diff --git a/tensorflow/go/op/wrappers.go b/tensorflow/go/op/wrappers.go
index ae8deb7cf04..6f5e1518d1c 100644
--- a/tensorflow/go/op/wrappers.go
+++ b/tensorflow/go/op/wrappers.go
@@ -98,61 +98,6 @@ func FakeQuantWithMinMaxVarsPerChannel(scope *Scope, inputs tf.Output, min tf.Ou
return op.Output(0)
}
-// FakeQuantWithMinMaxVarsGradientAttr is an optional argument to FakeQuantWithMinMaxVarsGradient.
-type FakeQuantWithMinMaxVarsGradientAttr func(optionalAttr)
-
-// FakeQuantWithMinMaxVarsGradientNumBits sets the optional num_bits attribute to value.
-//
-// value: The bitwidth of the quantization; between 2 and 8, inclusive.
-// If not specified, defaults to 8
-func FakeQuantWithMinMaxVarsGradientNumBits(value int64) FakeQuantWithMinMaxVarsGradientAttr {
- return func(m optionalAttr) {
- m["num_bits"] = value
- }
-}
-
-// FakeQuantWithMinMaxVarsGradientNarrowRange sets the optional narrow_range attribute to value.
-//
-// value: Whether to quantize into 2^num_bits - 1 distinct values.
-// If not specified, defaults to false
-func FakeQuantWithMinMaxVarsGradientNarrowRange(value bool) FakeQuantWithMinMaxVarsGradientAttr {
- return func(m optionalAttr) {
- m["narrow_range"] = value
- }
-}
-
-// Compute gradients for a FakeQuantWithMinMaxVars operation.
-//
-// Arguments:
-// gradients: Backpropagated gradients above the FakeQuantWithMinMaxVars operation.
-// inputs: Values passed as inputs to the FakeQuantWithMinMaxVars operation.
-// min, max: Quantization interval, scalar floats.
-//
-//
-//
-// Returns Backpropagated gradients w.r.t. inputs:
-// `gradients * (inputs >= min && inputs <= max)`.Backpropagated gradients w.r.t. min parameter:
-// `sum(gradients * (inputs < min))`.Backpropagated gradients w.r.t. max parameter:
-// `sum(gradients * (inputs > max))`.
-func FakeQuantWithMinMaxVarsGradient(scope *Scope, gradients tf.Output, inputs tf.Output, min tf.Output, max tf.Output, optional ...FakeQuantWithMinMaxVarsGradientAttr) (backprops_wrt_input tf.Output, backprop_wrt_min tf.Output, backprop_wrt_max tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "FakeQuantWithMinMaxVarsGradient",
- Input: []tf.Input{
- gradients, inputs, min, max,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1), op.Output(2)
-}
-
// FakeQuantWithMinMaxVarsAttr is an optional argument to FakeQuantWithMinMaxVars.
type FakeQuantWithMinMaxVarsAttr func(optionalAttr)
@@ -212,50 +157,60 @@ func FakeQuantWithMinMaxVars(scope *Scope, inputs tf.Output, min tf.Output, max
return op.Output(0)
}
-// FakeQuantWithMinMaxArgsGradientAttr is an optional argument to FakeQuantWithMinMaxArgsGradient.
-type FakeQuantWithMinMaxArgsGradientAttr func(optionalAttr)
+// FakeQuantWithMinMaxArgsAttr is an optional argument to FakeQuantWithMinMaxArgs.
+type FakeQuantWithMinMaxArgsAttr func(optionalAttr)
-// FakeQuantWithMinMaxArgsGradientMin sets the optional min attribute to value.
+// FakeQuantWithMinMaxArgsMin sets the optional min attribute to value.
// If not specified, defaults to -6
-func FakeQuantWithMinMaxArgsGradientMin(value float32) FakeQuantWithMinMaxArgsGradientAttr {
+func FakeQuantWithMinMaxArgsMin(value float32) FakeQuantWithMinMaxArgsAttr {
return func(m optionalAttr) {
m["min"] = value
}
}
-// FakeQuantWithMinMaxArgsGradientMax sets the optional max attribute to value.
+// FakeQuantWithMinMaxArgsMax sets the optional max attribute to value.
// If not specified, defaults to 6
-func FakeQuantWithMinMaxArgsGradientMax(value float32) FakeQuantWithMinMaxArgsGradientAttr {
+func FakeQuantWithMinMaxArgsMax(value float32) FakeQuantWithMinMaxArgsAttr {
return func(m optionalAttr) {
m["max"] = value
}
}
-// FakeQuantWithMinMaxArgsGradientNumBits sets the optional num_bits attribute to value.
+// FakeQuantWithMinMaxArgsNumBits sets the optional num_bits attribute to value.
// If not specified, defaults to 8
-func FakeQuantWithMinMaxArgsGradientNumBits(value int64) FakeQuantWithMinMaxArgsGradientAttr {
+func FakeQuantWithMinMaxArgsNumBits(value int64) FakeQuantWithMinMaxArgsAttr {
return func(m optionalAttr) {
m["num_bits"] = value
}
}
-// FakeQuantWithMinMaxArgsGradientNarrowRange sets the optional narrow_range attribute to value.
+// FakeQuantWithMinMaxArgsNarrowRange sets the optional narrow_range attribute to value.
// If not specified, defaults to false
-func FakeQuantWithMinMaxArgsGradientNarrowRange(value bool) FakeQuantWithMinMaxArgsGradientAttr {
+func FakeQuantWithMinMaxArgsNarrowRange(value bool) FakeQuantWithMinMaxArgsAttr {
return func(m optionalAttr) {
m["narrow_range"] = value
}
}
-// Compute gradients for a FakeQuantWithMinMaxArgs operation.
+// Fake-quantize the 'inputs' tensor, type float to 'outputs' tensor of same type.
//
-// Arguments:
-// gradients: Backpropagated gradients above the FakeQuantWithMinMaxArgs operation.
-// inputs: Values passed as inputs to the FakeQuantWithMinMaxArgs operation.
+// Attributes `[min; max]` define the clamping range for the `inputs` data.
+// `inputs` values are quantized into the quantization range (`[0; 2^num_bits - 1]`
+// when `narrow_range` is false and `[1; 2^num_bits - 1]` when it is true) and
+// then de-quantized and output as floats in `[min; max]` interval.
+// `num_bits` is the bitwidth of the quantization; between 2 and 16, inclusive.
//
-// Returns Backpropagated gradients below the FakeQuantWithMinMaxArgs operation:
-// `gradients * (inputs >= min && inputs <= max)`.
-func FakeQuantWithMinMaxArgsGradient(scope *Scope, gradients tf.Output, inputs tf.Output, optional ...FakeQuantWithMinMaxArgsGradientAttr) (backprops tf.Output) {
+// Before quantization, `min` and `max` values are adjusted with the following
+// logic.
+// It is suggested to have `min <= 0 <= max`. If `0` is not in the range of values,
+// the behavior can be unexpected:
+// If `0 < min < max`: `min_adj = 0` and `max_adj = max - min`.
+// If `min < max < 0`: `min_adj = min - max` and `max_adj = 0`.
+// If `min <= 0 <= max`: `scale = (max - min) / (2^num_bits - 1) `,
+// `min_adj = scale * round(min / scale)` and `max_adj = max + min_adj - min`.
+//
+// Quantization is called fake since the output is still in floating point.
+func FakeQuantWithMinMaxArgs(scope *Scope, inputs tf.Output, optional ...FakeQuantWithMinMaxArgsAttr) (outputs tf.Output) {
if scope.Err() != nil {
return
}
@@ -264,9 +219,9 @@ func FakeQuantWithMinMaxArgsGradient(scope *Scope, gradients tf.Output, inputs t
a(attrs)
}
opspec := tf.OpSpec{
- Type: "FakeQuantWithMinMaxArgsGradient",
+ Type: "FakeQuantWithMinMaxArgs",
Input: []tf.Input{
- gradients, inputs,
+ inputs,
},
Attrs: attrs,
}
@@ -274,192 +229,6 @@ func FakeQuantWithMinMaxArgsGradient(scope *Scope, gradients tf.Output, inputs t
return op.Output(0)
}
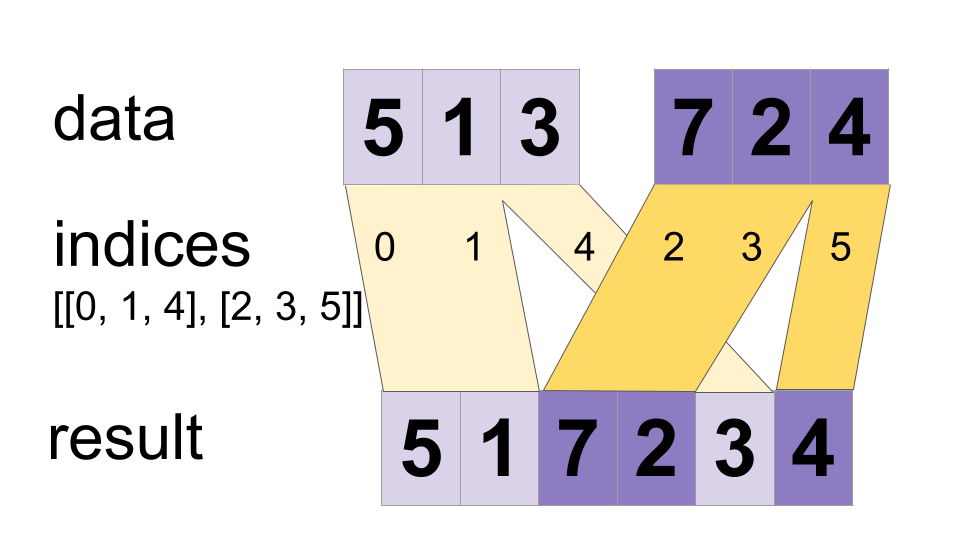
-// Adds sparse `updates` to an existing tensor according to `indices`.
-//
-// This operation creates a new tensor by adding sparse `updates` to the passed
-// in `tensor`.
-// This operation is very similar to `tf.scatter_nd_add`, except that the updates
-// are added onto an existing tensor (as opposed to a variable). If the memory
-// for the existing tensor cannot be re-used, a copy is made and updated.
-//
-// `indices` is an integer tensor containing indices into a new tensor of shape
-// `shape`. The last dimension of `indices` can be at most the rank of `shape`:
-//
-// indices.shape[-1] <= shape.rank
-//
-// The last dimension of `indices` corresponds to indices into elements
-// (if `indices.shape[-1] = shape.rank`) or slices
-// (if `indices.shape[-1] < shape.rank`) along dimension `indices.shape[-1]` of
-// `shape`. `updates` is a tensor with shape
-//
-// indices.shape[:-1] + shape[indices.shape[-1]:]
-//
-// The simplest form of tensor_scatter_add is to add individual elements to a
-// tensor by index. For example, say we want to add 4 elements in a rank-1
-// tensor with 8 elements.
-//
-// In Python, this scatter add operation would look like this:
-//
-// ```python
-// indices = tf.constant([[4], [3], [1], [7]])
-// updates = tf.constant([9, 10, 11, 12])
-// tensor = tf.ones([8], dtype=tf.int32)
-// updated = tf.tensor_scatter_add(tensor, indices, updates)
-// with tf.Session() as sess:
-// print(sess.run(scatter))
-// ```
-//
-// The resulting tensor would look like this:
-//
-// [1, 12, 1, 11, 10, 1, 1, 13]
-//
-// We can also, insert entire slices of a higher rank tensor all at once. For
-// example, if we wanted to insert two slices in the first dimension of a
-// rank-3 tensor with two matrices of new values.
-//
-// In Python, this scatter add operation would look like this:
-//
-// ```python
-// indices = tf.constant([[0], [2]])
-// updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6],
-// [7, 7, 7, 7], [8, 8, 8, 8]],
-// [[5, 5, 5, 5], [6, 6, 6, 6],
-// [7, 7, 7, 7], [8, 8, 8, 8]]])
-// tensor = tf.ones([4, 4, 4])
-// updated = tf.tensor_scatter_add(tensor, indices, updates)
-// with tf.Session() as sess:
-// print(sess.run(scatter))
-// ```
-//
-// The resulting tensor would look like this:
-//
-// [[[6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8], [9, 9, 9, 9]],
-// [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]],
-// [[6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8], [9, 9, 9, 9]],
-// [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]]]
-//
-// Note that on CPU, if an out of bound index is found, an error is returned.
-// On GPU, if an out of bound index is found, the index is ignored.
-//
-// Arguments:
-// tensor: Tensor to copy/update.
-// indices: Index tensor.
-// updates: Updates to scatter into output.
-//
-// Returns A new tensor copied from tensor and updates added according to the indices.
-func TensorScatterAdd(scope *Scope, tensor tf.Output, indices tf.Output, updates tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "TensorScatterAdd",
- Input: []tf.Input{
- tensor, indices, updates,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Scatter `updates` into an existing tensor according to `indices`.
-//
-// This operation creates a new tensor by applying sparse `updates` to the passed
-// in `tensor`.
-// This operation is very similar to `tf.scatter_nd`, except that the updates are
-// scattered onto an existing tensor (as opposed to a zero-tensor). If the memory
-// for the existing tensor cannot be re-used, a copy is made and updated.
-//
-// If `indices` contains duplicates, then their updates are accumulated (summed).
-//
-// **WARNING**: The order in which updates are applied is nondeterministic, so the
-// output will be nondeterministic if `indices` contains duplicates -- because
-// of some numerical approximation issues, numbers summed in different order
-// may yield different results.
-//
-// `indices` is an integer tensor containing indices into a new tensor of shape
-// `shape`. The last dimension of `indices` can be at most the rank of `shape`:
-//
-// indices.shape[-1] <= shape.rank
-//
-// The last dimension of `indices` corresponds to indices into elements
-// (if `indices.shape[-1] = shape.rank`) or slices
-// (if `indices.shape[-1] < shape.rank`) along dimension `indices.shape[-1]` of
-// `shape`. `updates` is a tensor with shape
-//
-// indices.shape[:-1] + shape[indices.shape[-1]:]
-//
-// The simplest form of scatter is to insert individual elements in a tensor by
-// index. For example, say we want to insert 4 scattered elements in a rank-1
-// tensor with 8 elements.
-//
-//
-//

-//
//

//
+//
+//
+//
+//
-//
-//
-//
-//
-//
-//
+//
+//
+//
+//
+//
+//
+//
+//
+// Shai Shalev-Shwartz, Tong Zhang. 2012
+//
+// $$Loss Objective = \sum f_{i} (wx_{i}) + (l2 / 2) * |w|^2 + l1 * |w|$$
+//
+// [Adding vs. Averaging in Distributed Primal-Dual Optimization](http://arxiv.org/abs/1502.03508).
+// Chenxin Ma, Virginia Smith, Martin Jaggi, Michael I. Jordan,
+// Peter Richtarik, Martin Takac. 2015
+//
+// [Stochastic Dual Coordinate Ascent with Adaptive Probabilities](https://arxiv.org/abs/1502.08053).
+// Dominik Csiba, Zheng Qu, Peter Richtarik. 2015
+//
+// Arguments:
+// sparse_example_indices: a list of vectors which contain example indices.
+// sparse_feature_indices: a list of vectors which contain feature indices.
+// sparse_feature_values: a list of vectors which contains feature value
+// associated with each feature group.
+// dense_features: a list of matrices which contains the dense feature values.
+// example_weights: a vector which contains the weight associated with each
+// example.
+// example_labels: a vector which contains the label/target associated with each
+// example.
+// sparse_indices: a list of vectors where each value is the indices which has
+// corresponding weights in sparse_weights. This field maybe omitted for the
+// dense approach.
+// sparse_weights: a list of vectors where each value is the weight associated with
+// a sparse feature group.
+// dense_weights: a list of vectors where the values are the weights associated
+// with a dense feature group.
+// example_state_data: a list of vectors containing the example state data.
+// loss_type: Type of the primal loss. Currently SdcaSolver supports logistic,
+// squared and hinge losses.
+// l1: Symmetric l1 regularization strength.
+// l2: Symmetric l2 regularization strength.
+// num_loss_partitions: Number of partitions of the global loss function.
+// num_inner_iterations: Number of iterations per mini-batch.
+//
+// Returns a list of vectors containing the updated example state
+// data.a list of vectors where each value is the delta
+// weights associated with a sparse feature group.a list of vectors where the values are the delta
+// weights associated with a dense feature group.
+func SdcaOptimizerV2(scope *Scope, sparse_example_indices []tf.Output, sparse_feature_indices []tf.Output, sparse_feature_values []tf.Output, dense_features []tf.Output, example_weights tf.Output, example_labels tf.Output, sparse_indices []tf.Output, sparse_weights []tf.Output, dense_weights []tf.Output, example_state_data tf.Output, loss_type string, l1 float32, l2 float32, num_loss_partitions int64, num_inner_iterations int64, optional ...SdcaOptimizerV2Attr) (out_example_state_data tf.Output, out_delta_sparse_weights []tf.Output, out_delta_dense_weights []tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"loss_type": loss_type, "l1": l1, "l2": l2, "num_loss_partitions": num_loss_partitions, "num_inner_iterations": num_inner_iterations}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "SdcaOptimizerV2",
+ Input: []tf.Input{
+ tf.OutputList(sparse_example_indices), tf.OutputList(sparse_feature_indices), tf.OutputList(sparse_feature_values), tf.OutputList(dense_features), example_weights, example_labels, tf.OutputList(sparse_indices), tf.OutputList(sparse_weights), tf.OutputList(dense_weights), example_state_data,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ if scope.Err() != nil {
+ return
+ }
+ var idx int
+ var err error
+ out_example_state_data = op.Output(idx)
+ if out_delta_sparse_weights, idx, err = makeOutputList(op, idx, "out_delta_sparse_weights"); err != nil {
+ scope.UpdateErr("SdcaOptimizerV2", err)
+ return
+ }
+ if out_delta_dense_weights, idx, err = makeOutputList(op, idx, "out_delta_dense_weights"); err != nil {
+ scope.UpdateErr("SdcaOptimizerV2", err)
+ return
+ }
+ return out_example_state_data, out_delta_sparse_weights, out_delta_dense_weights
}
// Returns the truth value of (x > y) element-wise.
