/th\u003e \u003cth\u003eGPU\u003c/th\u003e\u003c/tr\u003e \u003c/thead\u003e \n",
|
||||
"\u003ctr\u003e \u003ctd rowspan = 3\u003e \u003ca href=\"https://tfhub.dev/google/lite-model/magenta/arbitrary-image-stylization-v1-256/int8/prediction/1?lite-format=tflite\"\u003eStyle prediction model (int8)\u003c/a\u003e \u003c/td\u003e \n",
|
||||
"\u003ctd rowspan = 3\u003e2.8 Mb\u003c/td\u003e\n",
|
||||
"\u003ctd\u003ePixel 3 (Android 10) \u003c/td\u003e \u003ctd\u003e142ms\u003c/td\u003e\u003ctd\u003e14ms*\u003c/td\u003e\u003ctd\u003e\u003c/td\u003e\u003c/tr\u003e\n",
|
||||
"\u003ctr\u003e\u003ctd\u003ePixel 4 (Android 10) \u003c/td\u003e \u003ctd\u003e5.2ms\u003c/td\u003e\u003ctd\u003e6.7ms*\u003c/td\u003e\u003ctd\u003e\u003c/td\u003e\u003c/tr\u003e\n",
|
||||
"\u003ctr\u003e\u003ctd\u003eiPhone XS (iOS 12.4.1) \u003c/td\u003e \u003ctd\u003e\u003c/td\u003e\u003ctd\u003e10.7ms**\u003c/td\u003e\u003ctd\u003e\u003c/td\u003e\u003c/tr\u003e\n",
|
||||
"\u003ctr\u003e \u003ctd rowspan = 3\u003e \u003ca href=\"https://tfhub.dev/google/lite-model/magenta/arbitrary-image-stylization-v1-256/int8/transfer/1?lite-format=tflite\"\u003eStyle transform model (int8)\u003c/a\u003e \u003c/td\u003e \n",
|
||||
"\u003ctd rowspan = 3\u003e0.2 Mb\u003c/td\u003e\n",
|
||||
"\u003ctd\u003ePixel 3 (Android 10) \u003c/td\u003e \u003ctd\u003e\u003c/td\u003e\u003ctd\u003e540ms*\u003c/td\u003e\u003ctd\u003e\u003c/td\u003e\u003c/tr\u003e\n",
|
||||
"\u003ctr\u003e\u003ctd\u003ePixel 4 (Android 10) \u003c/td\u003e \u003ctd\u003e\u003c/td\u003e\u003ctd\u003e405ms*\u003c/td\u003e\u003ctd\u003e\u003c/td\u003e\u003c/tr\u003e\n",
|
||||
"\u003ctr\u003e\u003ctd\u003eiPhone XS (iOS 12.4.1) \u003c/td\u003e \u003ctd\u003e\u003c/td\u003e\u003ctd\u003e251ms**\u003c/td\u003e\u003ctd\u003e\u003c/td\u003e\u003c/tr\u003e\n",
|
||||
"\n",
|
||||
"\u003ctr\u003e \u003ctd rowspan = 2\u003e \u003ca href=\"https://tfhub.dev/google/lite-model/magenta/arbitrary-image-stylization-v1-256/fp16/prediction/1?lite-format=tflite\"\u003eStyle prediction model (float16)\u003c/a\u003e \u003c/td\u003e \n",
|
||||
"\u003ctd rowspan = 2\u003e4.7 Mb\u003c/td\u003e\n",
|
||||
"\u003ctd\u003ePixel 3 (Android 10) \u003c/td\u003e \u003ctd\u003e86ms\u003c/td\u003e\u003ctd\u003e28ms*\u003c/td\u003e\u003ctd\u003e9.1ms\u003c/td\u003e\u003c/tr\u003e\n",
|
||||
"\u003ctr\u003e\u003ctd\u003ePixel 4 (Android 10) \u003c/td\u003e\u003ctd\u003e32ms\u003c/td\u003e\u003ctd\u003e12ms*\u003c/td\u003e\u003ctd\u003e10ms\u003c/td\u003e\u003c/tr\u003e\n",
|
||||
"\n",
|
||||
"\u003ctr\u003e \u003ctd rowspan = 2\u003e \u003ca href=\"https://tfhub.dev/google/lite-model/magenta/arbitrary-image-stylization-v1-256/fp16/transfer/1?lite-format=tflite\"\u003eStyle transfer model (float16)\u003c/a\u003e \u003c/td\u003e \n",
|
||||
"\u003ctd rowspan = 2\u003e0.4 Mb\u003c/td\u003e\n",
|
||||
"\u003ctd\u003ePixel 3 (Android 10) \u003c/td\u003e \u003ctd\u003e1095ms\u003c/td\u003e\u003ctd\u003e545ms*\u003c/td\u003e\u003ctd\u003e42ms\u003c/td\u003e\u003c/tr\u003e\n",
|
||||
"\u003ctr\u003e\u003ctd\u003ePixel 4 (Android 10) \u003c/td\u003e\u003ctd\u003e603ms\u003c/td\u003e\u003ctd\u003e377ms*\u003c/td\u003e\u003ctd\u003e42ms\u003c/td\u003e\u003c/tr\u003e\n",
|
||||
"\n",
|
||||
"\u003c/table\u003e\n",
|
||||
"\n",
|
||||
"*\u0026ast; 4 threads used. \u003cbr/\u003e*\n",