@@ -13491,49 +13853,279 @@ func Greater(scope *Scope, x tf.Output, y tf.Output) (z tf.Output) {
return op.Output(0)
}
-// Greedily selects a subset of bounding boxes in descending order of score,
+// SampleDistortedBoundingBoxAttr is an optional argument to SampleDistortedBoundingBox.
+type SampleDistortedBoundingBoxAttr func(optionalAttr)
+
+// SampleDistortedBoundingBoxSeed sets the optional seed attribute to value.
//
-// pruning away boxes that have high overlaps
-// with previously selected boxes. Bounding boxes with score less than
-// `score_threshold` are removed. N-by-n overlap values are supplied as square matrix,
-// which allows for defining a custom overlap criterium (eg. intersection over union,
-// intersection over area, etc.).
+// value: If either `seed` or `seed2` are set to non-zero, the random number
+// generator is seeded by the given `seed`. Otherwise, it is seeded by a random
+// seed.
+// If not specified, defaults to 0
+func SampleDistortedBoundingBoxSeed(value int64) SampleDistortedBoundingBoxAttr {
+ return func(m optionalAttr) {
+ m["seed"] = value
+ }
+}
+
+// SampleDistortedBoundingBoxSeed2 sets the optional seed2 attribute to value.
//
-// The output of this operation is a set of integers indexing into the input
-// collection of bounding boxes representing the selected boxes. The bounding
-// box coordinates corresponding to the selected indices can then be obtained
-// using the `tf.gather operation`. For example:
+// value: A second seed to avoid seed collision.
+// If not specified, defaults to 0
+func SampleDistortedBoundingBoxSeed2(value int64) SampleDistortedBoundingBoxAttr {
+ return func(m optionalAttr) {
+ m["seed2"] = value
+ }
+}
+
+// SampleDistortedBoundingBoxMinObjectCovered sets the optional min_object_covered attribute to value.
//
-// selected_indices = tf.image.non_max_suppression_with_overlaps(
-// overlaps, scores, max_output_size, overlap_threshold, score_threshold)
-// selected_boxes = tf.gather(boxes, selected_indices)
+// value: The cropped area of the image must contain at least this
+// fraction of any bounding box supplied. The value of this parameter should be
+// non-negative. In the case of 0, the cropped area does not need to overlap
+// any of the bounding boxes supplied.
+// If not specified, defaults to 0.1
+func SampleDistortedBoundingBoxMinObjectCovered(value float32) SampleDistortedBoundingBoxAttr {
+ return func(m optionalAttr) {
+ m["min_object_covered"] = value
+ }
+}
+
+// SampleDistortedBoundingBoxAspectRatioRange sets the optional aspect_ratio_range attribute to value.
+//
+// value: The cropped area of the image must have an aspect ratio =
+// width / height within this range.
+// If not specified, defaults to
+func SampleDistortedBoundingBoxAspectRatioRange(value []float32) SampleDistortedBoundingBoxAttr {
+ return func(m optionalAttr) {
+ m["aspect_ratio_range"] = value
+ }
+}
+
+// SampleDistortedBoundingBoxAreaRange sets the optional area_range attribute to value.
+//
+// value: The cropped area of the image must contain a fraction of the
+// supplied image within this range.
+// If not specified, defaults to
+func SampleDistortedBoundingBoxAreaRange(value []float32) SampleDistortedBoundingBoxAttr {
+ return func(m optionalAttr) {
+ m["area_range"] = value
+ }
+}
+
+// SampleDistortedBoundingBoxMaxAttempts sets the optional max_attempts attribute to value.
+//
+// value: Number of attempts at generating a cropped region of the image
+// of the specified constraints. After `max_attempts` failures, return the entire
+// image.
+// If not specified, defaults to 100
+func SampleDistortedBoundingBoxMaxAttempts(value int64) SampleDistortedBoundingBoxAttr {
+ return func(m optionalAttr) {
+ m["max_attempts"] = value
+ }
+}
+
+// SampleDistortedBoundingBoxUseImageIfNoBoundingBoxes sets the optional use_image_if_no_bounding_boxes attribute to value.
+//
+// value: Controls behavior if no bounding boxes supplied.
+// If true, assume an implicit bounding box covering the whole input. If false,
+// raise an error.
+// If not specified, defaults to false
+func SampleDistortedBoundingBoxUseImageIfNoBoundingBoxes(value bool) SampleDistortedBoundingBoxAttr {
+ return func(m optionalAttr) {
+ m["use_image_if_no_bounding_boxes"] = value
+ }
+}
+
+// Generate a single randomly distorted bounding box for an image.
+//
+// Bounding box annotations are often supplied in addition to ground-truth labels
+// in image recognition or object localization tasks. A common technique for
+// training such a system is to randomly distort an image while preserving
+// its content, i.e. *data augmentation*. This Op outputs a randomly distorted
+// localization of an object, i.e. bounding box, given an `image_size`,
+// `bounding_boxes` and a series of constraints.
+//
+// The output of this Op is a single bounding box that may be used to crop the
+// original image. The output is returned as 3 tensors: `begin`, `size` and
+// `bboxes`. The first 2 tensors can be fed directly into `tf.slice` to crop the
+// image. The latter may be supplied to `tf.image.draw_bounding_boxes` to visualize
+// what the bounding box looks like.
+//
+// Bounding boxes are supplied and returned as `[y_min, x_min, y_max, x_max]`. The
+// bounding box coordinates are floats in `[0.0, 1.0]` relative to the width and
+// height of the underlying image.
+//
+// For example,
+//
+// ```python
+// # Generate a single distorted bounding box.
+// begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box(
+// tf.shape(image),
+// bounding_boxes=bounding_boxes)
+//
+// # Draw the bounding box in an image summary.
+// image_with_box = tf.image.draw_bounding_boxes(tf.expand_dims(image, 0),
+// bbox_for_draw)
+// tf.summary.image('images_with_box', image_with_box)
+//
+// # Employ the bounding box to distort the image.
+// distorted_image = tf.slice(image, begin, size)
+// ```
+//
+// Note that if no bounding box information is available, setting
+// `use_image_if_no_bounding_boxes = true` will assume there is a single implicit
+// bounding box covering the whole image. If `use_image_if_no_bounding_boxes` is
+// false and no bounding boxes are supplied, an error is raised.
//
// Arguments:
-// overlaps: A 2-D float tensor of shape `[num_boxes, num_boxes]` representing
-// the n-by-n box overlap values.
-// scores: A 1-D float tensor of shape `[num_boxes]` representing a single
-// score corresponding to each box (each row of boxes).
-// max_output_size: A scalar integer tensor representing the maximum number of
-// boxes to be selected by non max suppression.
-// overlap_threshold: A 0-D float tensor representing the threshold for deciding whether
-// boxes overlap too.
-// score_threshold: A 0-D float tensor representing the threshold for deciding when to remove
-// boxes based on score.
+// image_size: 1-D, containing `[height, width, channels]`.
+// bounding_boxes: 3-D with shape `[batch, N, 4]` describing the N bounding boxes
+// associated with the image.
//
-// Returns A 1-D integer tensor of shape `[M]` representing the selected
-// indices from the boxes tensor, where `M <= max_output_size`.
-func NonMaxSuppressionWithOverlaps(scope *Scope, overlaps tf.Output, scores tf.Output, max_output_size tf.Output, overlap_threshold tf.Output, score_threshold tf.Output) (selected_indices tf.Output) {
+// Returns 1-D, containing `[offset_height, offset_width, 0]`. Provide as input to
+// `tf.slice`.1-D, containing `[target_height, target_width, -1]`. Provide as input to
+// `tf.slice`.3-D with shape `[1, 1, 4]` containing the distorted bounding box.
+// Provide as input to `tf.image.draw_bounding_boxes`.
+func SampleDistortedBoundingBox(scope *Scope, image_size tf.Output, bounding_boxes tf.Output, optional ...SampleDistortedBoundingBoxAttr) (begin tf.Output, size tf.Output, bboxes tf.Output) {
if scope.Err() != nil {
return
}
+ attrs := map[string]interface{}{}
+ for _, a := range optional {
+ a(attrs)
+ }
opspec := tf.OpSpec{
- Type: "NonMaxSuppressionWithOverlaps",
+ Type: "SampleDistortedBoundingBox",
Input: []tf.Input{
- overlaps, scores, max_output_size, overlap_threshold, score_threshold,
+ image_size, bounding_boxes,
},
+ Attrs: attrs,
}
op := scope.AddOperation(opspec)
- return op.Output(0)
+ return op.Output(0), op.Output(1), op.Output(2)
+}
+
+// TryRpcAttr is an optional argument to TryRpc.
+type TryRpcAttr func(optionalAttr)
+
+// TryRpcProtocol sets the optional protocol attribute to value.
+//
+// value: RPC protocol to use. Empty string means use the default protocol.
+// Options include 'grpc'.
+// If not specified, defaults to ""
+func TryRpcProtocol(value string) TryRpcAttr {
+ return func(m optionalAttr) {
+ m["protocol"] = value
+ }
+}
+
+// TryRpcFailFast sets the optional fail_fast attribute to value.
+//
+// value: `boolean`. If `true` (default), then failures to connect
+// (i.e., the server does not immediately respond) cause an RPC failure.
+// If not specified, defaults to true
+func TryRpcFailFast(value bool) TryRpcAttr {
+ return func(m optionalAttr) {
+ m["fail_fast"] = value
+ }
+}
+
+// TryRpcTimeoutInMs sets the optional timeout_in_ms attribute to value.
+//
+// value: `int`. If `0` (default), then the kernel will run the RPC
+// request and only time out if the RPC deadline passes or the session times out.
+// If this value is greater than `0`, then the op will raise an exception if
+// the RPC takes longer than `timeout_in_ms`.
+// If not specified, defaults to 0
+func TryRpcTimeoutInMs(value int64) TryRpcAttr {
+ return func(m optionalAttr) {
+ m["timeout_in_ms"] = value
+ }
+}
+
+// Perform batches of RPC requests.
+//
+// This op asynchronously performs either a single RPC request, or a batch
+// of requests. RPC requests are defined by three main parameters:
+//
+// - `address` (the host+port or BNS address of the request)
+// - `method` (the method name for the request)
+// - `request` (the serialized proto string, or vector of strings,
+// of the RPC request argument).
+//
+// For example, if you have an RPC service running on port localhost:2345,
+// and its interface is configured with the following proto declaration:
+//
+// ```
+// service MyService {
+// rpc MyMethod(MyRequestProto) returns (MyResponseProto) {
+// }
+// };
+// ```
+//
+// then call this op with arguments:
+//
+// ```
+// address = "localhost:2345"
+// method = "MyService/MyMethod"
+// ```
+//
+// The `request` tensor is a string tensor representing serialized `MyRequestProto`
+// strings; and the output string tensor `response` will have the same shape
+// and contain (upon successful completion) corresponding serialized
+// `MyResponseProto` strings.
+//
+// For example, to send a single, empty, `MyRequestProto`, call
+// this op with `request = ""`. To send 5 **parallel** empty requests,
+// call this op with `request = ["", "", "", "", ""]`.
+//
+// More generally, one can create a batch of `MyRequestProto` serialized protos
+// from regular batched tensors using the `encode_proto` op, and convert
+// the response `MyResponseProto` serialized protos to batched tensors
+// using the `decode_proto` op.
+//
+// **NOTE** Working with serialized proto strings is faster than instantiating
+// actual proto objects in memory, so no performance degradation is expected
+// compared to writing custom kernels for this workflow.
+//
+// Unlike the standard `Rpc` op, if the connection fails or the remote worker
+// returns an error status, this op does **not** reraise the exception.
+// Instead, the `status_code` and `status_message` entry for the corresponding RPC
+// call is set with the error returned from the RPC call. The `response` tensor
+// will contain valid response values for those minibatch entries whose RPCs did
+// not fail; the rest of the entries will have empty strings.
+//
+// Arguments:
+// address: `0-D` or `1-D`. The address (i.e. host_name:port) of the RPC server.
+// If this tensor has more than 1 element, then multiple parallel rpc requests
+// are sent. This argument broadcasts with `method` and `request`.
+// method: `0-D` or `1-D`. The method address on the RPC server.
+// If this tensor has more than 1 element, then multiple parallel rpc requests
+// are sent. This argument broadcasts with `address` and `request`.
+// request: `0-D` or `1-D`. Serialized proto strings: the rpc request argument.
+// If this tensor has more than 1 element, then multiple parallel rpc requests
+// are sent. This argument broadcasts with `address` and `method`.
+//
+// Returns Same shape as `request`. Serialized proto strings: the rpc responses.Same shape as `request`. Values correspond to tensorflow Status enum codes.Same shape as `request`. Values correspond to Status messages
+// returned from the RPC calls.
+func TryRpc(scope *Scope, address tf.Output, method tf.Output, request tf.Output, optional ...TryRpcAttr) (response tf.Output, status_code tf.Output, status_message tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "TryRpc",
+ Input: []tf.Input{
+ address, method, request,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0), op.Output(1), op.Output(2)
}
// DenseToDenseSetOperationAttr is an optional argument to DenseToDenseSetOperation.
@@ -13586,102 +14178,21 @@ func DenseToDenseSetOperation(scope *Scope, set1 tf.Output, set2 tf.Output, set_
return op.Output(0), op.Output(1), op.Output(2)
}
-// An Op to permute tensors across replicated TPU instances.
-//
-// Each instance supplies its own input.
-//
-// For example, suppose there are 4 TPU instances: `[A, B, C, D]`. Passing
-// source_target_pairs=`[[0,1],[1,2],[2,3],[3,0]]` gets the outputs:
-// `[D, A, B, C]`.
-//
-// Arguments:
-// input: The local input to be permuted. Currently only supports float and
-// bfloat16.
-// source_target_pairs: A tensor with shape [num_pairs, 2].
-//
-// Returns The permuted input.
-func CollectivePermute(scope *Scope, input tf.Output, source_target_pairs tf.Output) (output tf.Output) {
+// Receives a tensor value broadcast from another device.
+func CollectiveBcastRecv(scope *Scope, T tf.DataType, group_size int64, group_key int64, instance_key int64, shape tf.Shape) (data tf.Output) {
if scope.Err() != nil {
return
}
+ attrs := map[string]interface{}{"T": T, "group_size": group_size, "group_key": group_key, "instance_key": instance_key, "shape": shape}
opspec := tf.OpSpec{
- Type: "CollectivePermute",
- Input: []tf.Input{
- input, source_target_pairs,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
+ Type: "CollectiveBcastRecv",
-// ImagAttr is an optional argument to Imag.
-type ImagAttr func(optionalAttr)
-
-// ImagTout sets the optional Tout attribute to value.
-// If not specified, defaults to DT_FLOAT
-func ImagTout(value tf.DataType) ImagAttr {
- return func(m optionalAttr) {
- m["Tout"] = value
- }
-}
-
-// Returns the imaginary part of a complex number.
-//
-// Given a tensor `input` of complex numbers, this operation returns a tensor of
-// type `float` that is the imaginary part of each element in `input`. All
-// elements in `input` must be complex numbers of the form \\(a + bj\\), where *a*
-// is the real part and *b* is the imaginary part returned by this operation.
-//
-// For example:
-//
-// ```
-// # tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j]
-// tf.imag(input) ==> [4.75, 5.75]
-// ```
-func Imag(scope *Scope, input tf.Output, optional ...ImagAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "Imag",
- Input: []tf.Input{
- input,
- },
Attrs: attrs,
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
-// Compute the pairwise cross product.
-//
-// `a` and `b` must be the same shape; they can either be simple 3-element vectors,
-// or any shape where the innermost dimension is 3. In the latter case, each pair
-// of corresponding 3-element vectors is cross-multiplied independently.
-//
-// Arguments:
-// a: A tensor containing 3-element vectors.
-// b: Another tensor, of same type and shape as `a`.
-//
-// Returns Pairwise cross product of the vectors in `a` and `b`.
-func Cross(scope *Scope, a tf.Output, b tf.Output) (product tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "Cross",
- Input: []tf.Input{
- a, b,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
// SetSizeAttr is an optional argument to SetSize.
type SetSizeAttr func(optionalAttr)
@@ -13729,30 +14240,47 @@ func SetSize(scope *Scope, set_indices tf.Output, set_values tf.Output, set_shap
return op.Output(0)
}
-// DestroyResourceOpAttr is an optional argument to DestroyResourceOp.
-type DestroyResourceOpAttr func(optionalAttr)
+// ListDiffAttr is an optional argument to ListDiff.
+type ListDiffAttr func(optionalAttr)
-// DestroyResourceOpIgnoreLookupError sets the optional ignore_lookup_error attribute to value.
-//
-// value: whether to ignore the error when the resource
-// doesn't exist.
-// If not specified, defaults to true
-func DestroyResourceOpIgnoreLookupError(value bool) DestroyResourceOpAttr {
+// ListDiffOutIdx sets the optional out_idx attribute to value.
+// If not specified, defaults to DT_INT32
+func ListDiffOutIdx(value tf.DataType) ListDiffAttr {
return func(m optionalAttr) {
- m["ignore_lookup_error"] = value
+ m["out_idx"] = value
}
}
-// Deletes the resource specified by the handle.
+// Computes the difference between two lists of numbers or strings.
//
-// All subsequent operations using the resource will result in a NotFound
-// error status.
+// Given a list `x` and a list `y`, this operation returns a list `out` that
+// represents all values that are in `x` but not in `y`. The returned list `out`
+// is sorted in the same order that the numbers appear in `x` (duplicates are
+// preserved). This operation also returns a list `idx` that represents the
+// position of each `out` element in `x`. In other words:
+//
+// `out[i] = x[idx[i]] for i in [0, 1, ..., len(out) - 1]`
+//
+// For example, given this input:
+//
+// ```
+// x = [1, 2, 3, 4, 5, 6]
+// y = [1, 3, 5]
+// ```
+//
+// This operation would return:
+//
+// ```
+// out ==> [2, 4, 6]
+// idx ==> [1, 3, 5]
+// ```
//
// Arguments:
-// resource: handle to the resource to delete.