|
||||
"*\u0026ast;\u0026ast; 2 threads on iPhone for the best performance.*\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"colab": {
|
||||
"collapsed_sections": [],
|
||||
"name": "overview.ipynb",
|
||||
"toc_visible": true
|
||||
},
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"name": "python3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 0
|
||||
}
|
||||
@ -1,345 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "JfOIB1KdkbYW"
|
||||
},
|
||||
"source": [
|
||||
"##### Copyright 2020 The TensorFlow Authors."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"cellView": "form",
|
||||
"id": "Ojb0aXCmBgo7"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
|
||||
"# you may not use this file except in compliance with the License.\n",
|
||||
"# You may obtain a copy of the License at\n",
|
||||
"#\n",
|
||||
"# https://www.apache.org/licenses/LICENSE-2.0\n",
|
||||
"#\n",
|
||||
"# Unless required by applicable law or agreed to in writing, software\n",
|
||||
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
|
||||
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
|
||||
"# See the License for the specific language governing permissions and\n",
|
||||
"# limitations under the License."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "M9Y4JZ0ZGoE4"
|
||||
},
|
||||
"source": [
|
||||
"# Super resolution with TensorFlow Lite"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n",
|
||||
" <td>\n",
|
||||
" <a target=\"_blank\" href=\"https://www.tensorflow.org/lite/models/super_resolution/overview\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n",
|
||||
" </td>\n",
|
||||
" <td>\n",
|
||||
" <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/models/super_resolution/overview.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n",
|
||||
" </td>\n",
|
||||
" <td>\n",
|
||||
" <a target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/models/super_resolution/overview.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n",
|
||||
" </td>\n",
|
||||
" <td>\n",
|
||||
" <a href=\"https://storage.googleapis.com/tensorflow_docs/tensorflow/tensorflow/lite/g3doc/models/super_resolution/overview.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />Download notebook</a>\n",
|
||||
" </td>\n",
|
||||
" <td>\n",
|
||||
" <a href=\"https://tfhub.dev/captain-pool/esrgan-tf2/1\"><img src=\"https://www.tensorflow.org/images/hub_logo_32px.png\" />See TF Hub model</a>\n",
|
||||
" </td>\n",
|
||||
"</table>"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "-uF3N4BbaMvA"
|
||||
},
|
||||
"source": [
|
||||
"## Overview"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "isbXET4vVHfu"
|
||||
},
|
||||
"source": [
|
||||
"The task of recovering a high resolution (HR) image from its low resolution counterpart is commonly referred to as Single Image Super Resolution (SISR). \n",
|
||||
"\n",
|
||||
"The model used here is ESRGAN\n",
|
||||
"([ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks](https://arxiv.org/abs/1809.00219)). And we are going to use TensorFlow Lite to run inference on the pretrained model.\n",
|
||||
"\n",
|
||||
"The TFLite model is converted from this\n",
|
||||
"[implementation](https://tfhub.dev/captain-pool/esrgan-tf2/1) hosted on TF Hub. Note that the model we converted upsamples a 50x50 low resolution image to a 200x200 high resolution image (scale factor=4). If you want a different input size or scale factor, you need to re-convert or re-train the original model."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "2dQlTqiffuoU"
|
||||
},
|
||||
"source": [
|
||||
"## Setup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "qKyMtsGqu3zH"
|
||||
},
|
||||
"source": [
|
||||
"Let's install required libraries first."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "7YTT1Rxsw3A9"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install matplotlib tensorflow tensorflow-hub"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "Clz5Kl97FswD"
|
||||
},
|
||||
"source": [
|
||||
"Import dependencies."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "2xh1kvGEBjuP"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import tensorflow as tf\n",
|
||||
"import tensorflow_hub as hub\n",
|
||||
"import matplotlib.pyplot as plt\n",
|
||||
"print(tf.__version__)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "i5miVfL4kxTA"
|
||||
},
|
||||
"source": [
|
||||
"Download and convert the ESRGAN model"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "X5PvXIXRwvHj"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"model = hub.load(\"https://tfhub.dev/captain-pool/esrgan-tf2/1\")\n",
|
||||
"concrete_func = model.signatures[tf.saved_model.DEFAULT_SERVING_SIGNATURE_DEF_KEY]\n",
|
||||
"concrete_func.inputs[0].set_shape([1, 50, 50, 3])\n",
|
||||
"converter = tf.lite.TFLiteConverter.from_concrete_functions([concrete_func])\n",
|
||||
"converter.optimizations = [tf.lite.Optimize.DEFAULT]\n",
|
||||
"tflite_model = converter.convert()\n",
|
||||
"\n",
|
||||
"# Save the TF Lite model.\n",
|
||||
"with tf.io.gfile.GFile('ESRGAN.tflite', 'wb') as f:\n",
|
||||
" f.write(tflite_model)\n",
|
||||
"\n",
|
||||
"esrgan_model_path = './ESRGAN.tflite'"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "jH5-xPkyUEqt"
|
||||
},
|
||||
"source": [
|
||||
"Download a test image (insect head)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "suWiStTWgK6e"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"test_img_path = tf.keras.utils.get_file('lr.jpg', 'https://raw.githubusercontent.com/tensorflow/examples/master/lite/examples/super_resolution/android/app/src/main/assets/lr-1.jpg')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "rgQ4qRuFNpyW"
|
||||
},
|
||||
"source": [
|
||||
"## Generate a super resolution image using TensorFlow Lite"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "J9FV4btf02-2"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"lr = tf.io.read_file(test_img_path)\n",
|
||||
"lr = tf.image.decode_jpeg(lr)\n",
|
||||
"lr = tf.expand_dims(lr, axis=0)\n",
|
||||
"lr = tf.cast(lr, tf.float32)\n",
|
||||
"\n",
|
||||
"# Load TFLite model and allocate tensors.\n",
|
||||
"interpreter = tf.lite.Interpreter(model_path=esrgan_model_path)\n",
|
||||
"interpreter.allocate_tensors()\n",
|
||||
"\n",
|
||||
"# Get input and output tensors.\n",
|
||||
"input_details = interpreter.get_input_details()\n",
|
||||
"output_details = interpreter.get_output_details()\n",
|
||||
"\n",
|
||||
"# Run the model\n",
|
||||
"interpreter.set_tensor(input_details[0]['index'], lr)\n",
|
||||