+// x: 1-D. Values to keep.
+// y: 1-D. Values to remove.
//
-// Returns the created operation.
-func DestroyResourceOp(scope *Scope, resource tf.Output, optional ...DestroyResourceOpAttr) (o *tf.Operation) {
+// Returns 1-D. Values present in `x` but not in `y`.1-D. Positions of `x` values preserved in `out`.
+func ListDiff(scope *Scope, x tf.Output, y tf.Output, optional ...ListDiffAttr) (out tf.Output, idx tf.Output) {
if scope.Err() != nil {
return
}
@@ -13761,242 +14289,75 @@ func DestroyResourceOp(scope *Scope, resource tf.Output, optional ...DestroyReso
a(attrs)
}
opspec := tf.OpSpec{
- Type: "DestroyResourceOp",
+ Type: "ListDiff",
Input: []tf.Input{
- resource,
+ x, y,
},
Attrs: attrs,
}
- return scope.AddOperation(opspec)
-}
-
-// The gradient of SparseFillEmptyRows.
-//
-// Takes vectors reverse_index_map, shaped `[N]`, and grad_values,
-// shaped `[N_full]`, where `N_full >= N` and copies data into either
-// `d_values` or `d_default_value`. Here `d_values` is shaped `[N]` and
-// `d_default_value` is a scalar.
-//
-// d_values[j] = grad_values[reverse_index_map[j]]
-// d_default_value = sum_{k : 0 .. N_full - 1} (
-// grad_values[k] * 1{k not in reverse_index_map})
-//
-// Arguments:
-// reverse_index_map: 1-D. The reverse index map from SparseFillEmptyRows.
-// grad_values: 1-D. The gradients from backprop.
-//
-// Returns 1-D. The backprop into values.0-D. The backprop into default_value.
-func SparseFillEmptyRowsGrad(scope *Scope, reverse_index_map tf.Output, grad_values tf.Output) (d_values tf.Output, d_default_value tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "SparseFillEmptyRowsGrad",
- Input: []tf.Input{
- reverse_index_map, grad_values,
- },
- }
op := scope.AddOperation(opspec)
return op.Output(0), op.Output(1)
}
-// Computes scaled exponential linear: `scale * alpha * (exp(features) - 1)`
+// AddManySparseToTensorsMapAttr is an optional argument to AddManySparseToTensorsMap.
+type AddManySparseToTensorsMapAttr func(optionalAttr)
+
+// AddManySparseToTensorsMapContainer sets the optional container attribute to value.
//
-// if < 0, `scale * features` otherwise.
-//
-// To be used together with
-// `initializer = tf.variance_scaling_initializer(factor=1.0, mode='FAN_IN')`.
-// For correct dropout, use `tf.contrib.nn.alpha_dropout`.
-//
-// See [Self-Normalizing Neural Networks](https://arxiv.org/abs/1706.02515)
-func Selu(scope *Scope, features tf.Output) (activations tf.Output) {
- if scope.Err() != nil {
- return
+// value: The container name for the `SparseTensorsMap` created by this op.
+// If not specified, defaults to ""
+func AddManySparseToTensorsMapContainer(value string) AddManySparseToTensorsMapAttr {
+ return func(m optionalAttr) {
+ m["container"] = value
}
- opspec := tf.OpSpec{
- Type: "Selu",
- Input: []tf.Input{
- features,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
}
-// Broadcast an array for a compatible shape.
+// AddManySparseToTensorsMapSharedName sets the optional shared_name attribute to value.
//
-// Broadcasting is the process of making arrays to have compatible shapes
-// for arithmetic operations. Two shapes are compatible if for each
-// dimension pair they are either equal or one of them is one. When trying
-// to broadcast a Tensor to a shape, it starts with the trailing dimensions,
-// and works its way forward.
+// value: The shared name for the `SparseTensorsMap` created by this op.
+// If blank, the new Operation's unique name is used.
+// If not specified, defaults to ""
+func AddManySparseToTensorsMapSharedName(value string) AddManySparseToTensorsMapAttr {
+ return func(m optionalAttr) {
+ m["shared_name"] = value
+ }
+}
+
+// Add an `N`-minibatch `SparseTensor` to a `SparseTensorsMap`, return `N` handles.
//
-// For example,
+// A `SparseTensor` of rank `R` is represented by three tensors: `sparse_indices`,
+// `sparse_values`, and `sparse_shape`, where
//
-// ```python
-// >>> x = tf.constant([1, 2, 3])
-// >>> y = tf.broadcast_to(x, [3, 3])
-// >>> sess.run(y)
-// array([[1, 2, 3],
-// [1, 2, 3],
-// [1, 2, 3]], dtype=int32)
-// ```
+// ```sparse_indices.shape[1] == sparse_shape.shape[0] == R```
//
-// In the above example, the input Tensor with the shape of `[1, 3]`
-// is broadcasted to output Tensor with shape of `[3, 3]`.
+// An `N`-minibatch of `SparseTensor` objects is represented as a `SparseTensor`
+// having a first `sparse_indices` column taking values between `[0, N)`, where
+// the minibatch size `N == sparse_shape[0]`.
+//
+// The input `SparseTensor` must have rank `R` greater than 1, and the first
+// dimension is treated as the minibatch dimension. Elements of the `SparseTensor`
+// must be sorted in increasing order of this first dimension. The stored
+// `SparseTensor` objects pointed to by each row of the output `sparse_handles`
+// will have rank `R-1`.
+//
+// The `SparseTensor` values can then be read out as part of a minibatch by passing
+// the given keys as vector elements to `TakeManySparseFromTensorsMap`. To ensure
+// the correct `SparseTensorsMap` is accessed, ensure that the same
+// `container` and `shared_name` are passed to that Op. If no `shared_name`
+// is provided here, instead use the *name* of the Operation created by calling
+// `AddManySparseToTensorsMap` as the `shared_name` passed to
+// `TakeManySparseFromTensorsMap`. Ensure the Operations are colocated.
//
// Arguments:
-// input: A Tensor to broadcast.
-// shape: An 1-D `int` Tensor. The shape of the desired output.
+// sparse_indices: 2-D. The `indices` of the minibatch `SparseTensor`.
+// `sparse_indices[:, 0]` must be ordered values in `[0, N)`.
+// sparse_values: 1-D. The `values` of the minibatch `SparseTensor`.
+// sparse_shape: 1-D. The `shape` of the minibatch `SparseTensor`.
+// The minibatch size `N == sparse_shape[0]`.
//
-// Returns A Tensor.
-func BroadcastTo(scope *Scope, input tf.Output, shape tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "BroadcastTo",
- Input: []tf.Input{
- input, shape,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Updates the table to associates keys with values.
-//
-// The tensor `keys` must be of the same type as the keys of the table.
-// The tensor `values` must be of the type of the table values.
-//
-// Arguments:
-// table_handle: Handle to the table.
-// keys: Any shape. Keys to look up.
-// values: Values to associate with keys.
-//
-// Returns the created operation.
-func LookupTableInsertV2(scope *Scope, table_handle tf.Output, keys tf.Output, values tf.Output) (o *tf.Operation) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "LookupTableInsertV2",
- Input: []tf.Input{
- table_handle, keys, values,
- },
- }
- return scope.AddOperation(opspec)
-}
-
-// ParseSingleSequenceExampleAttr is an optional argument to ParseSingleSequenceExample.
-type ParseSingleSequenceExampleAttr func(optionalAttr)
-
-// ParseSingleSequenceExampleContextSparseTypes sets the optional context_sparse_types attribute to value.
-//
-// value: A list of Ncontext_sparse types; the data types of data in
-// each context Feature given in context_sparse_keys.
-// Currently the ParseSingleSequenceExample supports DT_FLOAT (FloatList),
-// DT_INT64 (Int64List), and DT_STRING (BytesList).
-// If not specified, defaults to <>
-//
-// REQUIRES: len(value) >= 0
-func ParseSingleSequenceExampleContextSparseTypes(value []tf.DataType) ParseSingleSequenceExampleAttr {
- return func(m optionalAttr) {
- m["context_sparse_types"] = value
- }
-}
-
-// ParseSingleSequenceExampleFeatureListDenseTypes sets the optional feature_list_dense_types attribute to value.
-// If not specified, defaults to <>
-//
-// REQUIRES: len(value) >= 0
-func ParseSingleSequenceExampleFeatureListDenseTypes(value []tf.DataType) ParseSingleSequenceExampleAttr {
- return func(m optionalAttr) {
- m["feature_list_dense_types"] = value
- }
-}
-
-// ParseSingleSequenceExampleContextDenseShapes sets the optional context_dense_shapes attribute to value.
-//
-// value: A list of Ncontext_dense shapes; the shapes of data in
-// each context Feature given in context_dense_keys.
-// The number of elements in the Feature corresponding to context_dense_key[j]
-// must always equal context_dense_shapes[j].NumEntries().
-// The shape of context_dense_values[j] will match context_dense_shapes[j].
-// If not specified, defaults to <>
-//
-// REQUIRES: len(value) >= 0
-func ParseSingleSequenceExampleContextDenseShapes(value []tf.Shape) ParseSingleSequenceExampleAttr {
- return func(m optionalAttr) {
- m["context_dense_shapes"] = value
- }
-}
-
-// ParseSingleSequenceExampleFeatureListSparseTypes sets the optional feature_list_sparse_types attribute to value.
-//
-// value: A list of Nfeature_list_sparse types; the data types
-// of data in each FeatureList given in feature_list_sparse_keys.
-// Currently the ParseSingleSequenceExample supports DT_FLOAT (FloatList),
-// DT_INT64 (Int64List), and DT_STRING (BytesList).
-// If not specified, defaults to <>
-//
-// REQUIRES: len(value) >= 0
-func ParseSingleSequenceExampleFeatureListSparseTypes(value []tf.DataType) ParseSingleSequenceExampleAttr {
- return func(m optionalAttr) {
- m["feature_list_sparse_types"] = value
- }
-}
-
-// ParseSingleSequenceExampleFeatureListDenseShapes sets the optional feature_list_dense_shapes attribute to value.
-//
-// value: A list of Nfeature_list_dense shapes; the shapes of
-// data in each FeatureList given in feature_list_dense_keys.
-// The shape of each Feature in the FeatureList corresponding to
-// feature_list_dense_key[j] must always equal
-// feature_list_dense_shapes[j].NumEntries().
-// If not specified, defaults to <>
-//
-// REQUIRES: len(value) >= 0
-func ParseSingleSequenceExampleFeatureListDenseShapes(value []tf.Shape) ParseSingleSequenceExampleAttr {
- return func(m optionalAttr) {
- m["feature_list_dense_shapes"] = value
- }
-}
-
-// Transforms a scalar brain.SequenceExample proto (as strings) into typed tensors.
-//
-// Arguments:
-// serialized: A scalar containing a binary serialized SequenceExample proto.
-// feature_list_dense_missing_assumed_empty: A vector listing the
-// FeatureList keys which may be missing from the SequenceExample. If the
-// associated FeatureList is missing, it is treated as empty. By default,
-// any FeatureList not listed in this vector must exist in the SequenceExample.
-// context_sparse_keys: A list of Ncontext_sparse string Tensors (scalars).
-// The keys expected in the Examples' features associated with context_sparse
-// values.
-// context_dense_keys: A list of Ncontext_dense string Tensors (scalars).
-// The keys expected in the SequenceExamples' context features associated with
-// dense values.
-// feature_list_sparse_keys: A list of Nfeature_list_sparse string Tensors
-// (scalars). The keys expected in the FeatureLists associated with sparse
-// values.
-// feature_list_dense_keys: A list of Nfeature_list_dense string Tensors (scalars).
-// The keys expected in the SequenceExamples' feature_lists associated
-// with lists of dense values.
-// context_dense_defaults: A list of Ncontext_dense Tensors (some may be empty).
-// context_dense_defaults[j] provides default values
-// when the SequenceExample's context map lacks context_dense_key[j].
-// If an empty Tensor is provided for context_dense_defaults[j],
-// then the Feature context_dense_keys[j] is required.
-// The input type is inferred from context_dense_defaults[j], even when it's
-// empty. If context_dense_defaults[j] is not empty, its shape must match
-// context_dense_shapes[j].
-// debug_name: A scalar containing the name of the serialized proto.
-// May contain, for example, table key (descriptive) name for the
-// corresponding serialized proto. This is purely useful for debugging
-// purposes, and the presence of values here has no effect on the output.
-// May also be an empty scalar if no name is available.
-func ParseSingleSequenceExample(scope *Scope, serialized tf.Output, feature_list_dense_missing_assumed_empty tf.Output, context_sparse_keys []tf.Output, context_dense_keys []tf.Output, feature_list_sparse_keys []tf.Output, feature_list_dense_keys []tf.Output, context_dense_defaults []tf.Output, debug_name tf.Output, optional ...ParseSingleSequenceExampleAttr) (context_sparse_indices []tf.Output, context_sparse_values []tf.Output, context_sparse_shapes []tf.Output, context_dense_values []tf.Output, feature_list_sparse_indices []tf.Output, feature_list_sparse_values []tf.Output, feature_list_sparse_shapes []tf.Output, feature_list_dense_values []tf.Output) {
+// Returns 1-D. The handles of the `SparseTensor` now stored in the
+// `SparseTensorsMap`. Shape: `[N]`.
+func AddManySparseToTensorsMap(scope *Scope, sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output, optional ...AddManySparseToTensorsMapAttr) (sparse_handles tf.Output) {
if scope.Err() != nil {
return
}
@@ -14005,133 +14366,9 @@ func ParseSingleSequenceExample(scope *Scope, serialized tf.Output, feature_list
a(attrs)
}
opspec := tf.OpSpec{
- Type: "ParseSingleSequenceExample",
+ Type: "AddManySparseToTensorsMap",
Input: []tf.Input{
- serialized, feature_list_dense_missing_assumed_empty, tf.OutputList(context_sparse_keys), tf.OutputList(context_dense_keys), tf.OutputList(feature_list_sparse_keys), tf.OutputList(feature_list_dense_keys), tf.OutputList(context_dense_defaults), debug_name,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- if scope.Err() != nil {
- return
- }
- var idx int
- var err error
- if context_sparse_indices, idx, err = makeOutputList(op, idx, "context_sparse_indices"); err != nil {
- scope.UpdateErr("ParseSingleSequenceExample", err)
- return
- }
- if context_sparse_values, idx, err = makeOutputList(op, idx, "context_sparse_values"); err != nil {
- scope.UpdateErr("ParseSingleSequenceExample", err)
- return
- }
- if context_sparse_shapes, idx, err = makeOutputList(op, idx, "context_sparse_shapes"); err != nil {
- scope.UpdateErr("ParseSingleSequenceExample", err)
- return
- }
- if context_dense_values, idx, err = makeOutputList(op, idx, "context_dense_values"); err != nil {
- scope.UpdateErr("ParseSingleSequenceExample", err)
- return
- }
- if feature_list_sparse_indices, idx, err = makeOutputList(op, idx, "feature_list_sparse_indices"); err != nil {
- scope.UpdateErr("ParseSingleSequenceExample", err)
- return
- }
- if feature_list_sparse_values, idx, err = makeOutputList(op, idx, "feature_list_sparse_values"); err != nil {
- scope.UpdateErr("ParseSingleSequenceExample", err)
- return
- }
- if feature_list_sparse_shapes, idx, err = makeOutputList(op, idx, "feature_list_sparse_shapes"); err != nil {
- scope.UpdateErr("ParseSingleSequenceExample", err)
- return
- }
- if feature_list_dense_values, idx, err = makeOutputList(op, idx, "feature_list_dense_values"); err != nil {
- scope.UpdateErr("ParseSingleSequenceExample", err)
- return
- }
- return context_sparse_indices, context_sparse_values, context_sparse_shapes, context_dense_values, feature_list_sparse_indices, feature_list_sparse_values, feature_list_sparse_shapes, feature_list_dense_values
-}
-
-// Fills empty rows in the input 2-D `SparseTensor` with a default value.
-//
-// The input `SparseTensor` is represented via the tuple of inputs
-// (`indices`, `values`, `dense_shape`). The output `SparseTensor` has the
-// same `dense_shape` but with indices `output_indices` and values
-// `output_values`.
-//
-// This op inserts a single entry for every row that doesn't have any values.
-// The index is created as `[row, 0, ..., 0]` and the inserted value
-// is `default_value`.
-//
-// For example, suppose `sp_input` has shape `[5, 6]` and non-empty values:
-//
-// [0, 1]: a
-// [0, 3]: b
-// [2, 0]: c
-// [3, 1]: d
-//
-// Rows 1 and 4 are empty, so the output will be of shape `[5, 6]` with values:
-//
-// [0, 1]: a
-// [0, 3]: b
-// [1, 0]: default_value
-// [2, 0]: c
-// [3, 1]: d
-// [4, 0]: default_value
-//
-// The output `SparseTensor` will be in row-major order and will have the
-// same shape as the input.
-//
-// This op also returns an indicator vector shaped `[dense_shape[0]]` such that
-//
-// empty_row_indicator[i] = True iff row i was an empty row.
-//
-// And a reverse index map vector shaped `[indices.shape[0]]` that is used during
-// backpropagation,
-//
-// reverse_index_map[j] = out_j s.t. indices[j, :] == output_indices[out_j, :]
-//
-// Arguments:
-// indices: 2-D. the indices of the sparse tensor.
-// values: 1-D. the values of the sparse tensor.
-// dense_shape: 1-D. the shape of the sparse tensor.
-// default_value: 0-D. default value to insert into location `[row, 0, ..., 0]`
-// for rows missing from the input sparse tensor.
-// output indices: 2-D. the indices of the filled sparse tensor.
-//
-// Returns 1-D. the values of the filled sparse tensor.1-D. whether the dense row was missing in the
-// input sparse tensor.1-D. a map from the input indices to the output indices.
-func SparseFillEmptyRows(scope *Scope, indices tf.Output, values tf.Output, dense_shape tf.Output, default_value tf.Output) (output_indices tf.Output, output_values tf.Output, empty_row_indicator tf.Output, reverse_index_map tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "SparseFillEmptyRows",
- Input: []tf.Input{
- indices, values, dense_shape, default_value,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1), op.Output(2), op.Output(3)
-}
-
-// Transforms a serialized tensorflow.TensorProto proto into a Tensor.
-//
-// Arguments:
-// serialized: A scalar string containing a serialized TensorProto proto.
-// out_type: The type of the serialized tensor. The provided type must match the
-// type of the serialized tensor and no implicit conversion will take place.
-//
-// Returns A Tensor of type `out_type`.
-func ParseTensor(scope *Scope, serialized tf.Output, out_type tf.DataType) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"out_type": out_type}
- opspec := tf.OpSpec{
- Type: "ParseTensor",
- Input: []tf.Input{
- serialized,
+ sparse_indices, sparse_values, sparse_shape,
},
Attrs: attrs,
}
@@ -14139,34 +14376,141 @@ func ParseTensor(scope *Scope, serialized tf.Output, out_type tf.DataType) (outp
return op.Output(0)
}
-// Computes the sum along sparse segments of a tensor divided by the sqrt of N.
-//
-// N is the size of the segment being reduced.
-//
-// See `tf.sparse.segment_sum` for usage examples.
-//
+// StatelessMultinomialAttr is an optional argument to StatelessMultinomial.
+type StatelessMultinomialAttr func(optionalAttr)
+
+// StatelessMultinomialOutputDtype sets the optional output_dtype attribute to value.
+// If not specified, defaults to DT_INT64
+func StatelessMultinomialOutputDtype(value tf.DataType) StatelessMultinomialAttr {
+ return func(m optionalAttr) {
+ m["output_dtype"] = value
+ }
+}
+
+// Draws samples from a multinomial distribution.
//
// Arguments:
+// logits: 2-D Tensor with shape `[batch_size, num_classes]`. Each slice `[i, :]`
+// represents the unnormalized log probabilities for all classes.
+// num_samples: 0-D. Number of independent samples to draw for each row slice.
+// seed: 2 seeds (shape [2]).
//
-// indices: A 1-D tensor. Has same rank as `segment_ids`.
-// segment_ids: A 1-D tensor. Values should be sorted and can be repeated.
+// Returns 2-D Tensor with shape `[batch_size, num_samples]`. Each slice `[i, :]`
+// contains the drawn class labels with range `[0, num_classes)`.
+func StatelessMultinomial(scope *Scope, logits tf.Output, num_samples tf.Output, seed tf.Output, optional ...StatelessMultinomialAttr) (output tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "StatelessMultinomial",
+ Input: []tf.Input{
+ logits, num_samples, seed,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// Applies softmax to a batched N-D `SparseTensor`.
//
-// Returns Has same shape as data, except for dimension 0 which
-// has size `k`, the number of segments.
-func SparseSegmentSqrtN(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output) (output tf.Output) {
+// The inputs represent an N-D SparseTensor with logical shape `[..., B, C]`
+// (where `N >= 2`), and with indices sorted in the canonical lexicographic order.
+//
+// This op is equivalent to applying the normal `tf.nn.softmax()` to each innermost
+// logical submatrix with shape `[B, C]`, but with the catch that *the implicitly
+// zero elements do not participate*. Specifically, the algorithm is equivalent
+// to the following:
+//
+// (1) Applies `tf.nn.softmax()` to a densified view of each innermost submatrix
+// with shape `[B, C]`, along the size-C dimension;
+// (2) Masks out the original implicitly-zero locations;
+// (3) Renormalizes the remaining elements.
+//
+// Hence, the `SparseTensor` result has exactly the same non-zero indices and
+// shape.
+//
+// Arguments:
+// sp_indices: 2-D. `NNZ x R` matrix with the indices of non-empty values in a
+// SparseTensor, in canonical ordering.
+// sp_values: 1-D. `NNZ` non-empty values corresponding to `sp_indices`.
+// sp_shape: 1-D. Shape of the input SparseTensor.
+//
+// Returns 1-D. The `NNZ` values for the result `SparseTensor`.
+func SparseSoftmax(scope *Scope, sp_indices tf.Output, sp_values tf.Output, sp_shape tf.Output) (output tf.Output) {
if scope.Err() != nil {
return
}
opspec := tf.OpSpec{
- Type: "SparseSegmentSqrtN",
+ Type: "SparseSoftmax",
Input: []tf.Input{
- data, indices, segment_ids,
+ sp_indices, sp_values, sp_shape,
},
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
+// LoadTPUEmbeddingFTRLParametersGradAccumDebugAttr is an optional argument to LoadTPUEmbeddingFTRLParametersGradAccumDebug.
+type LoadTPUEmbeddingFTRLParametersGradAccumDebugAttr func(optionalAttr)
+
+// LoadTPUEmbeddingFTRLParametersGradAccumDebugTableId sets the optional table_id attribute to value.
+// If not specified, defaults to -1
+//
+// REQUIRES: value >= -1
+func LoadTPUEmbeddingFTRLParametersGradAccumDebugTableId(value int64) LoadTPUEmbeddingFTRLParametersGradAccumDebugAttr {
+ return func(m optionalAttr) {
+ m["table_id"] = value
+ }
+}
+
+// LoadTPUEmbeddingFTRLParametersGradAccumDebugTableName sets the optional table_name attribute to value.
+// If not specified, defaults to ""
+func LoadTPUEmbeddingFTRLParametersGradAccumDebugTableName(value string) LoadTPUEmbeddingFTRLParametersGradAccumDebugAttr {
+ return func(m optionalAttr) {
+ m["table_name"] = value
+ }
+}
+
+// Load FTRL embedding parameters with debug support.
+//
+// An op that loads optimization parameters into HBM for embedding. Must be
+// preceded by a ConfigureTPUEmbeddingHost op that sets up the correct
+// embedding table configuration. For example, this op is used to install
+// parameters that are loaded from a checkpoint before a training loop is
+// executed.
+//
+// Arguments:
+// parameters: Value of parameters used in the FTRL optimization algorithm.
+// accumulators: Value of accumulators used in the FTRL optimization algorithm.
+// linears: Value of linears used in the FTRL optimization algorithm.
+// gradient_accumulators: Value of gradient_accumulators used in the FTRL optimization algorithm.
+//
+//
+//
+// Returns the created operation.
+func LoadTPUEmbeddingFTRLParametersGradAccumDebug(scope *Scope, parameters tf.Output, accumulators tf.Output, linears tf.Output, gradient_accumulators tf.Output, num_shards int64, shard_id int64, optional ...LoadTPUEmbeddingFTRLParametersGradAccumDebugAttr) (o *tf.Operation) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"num_shards": num_shards, "shard_id": shard_id}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "LoadTPUEmbeddingFTRLParametersGradAccumDebug",
+ Input: []tf.Input{
+ parameters, accumulators, linears, gradient_accumulators,
+ },
+ Attrs: attrs,
+ }
+ return scope.AddOperation(opspec)
+}
+
// Adds up a SparseTensor and a dense Tensor, using these special rules:
//
// (1) Broadcasts the dense side to have the same shape as the sparse side, if
@@ -14200,19 +14544,93 @@ func SparseDenseCwiseAdd(scope *Scope, sp_indices tf.Output, sp_values tf.Output
return op.Output(0)
}
-// Shuts down a running distributed TPU system.
+// Component-wise divides a SparseTensor by a dense Tensor.
//
-// The op returns an error if no system is running.
+// *Limitation*: this Op only broadcasts the dense side to the sparse side, but not
+// the other direction.
//
-// Returns the created operation.
-func ShutdownDistributedTPU(scope *Scope) (o *tf.Operation) {
+// Arguments:
+// sp_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
+// SparseTensor, possibly not in canonical ordering.
+// sp_values: 1-D. `N` non-empty values corresponding to `sp_indices`.
+// sp_shape: 1-D. Shape of the input SparseTensor.
+// dense: `R`-D. The dense Tensor operand.
+//
+// Returns 1-D. The `N` values that are operated on.
+func SparseDenseCwiseDiv(scope *Scope, sp_indices tf.Output, sp_values tf.Output, sp_shape tf.Output, dense tf.Output) (output tf.Output) {
if scope.Err() != nil {
return
}
opspec := tf.OpSpec{
- Type: "ShutdownDistributedTPU",
+ Type: "SparseDenseCwiseDiv",
+ Input: []tf.Input{
+ sp_indices, sp_values, sp_shape, dense,
+ },
}
- return scope.AddOperation(opspec)
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// StringSplitV2Attr is an optional argument to StringSplitV2.
+type StringSplitV2Attr func(optionalAttr)
+
+// StringSplitV2Maxsplit sets the optional maxsplit attribute to value.
+//
+// value: An `int`. If `maxsplit > 0`, limit of the split of the result.
+// If not specified, defaults to -1
+func StringSplitV2Maxsplit(value int64) StringSplitV2Attr {
+ return func(m optionalAttr) {
+ m["maxsplit"] = value
+ }
+}
+
+// Split elements of `source` based on `sep` into a `SparseTensor`.
+//
+// Let N be the size of source (typically N will be the batch size). Split each
+// element of `source` based on `sep` and return a `SparseTensor`
+// containing the split tokens. Empty tokens are ignored.
+//
+// For example, N = 2, source[0] is 'hello world' and source[1] is 'a b c',
+// then the output will be
+// ```
+// st.indices = [0, 0;
+// 0, 1;
+// 1, 0;
+// 1, 1;
+// 1, 2]
+// st.shape = [2, 3]
+// st.values = ['hello', 'world', 'a', 'b', 'c']
+// ```
+//
+// If `sep` is given, consecutive delimiters are not grouped together and are
+// deemed to delimit empty strings. For example, source of `"1<>2<><>3"` and
+// sep of `"<>"` returns `["1", "2", "", "3"]`. If `sep` is None or an empty
+// string, consecutive whitespace are regarded as a single separator, and the
+// result will contain no empty strings at the startor end if the string has
+// leading or trailing whitespace.
+//
+// Note that the above mentioned behavior matches python's str.split.
+//
+// Arguments:
+// input: `1-D` string `Tensor`, the strings to split.
+// sep: `0-D` string `Tensor`, the delimiter character.
+func StringSplitV2(scope *Scope, input tf.Output, sep tf.Output, optional ...StringSplitV2Attr) (indices tf.Output, values tf.Output, shape tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "StringSplitV2",
+ Input: []tf.Input{
+ input, sep,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0), op.Output(1), op.Output(2)
}
// Component-wise multiplies a SparseTensor by a dense Tensor.
@@ -14441,6 +14859,24 @@ func SparseReduceSum(scope *Scope, input_indices tf.Output, input_values tf.Outp
return op.Output(0)
}
+// Elementwise computes the bitwise OR of `x` and `y`.
+//
+// The result will have those bits set, that are set in `x`, `y` or both. The
+// computation is performed on the underlying representations of `x` and `y`.
+func BitwiseOr(scope *Scope, x tf.Output, y tf.Output) (z tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ opspec := tf.OpSpec{
+ Type: "BitwiseOr",
+ Input: []tf.Input{
+ x, y,
+ },
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
// Records the bytes size of each element of `input_dataset` in a StatsAggregator.
func ExperimentalBytesProducedStatsDataset(scope *Scope, input_dataset tf.Output, tag tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output) {
if scope.Err() != nil {
@@ -14458,14 +14894,40 @@ func ExperimentalBytesProducedStatsDataset(scope *Scope, input_dataset tf.Output
return op.Output(0)
}
-// SparseReduceMaxSparseAttr is an optional argument to SparseReduceMaxSparse.
-type SparseReduceMaxSparseAttr func(optionalAttr)
+// Creates a dataset that contains `rate` elements from the `input_dataset`.
+//
+// Arguments:
+//
+// rate: A scalar representing the sample rate of elements from the `input_dataset`
+// that should be taken.
+// seed: A scalar representing seed of random number generator.
+// seed2: A scalar representing seed2 of random number generator.
+//
+//
+func SamplingDataset(scope *Scope, input_dataset tf.Output, rate tf.Output, seed tf.Output, seed2 tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"output_types": output_types, "output_shapes": output_shapes}
+ opspec := tf.OpSpec{
+ Type: "SamplingDataset",
+ Input: []tf.Input{
+ input_dataset, rate, seed, seed2,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
-// SparseReduceMaxSparseKeepDims sets the optional keep_dims attribute to value.
+// SparseReduceMaxAttr is an optional argument to SparseReduceMax.
+type SparseReduceMaxAttr func(optionalAttr)
+
+// SparseReduceMaxKeepDims sets the optional keep_dims attribute to value.
//
// value: If true, retain reduced dimensions with length 1.
// If not specified, defaults to false
-func SparseReduceMaxSparseKeepDims(value bool) SparseReduceMaxSparseAttr {
+func SparseReduceMaxKeepDims(value bool) SparseReduceMaxAttr {
return func(m optionalAttr) {
m["keep_dims"] = value
}
@@ -14474,8 +14936,8 @@ func SparseReduceMaxSparseKeepDims(value bool) SparseReduceMaxSparseAttr {
// Computes the max of elements across dimensions of a SparseTensor.
//
// This Op takes a SparseTensor and is the sparse counterpart to
-// `tf.reduce_max()`. In contrast to SparseReduceMax, this Op returns a
-// SparseTensor.
+// `tf.reduce_max()`. In particular, this Op also returns a dense `Tensor`
+// instead of a sparse one.
//
// Reduces `sp_input` along the dimensions given in `reduction_axes`. Unless
// `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in
@@ -14492,7 +14954,9 @@ func SparseReduceMaxSparseKeepDims(value bool) SparseReduceMaxSparseAttr {
// input_values: 1-D. `N` non-empty values corresponding to `input_indices`.
// input_shape: 1-D. Shape of the input SparseTensor.
// reduction_axes: 1-D. Length-`K` vector containing the reduction axes.
-func SparseReduceMaxSparse(scope *Scope, input_indices tf.Output, input_values tf.Output, input_shape tf.Output, reduction_axes tf.Output, optional ...SparseReduceMaxSparseAttr) (output_indices tf.Output, output_values tf.Output, output_shape tf.Output) {
+//
+// Returns `R-K`-D. The reduced Tensor.
+func SparseReduceMax(scope *Scope, input_indices tf.Output, input_values tf.Output, input_shape tf.Output, reduction_axes tf.Output, optional ...SparseReduceMaxAttr) (output tf.Output) {
if scope.Err() != nil {
return
}
@@ -14501,167 +14965,68 @@ func SparseReduceMaxSparse(scope *Scope, input_indices tf.Output, input_values t
a(attrs)
}
opspec := tf.OpSpec{
- Type: "SparseReduceMaxSparse",
+ Type: "SparseReduceMax",
Input: []tf.Input{
input_indices, input_values, input_shape, reduction_axes,
},
Attrs: attrs,
}
op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1), op.Output(2)
+ return op.Output(0)
}
-// SampleDistortedBoundingBoxAttr is an optional argument to SampleDistortedBoundingBox.
-type SampleDistortedBoundingBoxAttr func(optionalAttr)
-
-// SampleDistortedBoundingBoxSeed sets the optional seed attribute to value.
+// Advance the counter of a counter-based RNG.
//
-// value: If either `seed` or `seed2` are set to non-zero, the random number
-// generator is seeded by the given `seed`. Otherwise, it is seeded by a random
-// seed.
-// If not specified, defaults to 0
-func SampleDistortedBoundingBoxSeed(value int64) SampleDistortedBoundingBoxAttr {
- return func(m optionalAttr) {
- m["seed"] = value
- }
-}
-
-// SampleDistortedBoundingBoxSeed2 sets the optional seed2 attribute to value.
-//
-// value: A second seed to avoid seed collision.
-// If not specified, defaults to 0
-func SampleDistortedBoundingBoxSeed2(value int64) SampleDistortedBoundingBoxAttr {
- return func(m optionalAttr) {
- m["seed2"] = value
- }
-}
-
-// SampleDistortedBoundingBoxMinObjectCovered sets the optional min_object_covered attribute to value.
-//
-// value: The cropped area of the image must contain at least this
-// fraction of any bounding box supplied. The value of this parameter should be
-// non-negative. In the case of 0, the cropped area does not need to overlap
-// any of the bounding boxes supplied.
-// If not specified, defaults to 0.1
-func SampleDistortedBoundingBoxMinObjectCovered(value float32) SampleDistortedBoundingBoxAttr {
- return func(m optionalAttr) {
- m["min_object_covered"] = value
- }
-}
-
-// SampleDistortedBoundingBoxAspectRatioRange sets the optional aspect_ratio_range attribute to value.
-//
-// value: The cropped area of the image must have an aspect ratio =
-// width / height within this range.
-// If not specified, defaults to
-func SampleDistortedBoundingBoxAspectRatioRange(value []float32) SampleDistortedBoundingBoxAttr {
- return func(m optionalAttr) {
- m["aspect_ratio_range"] = value
- }
-}
-
-// SampleDistortedBoundingBoxAreaRange sets the optional area_range attribute to value.
-//
-// value: The cropped area of the image must contain a fraction of the
-// supplied image within this range.
-// If not specified, defaults to
-func SampleDistortedBoundingBoxAreaRange(value []float32) SampleDistortedBoundingBoxAttr {
- return func(m optionalAttr) {
- m["area_range"] = value
- }
-}
-
-// SampleDistortedBoundingBoxMaxAttempts sets the optional max_attempts attribute to value.
-//
-// value: Number of attempts at generating a cropped region of the image
-// of the specified constraints. After `max_attempts` failures, return the entire
-// image.
-// If not specified, defaults to 100
-func SampleDistortedBoundingBoxMaxAttempts(value int64) SampleDistortedBoundingBoxAttr {
- return func(m optionalAttr) {
- m["max_attempts"] = value
- }
-}
-
-// SampleDistortedBoundingBoxUseImageIfNoBoundingBoxes sets the optional use_image_if_no_bounding_boxes attribute to value.
-//
-// value: Controls behavior if no bounding boxes supplied.
-// If true, assume an implicit bounding box covering the whole input. If false,
-// raise an error.
-// If not specified, defaults to false
-func SampleDistortedBoundingBoxUseImageIfNoBoundingBoxes(value bool) SampleDistortedBoundingBoxAttr {
- return func(m optionalAttr) {
- m["use_image_if_no_bounding_boxes"] = value
- }
-}
-
-// Generate a single randomly distorted bounding box for an image.