"interpreter.invoke()\n",
|
||||
"\n",
|
||||
"# Extract the output and postprocess it\n",
|
||||
"output_data = interpreter.get_tensor(output_details[0]['index'])\n",
|
||||
"sr = tf.squeeze(output_data, axis=0)\n",
|
||||
"sr = tf.clip_by_value(sr, 0, 255)\n",
|
||||
"sr = tf.round(sr)\n",
|
||||
"sr = tf.cast(sr, tf.uint8)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "EwddQrDUNQGO"
|
||||
},
|
||||
"source": [
|
||||
"## Visualize the result"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "aasKuozt1gNd"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"lr = tf.cast(tf.squeeze(lr, axis=0), tf.uint8)\n",
|
||||
"plt.figure(figsize = (1, 1))\n",
|
||||
"plt.title('LR')\n",
|
||||
"plt.imshow(lr.numpy());\n",
|
||||
"\n",
|
||||
"plt.figure(figsize=(10, 4))\n",
|
||||
"plt.subplot(1, 2, 1) \n",
|
||||
"plt.title(f'ESRGAN (x4)')\n",
|
||||
"plt.imshow(sr.numpy());\n",
|
||||
"\n",
|
||||
"bicubic = tf.image.resize(lr, [200, 200], tf.image.ResizeMethod.BICUBIC)\n",
|
||||
"bicubic = tf.cast(bicubic, tf.uint8)\n",
|
||||
"plt.subplot(1, 2, 2) \n",
|
||||
"plt.title('Bicubic')\n",
|
||||
"plt.imshow(bicubic.numpy());"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "0kb-fkogObjq"
|
||||
},
|
||||
"source": [
|
||||
"## Performance Benchmarks"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "tNzdgpqTy5P3"
|
||||
},
|
||||
"source": [
|
||||
"Performance benchmark numbers are generated with the tool\n",
|
||||
"[described here](https://www.tensorflow.org/lite/performance/benchmarks).\n",
|
||||
"\n",
|
||||
"<table>\n",
|
||||
" <thead>\n",
|
||||
" <tr>\n",
|
||||
" <th>Model Name</th>\n",
|
||||
" <th>Model Size </th>\n",
|
||||
" <th>Device </th>\n",
|
||||
" <th>CPU</th>\n",
|
||||
" <th>GPU</th>\n",
|
||||
" </tr>\n",
|
||||
" </thead>\n",
|
||||
" <tr>\n",
|
||||
" <td rowspan = 3>\n",
|
||||
" super resolution (ESRGAN)\n",
|
||||
" </td>\n",
|
||||
" <td rowspan = 3>\n",
|
||||
" 4.8 Mb\n",
|
||||
" </td>\n",
|
||||
" <td>Pixel 3</td>\n",
|
||||
" <td>586.8ms*</td>\n",
|
||||
" <td>128.6ms</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <td>Pixel 4</td>\n",
|
||||
" <td>385.1ms*</td>\n",
|
||||
" <td>130.3ms</td>\n",
|
||||
" </tr>\n",
|
||||
"\n",
|
||||
"</table>\n",
|
||||
"\n",
|
||||
"**4 threads used*"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"colab": {
|
||||
"name": "super_resolution.ipynb",
|
||||
"toc_visible": true
|
||||
},
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.7.4"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 1
|
||||
}
|
||||
{kind=link}
|
Before Width: | Height: | Size: 188 KiB |
@ -1,113 +0,0 @@
|
||||
# Text classification
|
||||
|
||||
Use a pre-trained model to category a paragraph into predefined groups.
|
||||
|
||||
## Get started
|
||||
|
||||
<img src="images/screenshot.gif" class="attempt-right" style="max-width: 300px">
|
||||
|
||||
If you are new to TensorFlow Lite and are working with Android, we recommend
|
||||
exploring the guide of
|
||||
[TensorFLow Lite Task Library](../../inference_with_metadata/task_library/nl_classifier)
|
||||
to integrate text classification models within just a few lines of code. You can
|
||||
also integrate the model using the
|
||||
[TensorFlow Lite Interpreter Java API](../../guide/inference#load_and_run_a_model_in_java).