-//
-// Bounding box annotations are often supplied in addition to ground-truth labels
-// in image recognition or object localization tasks. A common technique for
-// training such a system is to randomly distort an image while preserving
-// its content, i.e. *data augmentation*. This Op outputs a randomly distorted
-// localization of an object, i.e. bounding box, given an `image_size`,
-// `bounding_boxes` and a series of constraints.
-//
-// The output of this Op is a single bounding box that may be used to crop the
-// original image. The output is returned as 3 tensors: `begin`, `size` and
-// `bboxes`. The first 2 tensors can be fed directly into `tf.slice` to crop the
-// image. The latter may be supplied to `tf.image.draw_bounding_boxes` to visualize
-// what the bounding box looks like.
-//
-// Bounding boxes are supplied and returned as `[y_min, x_min, y_max, x_max]`. The
-// bounding box coordinates are floats in `[0.0, 1.0]` relative to the width and
-// height of the underlying image.
-//
-// For example,
-//
-// ```python
-// # Generate a single distorted bounding box.
-// begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box(
-// tf.shape(image),
-// bounding_boxes=bounding_boxes)
-//
-// # Draw the bounding box in an image summary.
-// image_with_box = tf.image.draw_bounding_boxes(tf.expand_dims(image, 0),
-// bbox_for_draw)
-// tf.summary.image('images_with_box', image_with_box)
-//
-// # Employ the bounding box to distort the image.
-// distorted_image = tf.slice(image, begin, size)
-// ```
-//
-// Note that if no bounding box information is available, setting
-// `use_image_if_no_bounding_boxes = true` will assume there is a single implicit
-// bounding box covering the whole image. If `use_image_if_no_bounding_boxes` is
-// false and no bounding boxes are supplied, an error is raised.
+// The state of the RNG after
+// `rng_skip(n)` will be the same as that after `stateful_uniform([n])`
+// (or any other distribution). The actual increment added to the
+// counter is an unspecified implementation detail.
//
// Arguments:
-// image_size: 1-D, containing `[height, width, channels]`.
-// bounding_boxes: 3-D with shape `[batch, N, 4]` describing the N bounding boxes
-// associated with the image.
+// resource: The handle of the resource variable that stores the state of the RNG.
+// algorithm: The RNG algorithm.
+// delta: The amount of advancement.
//
-// Returns 1-D, containing `[offset_height, offset_width, 0]`. Provide as input to
-// `tf.slice`.1-D, containing `[target_height, target_width, -1]`. Provide as input to
-// `tf.slice`.3-D with shape `[1, 1, 4]` containing the distorted bounding box.
-// Provide as input to `tf.image.draw_bounding_boxes`.
-func SampleDistortedBoundingBox(scope *Scope, image_size tf.Output, bounding_boxes tf.Output, optional ...SampleDistortedBoundingBoxAttr) (begin tf.Output, size tf.Output, bboxes tf.Output) {
+// Returns the created operation.
+func RngSkip(scope *Scope, resource tf.Output, algorithm tf.Output, delta tf.Output) (o *tf.Operation) {
if scope.Err() != nil {
return
}
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
+ opspec := tf.OpSpec{
+ Type: "RngSkip",
+ Input: []tf.Input{
+ resource, algorithm, delta,
+ },
+ }
+ return scope.AddOperation(opspec)
+}
+
+// Computes the reverse mode backpropagated gradient of the Cholesky algorithm.
+//
+// For an explanation see "Differentiation of the Cholesky algorithm" by
+// Iain Murray http://arxiv.org/abs/1602.07527.
+//
+// Arguments:
+// l: Output of batch Cholesky algorithm l = cholesky(A). Shape is `[..., M, M]`.
+// Algorithm depends only on lower triangular part of the innermost matrices of
+// this tensor.
+// grad: df/dl where f is some scalar function. Shape is `[..., M, M]`.
+// Algorithm depends only on lower triangular part of the innermost matrices of
+// this tensor.
+//
+// Returns Symmetrized version of df/dA . Shape is `[..., M, M]`
+func CholeskyGrad(scope *Scope, l tf.Output, grad tf.Output) (output tf.Output) {
+ if scope.Err() != nil {
+ return
}
opspec := tf.OpSpec{
- Type: "SampleDistortedBoundingBox",
+ Type: "CholeskyGrad",
Input: []tf.Input{
- image_size, bounding_boxes,
+ l, grad,
},
- Attrs: attrs,
}
op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1), op.Output(2)
+ return op.Output(0)
}
// Adds up a `SparseTensor` and a dense `Tensor`, producing a dense `Tensor`.
@@ -14687,33 +15052,48 @@ func SparseTensorDenseAdd(scope *Scope, a_indices tf.Output, a_values tf.Output,
return op.Output(0)
}
-// Computes the sum along sparse segments of a tensor divided by the sqrt of N.
-//
-// N is the size of the segment being reduced.
-//
-// Like `SparseSegmentSqrtN`, but allows missing ids in `segment_ids`. If an id is
-// misisng, the `output` tensor at that position will be zeroed.
-//
-// Read
-// [the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation)
-// for an explanation of segments.
+// Transforms a Tensor into a serialized TensorProto proto.
//
// Arguments:
+// tensor: A Tensor of type `T`.
//
-// indices: A 1-D tensor. Has same rank as `segment_ids`.
-// segment_ids: A 1-D tensor. Values should be sorted and can be repeated.
-// num_segments: Should equal the number of distinct segment IDs.
-//
-// Returns Has same shape as data, except for dimension 0 which
-// has size `k`, the number of segments.
-func SparseSegmentSqrtNWithNumSegments(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output, num_segments tf.Output) (output tf.Output) {
+// Returns A serialized TensorProto proto of the input tensor.
+func SerializeTensor(scope *Scope, tensor tf.Output) (serialized tf.Output) {
if scope.Err() != nil {
return
}
opspec := tf.OpSpec{
- Type: "SparseSegmentSqrtNWithNumSegments",
+ Type: "SerializeTensor",
Input: []tf.Input{
- data, indices, segment_ids, num_segments,
+ tensor,
+ },
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// Check if the input matches the regex pattern.
+//
+// The input is a string tensor of any shape. The pattern is a scalar
+// string tensor which is applied to every element of the input tensor.
+// The boolean values (True or False) of the output tensor indicate
+// if the input matches the regex pattern provided.
+//
+// The pattern follows the re2 syntax (https://github.com/google/re2/wiki/Syntax)
+//
+// Arguments:
+// input: A string tensor of the text to be processed.
+// pattern: A scalar string tensor containing the regular expression to match the input.
+//
+// Returns A bool tensor with the same shape as `input`.
+func RegexFullMatch(scope *Scope, input tf.Output, pattern tf.Output) (output tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ opspec := tf.OpSpec{
+ Type: "RegexFullMatch",
+ Input: []tf.Input{
+ input, pattern,
},
}
op := scope.AddOperation(opspec)
@@ -14782,33 +15162,141 @@ func SparseReshape(scope *Scope, input_indices tf.Output, input_shape tf.Output,
return op.Output(0), op.Output(1)
}
-// Computes a range that covers the actual values present in a quantized tensor.
+// Reorders a SparseTensor into the canonical, row-major ordering.
//
-// Given a quantized tensor described by `(input, input_min, input_max)`, outputs a
-// range that covers the actual values present in that tensor. This op is typically
-// used to produce the `requested_output_min` and `requested_output_max` for
-// `Requantize`.
+// Note that by convention, all sparse ops preserve the canonical ordering along
+// increasing dimension number. The only time ordering can be violated is during
+// manual manipulation of the indices and values vectors to add entries.
+//
+// Reordering does not affect the shape of the SparseTensor.
+//
+// If the tensor has rank `R` and `N` non-empty values, `input_indices` has
+// shape `[N, R]`, input_values has length `N`, and input_shape has length `R`.
//
// Arguments:
+// input_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
+// SparseTensor, possibly not in canonical ordering.
+// input_values: 1-D. `N` non-empty values corresponding to `input_indices`.
+// input_shape: 1-D. Shape of the input SparseTensor.
//
-// input_min: The float value that the minimum quantized input value represents.
-// input_max: The float value that the maximum quantized input value represents.
-//
-// Returns The computed min output.the computed max output.
-func RequantizationRange(scope *Scope, input tf.Output, input_min tf.Output, input_max tf.Output) (output_min tf.Output, output_max tf.Output) {
+// Returns 2-D. `N x R` matrix with the same indices as input_indices, but
+// in canonical row-major ordering.1-D. `N` non-empty values corresponding to `output_indices`.
+func SparseReorder(scope *Scope, input_indices tf.Output, input_values tf.Output, input_shape tf.Output) (output_indices tf.Output, output_values tf.Output) {
if scope.Err() != nil {
return
}
opspec := tf.OpSpec{
- Type: "RequantizationRange",
+ Type: "SparseReorder",
Input: []tf.Input{
- input, input_min, input_max,
+ input_indices, input_values, input_shape,
},
}
op := scope.AddOperation(opspec)
return op.Output(0), op.Output(1)
}
+// Quantized Batch normalization.
+//
+// This op is deprecated and will be removed in the future. Prefer
+// `tf.nn.batch_normalization`.
+//
+// Arguments:
+// t: A 4D input Tensor.
+// t_min: The value represented by the lowest quantized input.
+// t_max: The value represented by the highest quantized input.
+// m: A 1D mean Tensor with size matching the last dimension of t.
+// This is the first output from tf.nn.moments,
+// or a saved moving average thereof.
+// m_min: The value represented by the lowest quantized mean.
+// m_max: The value represented by the highest quantized mean.
+// v: A 1D variance Tensor with size matching the last dimension of t.
+// This is the second output from tf.nn.moments,
+// or a saved moving average thereof.
+// v_min: The value represented by the lowest quantized variance.
+// v_max: The value represented by the highest quantized variance.
+// beta: A 1D beta Tensor with size matching the last dimension of t.
+// An offset to be added to the normalized tensor.
+// beta_min: The value represented by the lowest quantized offset.
+// beta_max: The value represented by the highest quantized offset.
+// gamma: A 1D gamma Tensor with size matching the last dimension of t.
+// If "scale_after_normalization" is true, this tensor will be multiplied
+// with the normalized tensor.
+// gamma_min: The value represented by the lowest quantized gamma.
+// gamma_max: The value represented by the highest quantized gamma.
+//
+// variance_epsilon: A small float number to avoid dividing by 0.
+// scale_after_normalization: A bool indicating whether the resulted tensor
+// needs to be multiplied with gamma.
+func QuantizedBatchNormWithGlobalNormalization(scope *Scope, t tf.Output, t_min tf.Output, t_max tf.Output, m tf.Output, m_min tf.Output, m_max tf.Output, v tf.Output, v_min tf.Output, v_max tf.Output, beta tf.Output, beta_min tf.Output, beta_max tf.Output, gamma tf.Output, gamma_min tf.Output, gamma_max tf.Output, out_type tf.DataType, variance_epsilon float32, scale_after_normalization bool) (result tf.Output, result_min tf.Output, result_max tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"out_type": out_type, "variance_epsilon": variance_epsilon, "scale_after_normalization": scale_after_normalization}
+ opspec := tf.OpSpec{
+ Type: "QuantizedBatchNormWithGlobalNormalization",
+ Input: []tf.Input{
+ t, t_min, t_max, m, m_min, m_max, v, v_min, v_max, beta, beta_min, beta_max, gamma, gamma_min, gamma_max,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0), op.Output(1), op.Output(2)
+}
+
+// LoadTPUEmbeddingAdagradParametersAttr is an optional argument to LoadTPUEmbeddingAdagradParameters.
+type LoadTPUEmbeddingAdagradParametersAttr func(optionalAttr)
+
+// LoadTPUEmbeddingAdagradParametersTableId sets the optional table_id attribute to value.
+// If not specified, defaults to -1
+//
+// REQUIRES: value >= -1
+func LoadTPUEmbeddingAdagradParametersTableId(value int64) LoadTPUEmbeddingAdagradParametersAttr {
+ return func(m optionalAttr) {
+ m["table_id"] = value
+ }
+}
+
+// LoadTPUEmbeddingAdagradParametersTableName sets the optional table_name attribute to value.
+// If not specified, defaults to ""
+func LoadTPUEmbeddingAdagradParametersTableName(value string) LoadTPUEmbeddingAdagradParametersAttr {
+ return func(m optionalAttr) {
+ m["table_name"] = value
+ }
+}
+
+// Load Adagrad embedding parameters.
+//
+// An op that loads optimization parameters into HBM for embedding. Must be
+// preceded by a ConfigureTPUEmbeddingHost op that sets up the correct
+// embedding table configuration. For example, this op is used to install
+// parameters that are loaded from a checkpoint before a training loop is
+// executed.
+//
+// Arguments:
+// parameters: Value of parameters used in the Adagrad optimization algorithm.
+// accumulators: Value of accumulators used in the Adagrad optimization algorithm.
+//
+//
+//
+// Returns the created operation.
+func LoadTPUEmbeddingAdagradParameters(scope *Scope, parameters tf.Output, accumulators tf.Output, num_shards int64, shard_id int64, optional ...LoadTPUEmbeddingAdagradParametersAttr) (o *tf.Operation) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"num_shards": num_shards, "shard_id": shard_id}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "LoadTPUEmbeddingAdagradParameters",
+ Input: []tf.Input{
+ parameters, accumulators,
+ },
+ Attrs: attrs,
+ }
+ return scope.AddOperation(opspec)
+}
+
// Slice a `SparseTensor` based on the `start` and `size`.
//
// For example, if the input is
@@ -14919,6 +15407,49 @@ func SparseSplit(scope *Scope, split_dim tf.Output, indices tf.Output, values tf
return output_indices, output_values, output_shape
}
+// DecodeRawAttr is an optional argument to DecodeRaw.
+type DecodeRawAttr func(optionalAttr)
+
+// DecodeRawLittleEndian sets the optional little_endian attribute to value.
+//
+// value: Whether the input `bytes` are in little-endian order.
+// Ignored for `out_type` values that are stored in a single byte like
+// `uint8`.
+// If not specified, defaults to true
+func DecodeRawLittleEndian(value bool) DecodeRawAttr {
+ return func(m optionalAttr) {
+ m["little_endian"] = value
+ }
+}
+
+// Reinterpret the bytes of a string as a vector of numbers.
+//
+// Arguments:
+// bytes: All the elements must have the same length.
+//
+//
+// Returns A Tensor with one more dimension than the input `bytes`. The
+// added dimension will have size equal to the length of the elements
+// of `bytes` divided by the number of bytes to represent `out_type`.
+func DecodeRaw(scope *Scope, bytes tf.Output, out_type tf.DataType, optional ...DecodeRawAttr) (output tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"out_type": out_type}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "DecodeRaw",
+ Input: []tf.Input{
+ bytes,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
// UniqueWithCountsV2Attr is an optional argument to UniqueWithCountsV2.
type UniqueWithCountsV2Attr func(optionalAttr)
@@ -15071,149 +15602,29 @@ func SparseToDense(scope *Scope, sparse_indices tf.Output, output_shape tf.Outpu
return op.Output(0)
}
-// Outputs a `Summary` protocol buffer with scalar values.
+// Forwards `data` to the output port determined by `pred`.
//
-// The input `tags` and `values` must have the same shape. The generated summary
-// has a summary value for each tag-value pair in `tags` and `values`.
+// If `pred` is true, the `data` input is forwarded to `output_true`. Otherwise,
+// the data goes to `output_false`.
+//
+// See also `RefSwitch` and `Merge`.
//
// Arguments:
-// tags: Tags for the summary.
-// values: Same shape as `tags. Values for the summary.
+// data: The tensor to be forwarded to the appropriate output.
+// pred: A scalar that specifies which output port will receive data.
//
-// Returns Scalar. Serialized `Summary` protocol buffer.
-func ScalarSummary(scope *Scope, tags tf.Output, values tf.Output) (summary tf.Output) {
+// Returns If `pred` is false, data will be forwarded to this output.If `pred` is true, data will be forwarded to this output.
+func Switch(scope *Scope, data tf.Output, pred tf.Output) (output_false tf.Output, output_true tf.Output) {
if scope.Err() != nil {
return
}
opspec := tf.OpSpec{
- Type: "ScalarSummary",
+ Type: "Switch",
Input: []tf.Input{
- tags, values,
+ data, pred,
},
}
op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Produces the average pool of the input tensor for quantized types.
-//
-// Arguments:
-// input: 4-D with shape `[batch, height, width, channels]`.
-// min_input: The float value that the lowest quantized input value represents.
-// max_input: The float value that the highest quantized input value represents.
-// ksize: The size of the window for each dimension of the input tensor.
-// The length must be 4 to match the number of dimensions of the input.
-// strides: The stride of the sliding window for each dimension of the input
-// tensor. The length must be 4 to match the number of dimensions of the input.
-// padding: The type of padding algorithm to use.
-//
-// Returns The float value that the lowest quantized output value represents.The float value that the highest quantized output value represents.
-func QuantizedAvgPool(scope *Scope, input tf.Output, min_input tf.Output, max_input tf.Output, ksize []int64, strides []int64, padding string) (output tf.Output, min_output tf.Output, max_output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"ksize": ksize, "strides": strides, "padding": padding}
- opspec := tf.OpSpec{
- Type: "QuantizedAvgPool",
- Input: []tf.Input{
- input, min_input, max_input,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1), op.Output(2)
-}
-
-// TensorArrayV3Attr is an optional argument to TensorArrayV3.
-type TensorArrayV3Attr func(optionalAttr)
-
-// TensorArrayV3ElementShape sets the optional element_shape attribute to value.
-//
-// value: The expected shape of an element, if known. Used to
-// validate the shapes of TensorArray elements. If this shape is not
-// fully specified, gathering zero-size TensorArrays is an error.
-// If not specified, defaults to
-func TensorArrayV3ElementShape(value tf.Shape) TensorArrayV3Attr {
- return func(m optionalAttr) {
- m["element_shape"] = value
- }
-}
-
-// TensorArrayV3DynamicSize sets the optional dynamic_size attribute to value.
-//
-// value: A boolean that determines whether writes to the TensorArray
-// are allowed to grow the size. By default, this is not allowed.
-// If not specified, defaults to false
-func TensorArrayV3DynamicSize(value bool) TensorArrayV3Attr {
- return func(m optionalAttr) {
- m["dynamic_size"] = value
- }
-}
-
-// TensorArrayV3ClearAfterRead sets the optional clear_after_read attribute to value.
-//
-// value: If true (default), Tensors in the TensorArray are cleared
-// after being read. This disables multiple read semantics but allows early
-// release of memory.
-// If not specified, defaults to true
-func TensorArrayV3ClearAfterRead(value bool) TensorArrayV3Attr {
- return func(m optionalAttr) {
- m["clear_after_read"] = value
- }
-}
-
-// TensorArrayV3IdenticalElementShapes sets the optional identical_element_shapes attribute to value.
-//
-// value: If true (default is false), then all
-// elements in the TensorArray will be expected to have have identical shapes.
-// This allows certain behaviors, like dynamically checking for
-// consistent shapes on write, and being able to fill in properly
-// shaped zero tensors on stack -- even if the element_shape attribute
-// is not fully defined.
-// If not specified, defaults to false
-func TensorArrayV3IdenticalElementShapes(value bool) TensorArrayV3Attr {
- return func(m optionalAttr) {
- m["identical_element_shapes"] = value
- }
-}
-
-// TensorArrayV3TensorArrayName sets the optional tensor_array_name attribute to value.
-//
-// value: Overrides the name used for the temporary tensor_array
-// resource. Default value is the name of the 'TensorArray' op (which
-// is guaranteed unique).
-// If not specified, defaults to ""
-func TensorArrayV3TensorArrayName(value string) TensorArrayV3Attr {
- return func(m optionalAttr) {
- m["tensor_array_name"] = value
- }
-}
-
-// An array of Tensors of given size.
-//
-// Write data via Write and read via Read or Pack.
-//
-// Arguments:
-// size: The size of the array.
-// dtype: The type of the elements on the tensor_array.
-//
-// Returns The handle to the TensorArray.A scalar used to control gradient flow.
-func TensorArrayV3(scope *Scope, size tf.Output, dtype tf.DataType, optional ...TensorArrayV3Attr) (handle tf.Output, flow tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"dtype": dtype}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "TensorArrayV3",
- Input: []tf.Input{
- size,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
return op.Output(0), op.Output(1)
}
@@ -15274,97 +15685,167 @@ func RaggedRange(scope *Scope, starts tf.Output, limits tf.Output, deltas tf.Out
return op.Output(0), op.Output(1)
}
-// AddManySparseToTensorsMapAttr is an optional argument to AddManySparseToTensorsMap.
-type AddManySparseToTensorsMapAttr func(optionalAttr)
-
-// AddManySparseToTensorsMapContainer sets the optional container attribute to value.
+// Returns which elements of x are Inf.
//
-// value: The container name for the `SparseTensorsMap` created by this op.
-// If not specified, defaults to ""
-func AddManySparseToTensorsMapContainer(value string) AddManySparseToTensorsMapAttr {
- return func(m optionalAttr) {
- m["container"] = value
- }
-}
-
-// AddManySparseToTensorsMapSharedName sets the optional shared_name attribute to value.
-//
-// value: The shared name for the `SparseTensorsMap` created by this op.
-// If blank, the new Operation's unique name is used.
-// If not specified, defaults to ""
-func AddManySparseToTensorsMapSharedName(value string) AddManySparseToTensorsMapAttr {
- return func(m optionalAttr) {
- m["shared_name"] = value
- }
-}
-
-// Add an `N`-minibatch `SparseTensor` to a `SparseTensorsMap`, return `N` handles.
-//
-// A `SparseTensor` of rank `R` is represented by three tensors: `sparse_indices`,
-// `sparse_values`, and `sparse_shape`, where
-//
-// ```sparse_indices.shape[1] == sparse_shape.shape[0] == R```
-//
-// An `N`-minibatch of `SparseTensor` objects is represented as a `SparseTensor`
-// having a first `sparse_indices` column taking values between `[0, N)`, where
-// the minibatch size `N == sparse_shape[0]`.
-//
-// The input `SparseTensor` must have rank `R` greater than 1, and the first
-// dimension is treated as the minibatch dimension. Elements of the `SparseTensor`
-// must be sorted in increasing order of this first dimension. The stored
-// `SparseTensor` objects pointed to by each row of the output `sparse_handles`
-// will have rank `R-1`.
-//
-// The `SparseTensor` values can then be read out as part of a minibatch by passing
-// the given keys as vector elements to `TakeManySparseFromTensorsMap`. To ensure
-// the correct `SparseTensorsMap` is accessed, ensure that the same
-// `container` and `shared_name` are passed to that Op. If no `shared_name`
-// is provided here, instead use the *name* of the Operation created by calling
-// `AddManySparseToTensorsMap` as the `shared_name` passed to
-// `TakeManySparseFromTensorsMap`. Ensure the Operations are colocated.
-//
-// Arguments:
-// sparse_indices: 2-D. The `indices` of the minibatch `SparseTensor`.
-// `sparse_indices[:, 0]` must be ordered values in `[0, N)`.
-// sparse_values: 1-D. The `values` of the minibatch `SparseTensor`.
-// sparse_shape: 1-D. The `shape` of the minibatch `SparseTensor`.
-// The minibatch size `N == sparse_shape[0]`.
-//
-// Returns 1-D. The handles of the `SparseTensor` now stored in the
-// `SparseTensorsMap`. Shape: `[N]`.
-func AddManySparseToTensorsMap(scope *Scope, sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output, optional ...AddManySparseToTensorsMapAttr) (sparse_handles tf.Output) {
+// @compatibility(numpy)
+// Equivalent to np.isinf
+// @end_compatibility
+func IsInf(scope *Scope, x tf.Output) (y tf.Output) {
if scope.Err() != nil {
return
}
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
opspec := tf.OpSpec{
- Type: "AddManySparseToTensorsMap",
+ Type: "IsInf",
Input: []tf.Input{
- sparse_indices, sparse_values, sparse_shape,
+ x,
},
- Attrs: attrs,
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
-// SumAttr is an optional argument to Sum.
-type SumAttr func(optionalAttr)
+// FractionalMaxPoolAttr is an optional argument to FractionalMaxPool.
+type FractionalMaxPoolAttr func(optionalAttr)
-// SumKeepDims sets the optional keep_dims attribute to value.
+// FractionalMaxPoolPseudoRandom sets the optional pseudo_random attribute to value.
+//
+// value: When set to True, generates the pooling sequence in a
+// pseudorandom fashion, otherwise, in a random fashion. Check paper [Benjamin
+// Graham, Fractional Max-Pooling](http://arxiv.org/abs/1412.6071) for
+// difference between pseudorandom and random.
+// If not specified, defaults to false
+func FractionalMaxPoolPseudoRandom(value bool) FractionalMaxPoolAttr {
+ return func(m optionalAttr) {
+ m["pseudo_random"] = value
+ }
+}
+
+// FractionalMaxPoolOverlapping sets the optional overlapping attribute to value.
+//
+// value: When set to True, it means when pooling, the values at the boundary
+// of adjacent pooling cells are used by both cells. For example:
+//
+// `index 0 1 2 3 4`
+//
+// `value 20 5 16 3 7`
+//
+// If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice.
+// The result would be [20, 16] for fractional max pooling.
+// If not specified, defaults to false
+func FractionalMaxPoolOverlapping(value bool) FractionalMaxPoolAttr {
+ return func(m optionalAttr) {
+ m["overlapping"] = value
+ }
+}
+
+// FractionalMaxPoolDeterministic sets the optional deterministic attribute to value.
+//
+// value: When set to True, a fixed pooling region will be used when
+// iterating over a FractionalMaxPool node in the computation graph. Mainly used
+// in unit test to make FractionalMaxPool deterministic.
+// If not specified, defaults to false
+func FractionalMaxPoolDeterministic(value bool) FractionalMaxPoolAttr {
+ return func(m optionalAttr) {
+ m["deterministic"] = value
+ }
+}
+
+// FractionalMaxPoolSeed sets the optional seed attribute to value.
+//
+// value: If either seed or seed2 are set to be non-zero, the random number
+// generator is seeded by the given seed. Otherwise, it is seeded by a
+// random seed.
+// If not specified, defaults to 0
+func FractionalMaxPoolSeed(value int64) FractionalMaxPoolAttr {
+ return func(m optionalAttr) {
+ m["seed"] = value
+ }
+}
+
+// FractionalMaxPoolSeed2 sets the optional seed2 attribute to value.
+//
+// value: An second seed to avoid seed collision.
+// If not specified, defaults to 0
+func FractionalMaxPoolSeed2(value int64) FractionalMaxPoolAttr {
+ return func(m optionalAttr) {
+ m["seed2"] = value
+ }
+}
+
+// Performs fractional max pooling on the input.
+//
+// Fractional max pooling is slightly different than regular max pooling. In
+// regular max pooling, you downsize an input set by taking the maximum value of
+// smaller N x N subsections of the set (often 2x2), and try to reduce the set by
+// a factor of N, where N is an integer. Fractional max pooling, as you might
+// expect from the word "fractional", means that the overall reduction ratio N
+// does not have to be an integer.
+//
+// The sizes of the pooling regions are generated randomly but are fairly uniform.
+// For example, let's look at the height dimension, and the constraints on the
+// list of rows that will be pool boundaries.
+//
+// First we define the following:
+//
+// 1. input_row_length : the number of rows from the input set
+// 2. output_row_length : which will be smaller than the input
+// 3. alpha = input_row_length / output_row_length : our reduction ratio
+// 4. K = floor(alpha)
+// 5. row_pooling_sequence : this is the result list of pool boundary rows
+//
+// Then, row_pooling_sequence should satisfy:
+//
+// 1. a[0] = 0 : the first value of the sequence is 0
+// 2. a[end] = input_row_length : the last value of the sequence is the size
+// 3. K <= (a[i+1] - a[i]) <= K+1 : all intervals are K or K+1 size
+// 4. length(row_pooling_sequence) = output_row_length+1
+//
+// For more details on fractional max pooling, see this paper:
+// [Benjamin Graham, Fractional Max-Pooling](http://arxiv.org/abs/1412.6071)
+//
+// Arguments:
+// value: 4-D with shape `[batch, height, width, channels]`.
+// pooling_ratio: Pooling ratio for each dimension of `value`, currently only
+// supports row and col dimension and should be >= 1.0. For example, a valid
+// pooling ratio looks like [1.0, 1.44, 1.73, 1.0]. The first and last elements
+// must be 1.0 because we don't allow pooling on batch and channels
+// dimensions. 1.44 and 1.73 are pooling ratio on height and width dimensions
+// respectively.
+//
+// Returns output tensor after fractional max pooling.row pooling sequence, needed to calculate gradient.column pooling sequence, needed to calculate gradient.
+func FractionalMaxPool(scope *Scope, value tf.Output, pooling_ratio []float32, optional ...FractionalMaxPoolAttr) (output tf.Output, row_pooling_sequence tf.Output, col_pooling_sequence tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"pooling_ratio": pooling_ratio}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "FractionalMaxPool",
+ Input: []tf.Input{
+ value,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0), op.Output(1), op.Output(2)
+}
+
+// MinAttr is an optional argument to Min.
+type MinAttr func(optionalAttr)
+
+// MinKeepDims sets the optional keep_dims attribute to value.
//
// value: If true, retain reduced dimensions with length 1.
// If not specified, defaults to false
-func SumKeepDims(value bool) SumAttr {
+func MinKeepDims(value bool) MinAttr {
return func(m optionalAttr) {
m["keep_dims"] = value
}
}
-// Computes the sum of elements across dimensions of a tensor.
+// Computes the minimum of elements across dimensions of a tensor.
//
// Reduces `input` along the dimensions given in `axis`. Unless
// `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in
@@ -15377,7 +15858,7 @@ func SumKeepDims(value bool) SumAttr {
// `[-rank(input), rank(input))`.
//
// Returns The reduced tensor.
-func Sum(scope *Scope, input tf.Output, axis tf.Output, optional ...SumAttr) (output tf.Output) {
+func Min(scope *Scope, input tf.Output, axis tf.Output, optional ...MinAttr) (output tf.Output) {
if scope.Err() != nil {
return
}
@@ -15386,127 +15867,7 @@ func Sum(scope *Scope, input tf.Output, axis tf.Output, optional ...SumAttr) (ou
a(attrs)
}
opspec := tf.OpSpec{
- Type: "Sum",
- Input: []tf.Input{
- input, axis,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// FusedBatchNormGradAttr is an optional argument to FusedBatchNormGrad.
-type FusedBatchNormGradAttr func(optionalAttr)
-
-// FusedBatchNormGradEpsilon sets the optional epsilon attribute to value.
-//
-// value: A small float number added to the variance of x.
-// If not specified, defaults to 0.0001
-func FusedBatchNormGradEpsilon(value float32) FusedBatchNormGradAttr {
- return func(m optionalAttr) {
- m["epsilon"] = value
- }
-}
-
-// FusedBatchNormGradDataFormat sets the optional data_format attribute to value.
-//
-// value: The data format for y_backprop, x, x_backprop.
-// Either "NHWC" (default) or "NCHW".
-// If not specified, defaults to "NHWC"
-func FusedBatchNormGradDataFormat(value string) FusedBatchNormGradAttr {
- return func(m optionalAttr) {
- m["data_format"] = value
- }
-}
-
-// FusedBatchNormGradIsTraining sets the optional is_training attribute to value.
-//
-// value: A bool value to indicate the operation is for training (default)
-// or inference.
-// If not specified, defaults to true
-func FusedBatchNormGradIsTraining(value bool) FusedBatchNormGradAttr {
- return func(m optionalAttr) {
- m["is_training"] = value
- }
-}
-
-// Gradient for batch normalization.
-//
-// Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW".
-// The size of 1D Tensors matches the dimension C of the 4D Tensors.
-//
-// Arguments:
-// y_backprop: A 4D Tensor for the gradient with respect to y.
-// x: A 4D Tensor for input data.
-// scale: A 1D Tensor for scaling factor, to scale the normalized x.
-// reserve_space_1: When is_training is True, a 1D Tensor for the computed batch
-// mean to be reused in gradient computation. When is_training is
-// False, a 1D Tensor for the population mean to be reused in both
-// 1st and 2nd order gradient computation.
-// reserve_space_2: When is_training is True, a 1D Tensor for the computed batch
-// variance (inverted variance in the cuDNN case) to be reused in
-// gradient computation. When is_training is False, a 1D Tensor
-// for the population variance to be reused in both 1st and 2nd
-// order gradient computation.
-//
-// Returns A 4D Tensor for the gradient with respect to x.A 1D Tensor for the gradient with respect to scale.A 1D Tensor for the gradient with respect to offset.Unused placeholder to match the mean input in FusedBatchNorm.Unused placeholder to match the variance input
-// in FusedBatchNorm.
-func FusedBatchNormGrad(scope *Scope, y_backprop tf.Output, x tf.Output, scale tf.Output, reserve_space_1 tf.Output, reserve_space_2 tf.Output, optional ...FusedBatchNormGradAttr) (x_backprop tf.Output, scale_backprop tf.Output, offset_backprop tf.Output, reserve_space_3 tf.Output, reserve_space_4 tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "FusedBatchNormGrad",
- Input: []tf.Input{
- y_backprop, x, scale, reserve_space_1, reserve_space_2,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1), op.Output(2), op.Output(3), op.Output(4)
-}
-
-// MeanAttr is an optional argument to Mean.
-type MeanAttr func(optionalAttr)
-
-// MeanKeepDims sets the optional keep_dims attribute to value.
-//
-// value: If true, retain reduced dimensions with length 1.
-// If not specified, defaults to false
-func MeanKeepDims(value bool) MeanAttr {
- return func(m optionalAttr) {
- m["keep_dims"] = value
- }
-}
-
-// Computes the mean of elements across dimensions of a tensor.
-//
-// Reduces `input` along the dimensions given in `axis`. Unless
-// `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in
-// `axis`. If `keep_dims` is true, the reduced dimensions are
-// retained with length 1.
-//
-// Arguments:
-// input: The tensor to reduce.
-// axis: The dimensions to reduce. Must be in the range
-// `[-rank(input), rank(input))`.
-//
-// Returns The reduced tensor.
-func Mean(scope *Scope, input tf.Output, axis tf.Output, optional ...MeanAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "Mean",
+ Type: "Min",
Input: []tf.Input{
input, axis,
},
@@ -15577,25 +15938,37 @@ func SparseTensorDenseMatMul(scope *Scope, a_indices tf.Output, a_values tf.Outp
return op.Output(0)
}
-// Creates a dataset that contains `rate` elements from the `input_dataset`.
+// LeakyReluGradAttr is an optional argument to LeakyReluGrad.
+type LeakyReluGradAttr func(optionalAttr)
+
+// LeakyReluGradAlpha sets the optional alpha attribute to value.
+// If not specified, defaults to 0.2
+func LeakyReluGradAlpha(value float32) LeakyReluGradAttr {
+ return func(m optionalAttr) {
+ m["alpha"] = value
+ }
+}
+
+// Computes rectified linear gradients for a LeakyRelu operation.
//
// Arguments:
+// gradients: The backpropagated gradients to the corresponding LeakyRelu operation.
+// features: The features passed as input to the corresponding LeakyRelu operation,
+// OR the outputs of that operation (both work equivalently).
//
-// rate: A scalar representing the sample rate of elements from the `input_dataset`
-// that should be taken.
-// seed: A scalar representing seed of random number generator.
-// seed2: A scalar representing seed2 of random number generator.
-//
-//
-func SamplingDataset(scope *Scope, input_dataset tf.Output, rate tf.Output, seed tf.Output, seed2 tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output) {
+// Returns `gradients * (features > 0) + alpha * gradients * (featurs <= 0)`.