|
||||
|
||||
The Android example below demonstrates the implementation for both methods as
|
||||
[lib_task_api](https://github.com/tensorflow/examples/tree/master/lite/examples/text_classification/android/lib_task_api)
|
||||
and
|
||||
[lib_interpreter](https://github.com/tensorflow/examples/tree/master/lite/examples/text_classification/android/lib_interpreter),
|
||||
respectively.
|
||||
|
||||
<a class="button button-primary" href="https://github.com/tensorflow/examples/tree/master/lite/examples/text_classification/android">Android
|
||||
example</a>
|
||||
|
||||
If you are using a platform other than Android, or you are already familiar with
|
||||
the TensorFlow Lite APIs, you can download our starter text classification
|
||||
model.
|
||||
|
||||
<a class="button button-primary" href="https://storage.googleapis.com/download.tensorflow.org/models/tflite/text_classification/text_classification_v2.tflite">Download
|
||||
starter model</a>
|
||||
|
||||
## How it works
|
||||
|
||||
Text classification categorizes a paragraph into predefined groups based on its
|
||||
content.
|
||||
|
||||
This pretrained model predicts if a paragraph's sentiment is positive or
|
||||
negative. It was trained on
|
||||
[Large Movie Review Dataset v1.0](http://ai.stanford.edu/~amaas/data/sentiment/)
|
||||
from Mass et al, which consists of IMDB movie reviews labeled as either positive
|
||||
or negative.
|
||||
|
||||
Here are the steps to classify a paragraph with the model:
|
||||
|
||||
1. Tokenize the paragraph and convert it to a list of word ids using a
|
||||
predefined vocabulary.
|
||||
1. Feed the list to the TensorFlow Lite model.
|
||||
1. Get the probability of the paragraph being positive or negative from the
|
||||
model outputs.
|
||||
|
||||
### Note
|
||||
|
||||
* Only English is supported.
|
||||
* This model was trained on movie reviews dataset so you may experience
|
||||
reduced accuracy when classifying text of other domains.
|
||||
|
||||
## Performance benchmarks
|
||||
|
||||
Performance benchmark numbers are generated with the tool
|
||||
[described here](https://www.tensorflow.org/lite/performance/benchmarks).
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Model Name</th>
|
||||
<th>Model size </th>
|
||||
<th>Device </th>
|
||||
<th>CPU</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tr>
|
||||
<td rowspan = 3>
|
||||
<a href="https://storage.googleapis.com/download.tensorflow.org/models/tflite/text_classification/text_classification_v2.tflite">Text Classification</a>
|
||||
</td>
|
||||
<td rowspan = 3>
|
||||
0.6 Mb
|
||||
</td>
|
||||
<td>Pixel 3 (Android 10) </td>
|
||||
<td>0.05ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Pixel 4 (Android 10) </td>
|
||||
<td>0.05ms*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>iPhone XS (iOS 12.4.1) </td>
|
||||
<td>0.025ms** </td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
\* 4 threads used.
|
||||
|
||||
\*\* 2 threads used on iPhone for the best performance result.
|
||||
|
||||
## Example output
|
||||
|
||||
| Text | Negative (0) | Positive (1) |
|
||||
| ------------------------------------------ | ------------ | ------------ |
|
||||
| This is the best movie I’ve seen in recent | 25.3% | 74.7% |
|
||||
: years. Strongly recommend it! : : :
|
||||
| What a waste of my time. | 72.5% | 27.5% |
|
||||
|
||||
## Use your training dataset
|
||||
|
||||
Follow this
|
||||
[tutorial](https://github.com/tensorflow/examples/tree/master/tensorflow_examples/lite/model_maker/demo/text_classification.ipynb)
|
||||
to apply the same technique used here to train a text classification model using
|
||||
your own datasets. With the right dataset, you can create a model for use cases
|
||||
such as document categorization or toxic comments detection.
|
||||
|
||||
## Read more about text classification
|
||||
|
||||
* [Word embeddings and tutorial to train this model](https://www.tensorflow.org/tutorials/text/word_embeddings)
|
||||