+func LeakyReluGrad(scope *Scope, gradients tf.Output, features tf.Output, optional ...LeakyReluGradAttr) (backprops tf.Output) {
if scope.Err() != nil {
return
}
- attrs := map[string]interface{}{"output_types": output_types, "output_shapes": output_shapes}
+ attrs := map[string]interface{}{}
+ for _, a := range optional {
+ a(attrs)
+ }
opspec := tf.OpSpec{
- Type: "SamplingDataset",
+ Type: "LeakyReluGrad",
Input: []tf.Input{
- input_dataset, rate, seed, seed2,
+ gradients, features,
},
Attrs: attrs,
}
@@ -15603,37 +15976,668 @@ func SamplingDataset(scope *Scope, input_dataset tf.Output, rate tf.Output, seed
return op.Output(0)
}
-// PrefetchDatasetAttr is an optional argument to PrefetchDataset.
-type PrefetchDatasetAttr func(optionalAttr)
+// Adds two `SparseTensor` objects to produce another `SparseTensor`.
+//
+// The input `SparseTensor` objects' indices are assumed ordered in standard
+// lexicographic order. If this is not the case, before this step run
+// `SparseReorder` to restore index ordering.
+//
+// By default, if two values sum to zero at some index, the output `SparseTensor`
+// would still include that particular location in its index, storing a zero in the
+// corresponding value slot. To override this, callers can specify `thresh`,
+// indicating that if the sum has a magnitude strictly smaller than `thresh`, its
+// corresponding value and index would then not be included. In particular,
+// `thresh == 0` (default) means everything is kept and actual thresholding happens
+// only for a positive value.
+//
+// In the following shapes, `nnz` is the count after taking `thresh` into account.
+//
+// Arguments:
+// a_indices: 2-D. The `indices` of the first `SparseTensor`, size `[nnz, ndims]` Matrix.
+// a_values: 1-D. The `values` of the first `SparseTensor`, size `[nnz]` Vector.
+// a_shape: 1-D. The `shape` of the first `SparseTensor`, size `[ndims]` Vector.
+// b_indices: 2-D. The `indices` of the second `SparseTensor`, size `[nnz, ndims]` Matrix.
+// b_values: 1-D. The `values` of the second `SparseTensor`, size `[nnz]` Vector.
+// b_shape: 1-D. The `shape` of the second `SparseTensor`, size `[ndims]` Vector.
+// thresh: 0-D. The magnitude threshold that determines if an output value/index
+// pair takes space.
+func SparseAdd(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, b_indices tf.Output, b_values tf.Output, b_shape tf.Output, thresh tf.Output) (sum_indices tf.Output, sum_values tf.Output, sum_shape tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ opspec := tf.OpSpec{
+ Type: "SparseAdd",
+ Input: []tf.Input{
+ a_indices, a_values, a_shape, b_indices, b_values, b_shape, thresh,
+ },
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0), op.Output(1), op.Output(2)
+}
-// PrefetchDatasetSlackPeriod sets the optional slack_period attribute to value.
+// Creates an Optional variant with no value.
+func OptionalNone(scope *Scope) (optional tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ opspec := tf.OpSpec{
+ Type: "OptionalNone",
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// Concatenates tensors along one dimension.
+//
+// Arguments:
+// concat_dim: 0-D. The dimension along which to concatenate. Must be in the
+// range [0, rank(values)).
+// values: The `N` Tensors to concatenate. Their ranks and types must match,
+// and their sizes must match in all dimensions except `concat_dim`.
+//
+// Returns A `Tensor` with the concatenation of values stacked along the
+// `concat_dim` dimension. This tensor's shape matches that of `values` except
+// in `concat_dim` where it has the sum of the sizes.
+func Concat(scope *Scope, concat_dim tf.Output, values []tf.Output) (output tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ opspec := tf.OpSpec{
+ Type: "Concat",
+ Input: []tf.Input{
+ concat_dim, tf.OutputList(values),
+ },
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// RetrieveTPUEmbeddingADAMParametersGradAccumDebugAttr is an optional argument to RetrieveTPUEmbeddingADAMParametersGradAccumDebug.
+type RetrieveTPUEmbeddingADAMParametersGradAccumDebugAttr func(optionalAttr)
+
+// RetrieveTPUEmbeddingADAMParametersGradAccumDebugTableId sets the optional table_id attribute to value.
+// If not specified, defaults to -1
+//
+// REQUIRES: value >= -1
+func RetrieveTPUEmbeddingADAMParametersGradAccumDebugTableId(value int64) RetrieveTPUEmbeddingADAMParametersGradAccumDebugAttr {
+ return func(m optionalAttr) {
+ m["table_id"] = value
+ }
+}
+
+// RetrieveTPUEmbeddingADAMParametersGradAccumDebugTableName sets the optional table_name attribute to value.
+// If not specified, defaults to ""
+func RetrieveTPUEmbeddingADAMParametersGradAccumDebugTableName(value string) RetrieveTPUEmbeddingADAMParametersGradAccumDebugAttr {
+ return func(m optionalAttr) {
+ m["table_name"] = value
+ }
+}
+
+// Retrieve ADAM embedding parameters with debug support.
+//
+// An op that retrieves optimization parameters from embedding to host
+// memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up
+// the correct embedding table configuration. For example, this op is
+// used to retrieve updated parameters before saving a checkpoint.
+//
+// Returns Parameter parameters updated by the ADAM optimization algorithm.Parameter momenta updated by the ADAM optimization algorithm.Parameter velocities updated by the ADAM optimization algorithm.Parameter gradient_accumulators updated by the ADAM optimization algorithm.
+func RetrieveTPUEmbeddingADAMParametersGradAccumDebug(scope *Scope, num_shards int64, shard_id int64, optional ...RetrieveTPUEmbeddingADAMParametersGradAccumDebugAttr) (parameters tf.Output, momenta tf.Output, velocities tf.Output, gradient_accumulators tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"num_shards": num_shards, "shard_id": shard_id}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "RetrieveTPUEmbeddingADAMParametersGradAccumDebug",
+
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0), op.Output(1), op.Output(2), op.Output(3)
+}
+
+// TensorArrayGatherV2Attr is an optional argument to TensorArrayGatherV2.
+type TensorArrayGatherV2Attr func(optionalAttr)
+
+// TensorArrayGatherV2ElementShape sets the optional element_shape attribute to value.
+// If not specified, defaults to
+func TensorArrayGatherV2ElementShape(value tf.Shape) TensorArrayGatherV2Attr {
+ return func(m optionalAttr) {
+ m["element_shape"] = value
+ }
+}
+
+// Deprecated. Use TensorArrayGatherV3
+//
+// DEPRECATED at GraphDef version 26: Use TensorArrayGatherV3
+func TensorArrayGatherV2(scope *Scope, handle tf.Output, indices tf.Output, flow_in tf.Output, dtype tf.DataType, optional ...TensorArrayGatherV2Attr) (value tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"dtype": dtype}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "TensorArrayGatherV2",
+ Input: []tf.Input{
+ handle, indices, flow_in,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// RetrieveTPUEmbeddingMomentumParametersGradAccumDebugAttr is an optional argument to RetrieveTPUEmbeddingMomentumParametersGradAccumDebug.
+type RetrieveTPUEmbeddingMomentumParametersGradAccumDebugAttr func(optionalAttr)
+
+// RetrieveTPUEmbeddingMomentumParametersGradAccumDebugTableId sets the optional table_id attribute to value.
+// If not specified, defaults to -1
+//
+// REQUIRES: value >= -1
+func RetrieveTPUEmbeddingMomentumParametersGradAccumDebugTableId(value int64) RetrieveTPUEmbeddingMomentumParametersGradAccumDebugAttr {
+ return func(m optionalAttr) {
+ m["table_id"] = value
+ }
+}
+
+// RetrieveTPUEmbeddingMomentumParametersGradAccumDebugTableName sets the optional table_name attribute to value.
+// If not specified, defaults to ""
+func RetrieveTPUEmbeddingMomentumParametersGradAccumDebugTableName(value string) RetrieveTPUEmbeddingMomentumParametersGradAccumDebugAttr {
+ return func(m optionalAttr) {
+ m["table_name"] = value
+ }
+}
+
+// Retrieve Momentum embedding parameters with debug support.
+//
+// An op that retrieves optimization parameters from embedding to host
+// memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up
+// the correct embedding table configuration. For example, this op is
+// used to retrieve updated parameters before saving a checkpoint.
+//
+// Returns Parameter parameters updated by the Momentum optimization algorithm.Parameter momenta updated by the Momentum optimization algorithm.Parameter gradient_accumulators updated by the Momentum optimization algorithm.
+func RetrieveTPUEmbeddingMomentumParametersGradAccumDebug(scope *Scope, num_shards int64, shard_id int64, optional ...RetrieveTPUEmbeddingMomentumParametersGradAccumDebugAttr) (parameters tf.Output, momenta tf.Output, gradient_accumulators tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"num_shards": num_shards, "shard_id": shard_id}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "RetrieveTPUEmbeddingMomentumParametersGradAccumDebug",
+
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0), op.Output(1), op.Output(2)
+}
+
+// PaddedBatchDatasetV2Attr is an optional argument to PaddedBatchDatasetV2.
+type PaddedBatchDatasetV2Attr func(optionalAttr)
+
+// PaddedBatchDatasetV2ParallelCopy sets the optional parallel_copy attribute to value.
+// If not specified, defaults to false
+func PaddedBatchDatasetV2ParallelCopy(value bool) PaddedBatchDatasetV2Attr {
+ return func(m optionalAttr) {
+ m["parallel_copy"] = value
+ }
+}
+
+// Creates a dataset that batches and pads `batch_size` elements from the input.
+//
+// Arguments:
+//
+// batch_size: A scalar representing the number of elements to accumulate in a
+// batch.
+// padded_shapes: A list of int64 tensors representing the desired padded shapes
+// of the corresponding output components. These shapes may be partially
+// specified, using `-1` to indicate that a particular dimension should be
+// padded to the maximum size of all batch elements.
+// padding_values: A list of scalars containing the padding value to use for
+// each of the outputs.
+// drop_remainder: A scalar representing whether the last batch should be dropped in case its size
+// is smaller than desired.
+//
+func PaddedBatchDatasetV2(scope *Scope, input_dataset tf.Output, batch_size tf.Output, padded_shapes []tf.Output, padding_values []tf.Output, drop_remainder tf.Output, output_shapes []tf.Shape, optional ...PaddedBatchDatasetV2Attr) (handle tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"output_shapes": output_shapes}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "PaddedBatchDatasetV2",
+ Input: []tf.Input{
+ input_dataset, batch_size, tf.OutputList(padded_shapes), tf.OutputList(padding_values), drop_remainder,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// RetrieveTPUEmbeddingAdagradParametersGradAccumDebugAttr is an optional argument to RetrieveTPUEmbeddingAdagradParametersGradAccumDebug.
+type RetrieveTPUEmbeddingAdagradParametersGradAccumDebugAttr func(optionalAttr)
+
+// RetrieveTPUEmbeddingAdagradParametersGradAccumDebugTableId sets the optional table_id attribute to value.
+// If not specified, defaults to -1
+//
+// REQUIRES: value >= -1
+func RetrieveTPUEmbeddingAdagradParametersGradAccumDebugTableId(value int64) RetrieveTPUEmbeddingAdagradParametersGradAccumDebugAttr {
+ return func(m optionalAttr) {
+ m["table_id"] = value
+ }
+}
+
+// RetrieveTPUEmbeddingAdagradParametersGradAccumDebugTableName sets the optional table_name attribute to value.
+// If not specified, defaults to ""
+func RetrieveTPUEmbeddingAdagradParametersGradAccumDebugTableName(value string) RetrieveTPUEmbeddingAdagradParametersGradAccumDebugAttr {
+ return func(m optionalAttr) {
+ m["table_name"] = value
+ }
+}
+
+// Retrieve Adagrad embedding parameters with debug support.
+//
+// An op that retrieves optimization parameters from embedding to host
+// memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up
+// the correct embedding table configuration. For example, this op is
+// used to retrieve updated parameters before saving a checkpoint.
+//
+// Returns Parameter parameters updated by the Adagrad optimization algorithm.Parameter accumulators updated by the Adagrad optimization algorithm.Parameter gradient_accumulators updated by the Adagrad optimization algorithm.
+func RetrieveTPUEmbeddingAdagradParametersGradAccumDebug(scope *Scope, num_shards int64, shard_id int64, optional ...RetrieveTPUEmbeddingAdagradParametersGradAccumDebugAttr) (parameters tf.Output, accumulators tf.Output, gradient_accumulators tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"num_shards": num_shards, "shard_id": shard_id}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "RetrieveTPUEmbeddingAdagradParametersGradAccumDebug",
+
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0), op.Output(1), op.Output(2)
+}
+
+// CollectiveReduceAttr is an optional argument to CollectiveReduce.
+type CollectiveReduceAttr func(optionalAttr)
+
+// CollectiveReduceWaitFor sets the optional wait_for attribute to value.
+// If not specified, defaults to <>
+func CollectiveReduceWaitFor(value []int64) CollectiveReduceAttr {
+ return func(m optionalAttr) {
+ m["wait_for"] = value
+ }
+}
+
+// Mutually reduces multiple tensors of identical type and shape.
+func CollectiveReduce(scope *Scope, input tf.Output, group_size int64, group_key int64, instance_key int64, merge_op string, final_op string, subdiv_offsets []int64, optional ...CollectiveReduceAttr) (data tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"group_size": group_size, "group_key": group_key, "instance_key": instance_key, "merge_op": merge_op, "final_op": final_op, "subdiv_offsets": subdiv_offsets}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "CollectiveReduce",
+ Input: []tf.Input{
+ input,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// LoadTPUEmbeddingMDLAdagradLightParametersAttr is an optional argument to LoadTPUEmbeddingMDLAdagradLightParameters.
+type LoadTPUEmbeddingMDLAdagradLightParametersAttr func(optionalAttr)
+
+// LoadTPUEmbeddingMDLAdagradLightParametersTableId sets the optional table_id attribute to value.
+// If not specified, defaults to -1
+//
+// REQUIRES: value >= -1
+func LoadTPUEmbeddingMDLAdagradLightParametersTableId(value int64) LoadTPUEmbeddingMDLAdagradLightParametersAttr {
+ return func(m optionalAttr) {
+ m["table_id"] = value
+ }
+}
+
+// LoadTPUEmbeddingMDLAdagradLightParametersTableName sets the optional table_name attribute to value.
+// If not specified, defaults to ""
+func LoadTPUEmbeddingMDLAdagradLightParametersTableName(value string) LoadTPUEmbeddingMDLAdagradLightParametersAttr {
+ return func(m optionalAttr) {
+ m["table_name"] = value
+ }
+}
+
+// Load MDL Adagrad Light embedding parameters.
+//
+// An op that loads optimization parameters into HBM for embedding. Must be
+// preceded by a ConfigureTPUEmbeddingHost op that sets up the correct
+// embedding table configuration. For example, this op is used to install
+// parameters that are loaded from a checkpoint before a training loop is
+// executed.
+//
+// Arguments:
+// parameters: Value of parameters used in the MDL Adagrad Light optimization algorithm.
+// accumulators: Value of accumulators used in the MDL Adagrad Light optimization algorithm.
+// weights: Value of weights used in the MDL Adagrad Light optimization algorithm.
+// benefits: Value of benefits used in the MDL Adagrad Light optimization algorithm.
+//
+//
+//
+// Returns the created operation.
+func LoadTPUEmbeddingMDLAdagradLightParameters(scope *Scope, parameters tf.Output, accumulators tf.Output, weights tf.Output, benefits tf.Output, num_shards int64, shard_id int64, optional ...LoadTPUEmbeddingMDLAdagradLightParametersAttr) (o *tf.Operation) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"num_shards": num_shards, "shard_id": shard_id}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "LoadTPUEmbeddingMDLAdagradLightParameters",
+ Input: []tf.Input{
+ parameters, accumulators, weights, benefits,
+ },
+ Attrs: attrs,
+ }
+ return scope.AddOperation(opspec)
+}
+
+// ResourceScatterNdUpdateAttr is an optional argument to ResourceScatterNdUpdate.
+type ResourceScatterNdUpdateAttr func(optionalAttr)
+
+// ResourceScatterNdUpdateUseLocking sets the optional use_locking attribute to value.
+//
+// value: An optional bool. Defaults to True. If True, the assignment will
+// be protected by a lock; otherwise the behavior is undefined,
+// but may exhibit less contention.
+// If not specified, defaults to true
+func ResourceScatterNdUpdateUseLocking(value bool) ResourceScatterNdUpdateAttr {
+ return func(m optionalAttr) {
+ m["use_locking"] = value
+ }
+}
+
+// Applies sparse `updates` to individual values or slices within a given
+//
+// variable according to `indices`.
+//
+// `ref` is a `Tensor` with rank `P` and `indices` is a `Tensor` of rank `Q`.
+//
+// `indices` must be integer tensor, containing indices into `ref`.
+// It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`.
+//
+// The innermost dimension of `indices` (with length `K`) corresponds to
+// indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th
+// dimension of `ref`.
+//
+// `updates` is `Tensor` of rank `Q-1+P-K` with shape:
+//
+// ```
+// [d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]].
+// ```
+//
+// For example, say we want to update 4 scattered elements to a rank-1 tensor to
+// 8 elements. In Python, that update would look like this:
+//
+// ```python
+// ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8])
+// indices = tf.constant([[4], [3], [1] ,[7]])
+// updates = tf.constant([9, 10, 11, 12])
+// update = tf.scatter_nd_update(ref, indices, updates)
+// with tf.Session() as sess:
+// print sess.run(update)
+// ```
+//
+// The resulting update to ref would look like this:
+//
+// [1, 11, 3, 10, 9, 6, 7, 12]
+//
+// See `tf.scatter_nd` for more details about how to make updates to
+// slices.
+//
+// Arguments:
+// ref: A resource handle. Must be from a VarHandleOp.
+// indices: A Tensor. Must be one of the following types: int32, int64.
+// A tensor of indices into ref.
+// updates: A Tensor. Must have the same type as ref. A tensor of updated
+// values to add to ref.
+//
+// Returns the created operation.
+func ResourceScatterNdUpdate(scope *Scope, ref tf.Output, indices tf.Output, updates tf.Output, optional ...ResourceScatterNdUpdateAttr) (o *tf.Operation) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "ResourceScatterNdUpdate",
+ Input: []tf.Input{
+ ref, indices, updates,
+ },
+ Attrs: attrs,
+ }
+ return scope.AddOperation(opspec)
+}
+
+// CudnnRNNBackpropV3Attr is an optional argument to CudnnRNNBackpropV3.
+type CudnnRNNBackpropV3Attr func(optionalAttr)
+
+// CudnnRNNBackpropV3RnnMode sets the optional rnn_mode attribute to value.
+// If not specified, defaults to "lstm"
+func CudnnRNNBackpropV3RnnMode(value string) CudnnRNNBackpropV3Attr {
+ return func(m optionalAttr) {
+ m["rnn_mode"] = value
+ }
+}
+
+// CudnnRNNBackpropV3InputMode sets the optional input_mode attribute to value.
+// If not specified, defaults to "linear_input"
+func CudnnRNNBackpropV3InputMode(value string) CudnnRNNBackpropV3Attr {
+ return func(m optionalAttr) {
+ m["input_mode"] = value
+ }
+}
+
+// CudnnRNNBackpropV3Direction sets the optional direction attribute to value.
+// If not specified, defaults to "unidirectional"
+func CudnnRNNBackpropV3Direction(value string) CudnnRNNBackpropV3Attr {
+ return func(m optionalAttr) {
+ m["direction"] = value
+ }
+}
+
+// CudnnRNNBackpropV3Dropout sets the optional dropout attribute to value.
// If not specified, defaults to 0
-func PrefetchDatasetSlackPeriod(value int64) PrefetchDatasetAttr {
+func CudnnRNNBackpropV3Dropout(value float32) CudnnRNNBackpropV3Attr {
return func(m optionalAttr) {
- m["slack_period"] = value
+ m["dropout"] = value
}
}
-// Creates a dataset that asynchronously prefetches elements from `input_dataset`.
+// CudnnRNNBackpropV3Seed sets the optional seed attribute to value.
+// If not specified, defaults to 0
+func CudnnRNNBackpropV3Seed(value int64) CudnnRNNBackpropV3Attr {
+ return func(m optionalAttr) {
+ m["seed"] = value
+ }
+}
+
+// CudnnRNNBackpropV3Seed2 sets the optional seed2 attribute to value.
+// If not specified, defaults to 0
+func CudnnRNNBackpropV3Seed2(value int64) CudnnRNNBackpropV3Attr {
+ return func(m optionalAttr) {
+ m["seed2"] = value
+ }
+}
+
+// CudnnRNNBackpropV3TimeMajor sets the optional time_major attribute to value.
+// If not specified, defaults to true
+func CudnnRNNBackpropV3TimeMajor(value bool) CudnnRNNBackpropV3Attr {
+ return func(m optionalAttr) {
+ m["time_major"] = value
+ }
+}
+
+// Backprop step of CudnnRNNV3.
//
-// Arguments:
+// Compute the backprop of both data and weights in a RNN. Takes an extra
+// "sequence_lengths" input than CudnnRNNBackprop.
//
-// buffer_size: The maximum number of elements to buffer in an iterator over
-// this dataset.
-//
-//
-func PrefetchDataset(scope *Scope, input_dataset tf.Output, buffer_size tf.Output, output_types []tf.DataType, output_shapes []tf.Shape, optional ...PrefetchDatasetAttr) (handle tf.Output) {
+// rnn_mode: Indicates the type of the RNN model.
+// input_mode: Indicates whether there is a linear projection between the input and
+// the actual computation before the first layer. 'skip_input' is only allowed
+// when input_size == num_units; 'auto_select' implies 'skip_input' when
+// input_size == num_units; otherwise, it implies 'linear_input'.
+// direction: Indicates whether a bidirectional model will be used. Should be
+// "unidirectional" or "bidirectional".
+// dropout: Dropout probability. When set to 0., dropout is disabled.
+// seed: The 1st part of a seed to initialize dropout.
+// seed2: The 2nd part of a seed to initialize dropout.
+// input: If time_major is true, this is a 3-D tensor with the shape of
+// [seq_length, batch_size, input_size]. If time_major is false, the shape is
+// [batch_size, seq_length, input_size].
+// input_h: If time_major is true, this is a 3-D tensor with the shape of
+// [num_layer * dir, batch_size, num_units]. If time_major is false, the shape
+// is [batch_size, num_layer * dir, num_units].
+// input_c: For LSTM, a 3-D tensor with the shape of
+// [num_layer * dir, batch, num_units]. For other models, it is ignored.
+// params: A 1-D tensor that contains the weights and biases in an opaque layout.
+// The size must be created through CudnnRNNParamsSize, and initialized
+// separately. Note that they might not be compatible across different
+// generations. So it is a good idea to save and restore
+// sequence_lengths: a vector of lengths of each input sequence.
+// output: If time_major is true, this is a 3-D tensor with the shape of
+// [seq_length, batch_size, dir * num_units]. If time_major is false, the
+// shape is [batch_size, seq_length, dir * num_units].
+// output_h: The same shape has input_h.
+// output_c: The same shape as input_c for LSTM. An empty tensor for other models.
+// output_backprop: A 3-D tensor with the same shape as output in the forward pass.
+// output_h_backprop: A 3-D tensor with the same shape as output_h in the forward
+// pass.
+// output_c_backprop: A 3-D tensor with the same shape as output_c in the forward
+// pass.
+// time_major: Indicates whether the input/output format is time major or batch
+// major.
+// reserve_space: The same reserve_space produced in the forward operation.
+// input_backprop: The backprop to input in the forward pass. Has the same shape
+// as input.
+// input_h_backprop: The backprop to input_h in the forward pass. Has the same
+// shape as input_h.
+// input_c_backprop: The backprop to input_c in the forward pass. Has the same
+// shape as input_c.
+// params_backprop: The backprop to the params buffer in the forward pass. Has the
+// same shape as params.
+func CudnnRNNBackpropV3(scope *Scope, input tf.Output, input_h tf.Output, input_c tf.Output, params tf.Output, sequence_lengths tf.Output, output tf.Output, output_h tf.Output, output_c tf.Output, output_backprop tf.Output, output_h_backprop tf.Output, output_c_backprop tf.Output, reserve_space tf.Output, host_reserved tf.Output, optional ...CudnnRNNBackpropV3Attr) (input_backprop tf.Output, input_h_backprop tf.Output, input_c_backprop tf.Output, params_backprop tf.Output) {
if scope.Err() != nil {
return
}
- attrs := map[string]interface{}{"output_types": output_types, "output_shapes": output_shapes}
+ attrs := map[string]interface{}{}
for _, a := range optional {
a(attrs)
}
opspec := tf.OpSpec{
- Type: "PrefetchDataset",
+ Type: "CudnnRNNBackpropV3",
Input: []tf.Input{
- input_dataset, buffer_size,
+ input, input_h, input_c, params, sequence_lengths, output, output_h, output_c, output_backprop, output_h_backprop, output_c_backprop, reserve_space, host_reserved,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0), op.Output(1), op.Output(2), op.Output(3)
+}
+
+// RetrieveTPUEmbeddingAdagradParametersAttr is an optional argument to RetrieveTPUEmbeddingAdagradParameters.
+type RetrieveTPUEmbeddingAdagradParametersAttr func(optionalAttr)
+
+// RetrieveTPUEmbeddingAdagradParametersTableId sets the optional table_id attribute to value.
+// If not specified, defaults to -1
+//
+// REQUIRES: value >= -1
+func RetrieveTPUEmbeddingAdagradParametersTableId(value int64) RetrieveTPUEmbeddingAdagradParametersAttr {
+ return func(m optionalAttr) {
+ m["table_id"] = value
+ }
+}
+
+// RetrieveTPUEmbeddingAdagradParametersTableName sets the optional table_name attribute to value.
+// If not specified, defaults to ""
+func RetrieveTPUEmbeddingAdagradParametersTableName(value string) RetrieveTPUEmbeddingAdagradParametersAttr {
+ return func(m optionalAttr) {
+ m["table_name"] = value
+ }
+}
+
+// Retrieve Adagrad embedding parameters.
+//
+// An op that retrieves optimization parameters from embedding to host
+// memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up
+// the correct embedding table configuration. For example, this op is
+// used to retrieve updated parameters before saving a checkpoint.
+//
+// Returns Parameter parameters updated by the Adagrad optimization algorithm.Parameter accumulators updated by the Adagrad optimization algorithm.
+func RetrieveTPUEmbeddingAdagradParameters(scope *Scope, num_shards int64, shard_id int64, optional ...RetrieveTPUEmbeddingAdagradParametersAttr) (parameters tf.Output, accumulators tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"num_shards": num_shards, "shard_id": shard_id}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "RetrieveTPUEmbeddingAdagradParameters",
+
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0), op.Output(1)
+}
+
+// Bucketizes 'input' based on 'boundaries'.
+//
+// For example, if the inputs are
+// boundaries = [0, 10, 100]
+// input = [[-5, 10000]
+// [150, 10]
+// [5, 100]]
+//
+// then the output will be
+// output = [[0, 3]
+// [3, 2]
+// [1, 3]]
+//
+// Arguments:
+// input: Any shape of Tensor contains with int or float type.
+// boundaries: A sorted list of floats gives the boundary of the buckets.
+//
+// Returns Same shape with 'input', each value of input replaced with bucket index.
+//
+// @compatibility(numpy)
+// Equivalent to np.digitize.
+// @end_compatibility
+func Bucketize(scope *Scope, input tf.Output, boundaries []float32) (output tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"boundaries": boundaries}
+ opspec := tf.OpSpec{
+ Type: "Bucketize",
+ Input: []tf.Input{
+ input,
},
Attrs: attrs,
}
@@ -15641,64 +16645,500 @@ func PrefetchDataset(scope *Scope, input_dataset tf.Output, buffer_size tf.Outpu
return op.Output(0)
}
-// Conv3DAttr is an optional argument to Conv3D.
-type Conv3DAttr func(optionalAttr)
-
-// Conv3DDataFormat sets the optional data_format attribute to value.
-//
-// value: The data format of the input and output data. With the
-// default format "NDHWC", the data is stored in the order of:
-// [batch, in_depth, in_height, in_width, in_channels].
-// Alternatively, the format could be "NCDHW", the data storage order is:
-// [batch, in_channels, in_depth, in_height, in_width].
-// If not specified, defaults to "NDHWC"
-func Conv3DDataFormat(value string) Conv3DAttr {
- return func(m optionalAttr) {
- m["data_format"] = value
- }
-}
-
-// Conv3DDilations sets the optional dilations attribute to value.
-//
-// value: 1-D tensor of length 5. The dilation factor for each dimension of
-// `input`. If set to k > 1, there will be k-1 skipped cells between each
-// filter element on that dimension. The dimension order is determined by the
-// value of `data_format`, see above for details. Dilations in the batch and
-// depth dimensions must be 1.
-// If not specified, defaults to
-func Conv3DDilations(value []int64) Conv3DAttr {
- return func(m optionalAttr) {
- m["dilations"] = value
- }
-}
-
-// Computes a 3-D convolution given 5-D `input` and `filter` tensors.
-//
-// In signal processing, cross-correlation is a measure of similarity of
-// two waveforms as a function of a time-lag applied to one of them. This
-// is also known as a sliding dot product or sliding inner-product.
-//
-// Our Conv3D implements a form of cross-correlation.
+// A placeholder op for a value that will be fed into the computation.
//
// Arguments:
-// input: Shape `[batch, in_depth, in_height, in_width, in_channels]`.
-// filter: Shape `[filter_depth, filter_height, filter_width, in_channels,
-// out_channels]`. `in_channels` must match between `input` and `filter`.
-// strides: 1-D tensor of length 5. The stride of the sliding window for each
-// dimension of `input`. Must have `strides[0] = strides[4] = 1`.
-// padding: The type of padding algorithm to use.
-func Conv3D(scope *Scope, input tf.Output, filter tf.Output, strides []int64, padding string, optional ...Conv3DAttr) (output tf.Output) {
+// dtype: The type of elements in the tensor.
+// shape: The shape of the tensor.
+//
+// Returns A tensor that will be provided using the infeed mechanism.
+func InfeedDequeue(scope *Scope, dtype tf.DataType, shape tf.Shape) (output tf.Output) {
if scope.Err() != nil {
return
}
- attrs := map[string]interface{}{"strides": strides, "padding": padding}
+ attrs := map[string]interface{}{"dtype": dtype, "shape": shape}
+ opspec := tf.OpSpec{
+ Type: "InfeedDequeue",
+
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// Scatter `updates` into a new tensor according to `indices`.
+//
+// Creates a new tensor by applying sparse `updates` to individual values or
+// slices within a tensor (initially zero for numeric, empty for string) of
+// the given `shape` according to indices. This operator is the inverse of the
+// `tf.gather_nd` operator which extracts values or slices from a given tensor.
+//
+// This operation is similar to tensor_scatter_add, except that the tensor is
+// zero-initialized. Calling `tf.scatter_nd(indices, values, shape)` is identical
+// to `tensor_scatter_add(tf.zeros(shape, values.dtype), indices, values)`
+//
+// If `indices` contains duplicates, then their updates are accumulated (summed).
+//
+// **WARNING**: The order in which updates are applied is nondeterministic, so the
+// output will be nondeterministic if `indices` contains duplicates -- because
+// of some numerical approximation issues, numbers summed in different order
+// may yield different results.
+//
+// `indices` is an integer tensor containing indices into a new tensor of shape
+// `shape`. The last dimension of `indices` can be at most the rank of `shape`:
+//
+// indices.shape[-1] <= shape.rank
+//
+// The last dimension of `indices` corresponds to indices into elements
+// (if `indices.shape[-1] = shape.rank`) or slices
+// (if `indices.shape[-1] < shape.rank`) along dimension `indices.shape[-1]` of
+// `shape`. `updates` is a tensor with shape
+//
+// indices.shape[:-1] + shape[indices.shape[-1]:]
+//
+// The simplest form of scatter is to insert individual elements in a tensor by
+// index. For example, say we want to insert 4 scattered elements in a rank-1
+// tensor with 8 elements.
+//
+//
+//
+//
+//
+//
+//
+//
-//
-//
-//
-//
-//
-//
-//
-//
+//
+//
+//
+//
+//
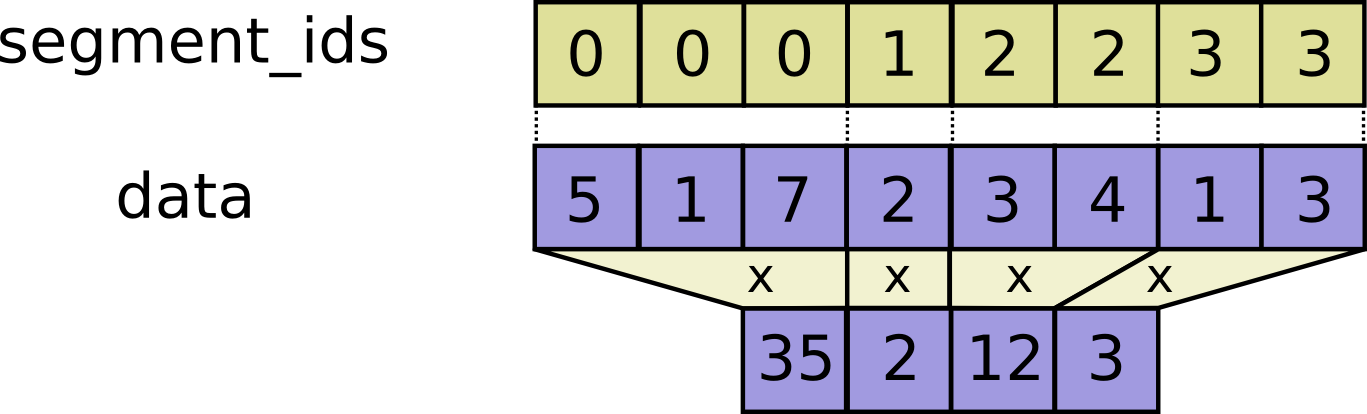
+//
+// Shai Shalev-Shwartz, Tong Zhang. 2012
+//
+// $$Loss Objective = \sum f_{i} (wx_{i}) + (l2 / 2) * |w|^2 + l1 * |w|$$
+//
+// [Adding vs. Averaging in Distributed Primal-Dual Optimization](http://arxiv.org/abs/1502.03508).
+// Chenxin Ma, Virginia Smith, Martin Jaggi, Michael I. Jordan,
+// Peter Richtarik, Martin Takac. 2015
+//
+// [Stochastic Dual Coordinate Ascent with Adaptive Probabilities](https://arxiv.org/abs/1502.08053).
+// Dominik Csiba, Zheng Qu, Peter Richtarik. 2015
+//
+// Arguments:
+// sparse_example_indices: a list of vectors which contain example indices.
+// sparse_feature_indices: a list of vectors which contain feature indices.
+// sparse_feature_values: a list of vectors which contains feature value
+// associated with each feature group.
+// dense_features: a list of matrices which contains the dense feature values.
+// example_weights: a vector which contains the weight associated with each
+// example.
+// example_labels: a vector which contains the label/target associated with each
+// example.
+// sparse_indices: a list of vectors where each value is the indices which has
+// corresponding weights in sparse_weights. This field maybe omitted for the
+// dense approach.
+// sparse_weights: a list of vectors where each value is the weight associated with
+// a sparse feature group.
+// dense_weights: a list of vectors where the values are the weights associated
+// with a dense feature group.
+// example_state_data: a list of vectors containing the example state data.
+// loss_type: Type of the primal loss. Currently SdcaSolver supports logistic,
+// squared and hinge losses.
+// l1: Symmetric l1 regularization strength.
+// l2: Symmetric l2 regularization strength.
+// num_loss_partitions: Number of partitions of the global loss function.
+// num_inner_iterations: Number of iterations per mini-batch.
+//
+// Returns a list of vectors containing the updated example state
+// data.a list of vectors where each value is the delta
+// weights associated with a sparse feature group.a list of vectors where the values are the delta
+// weights associated with a dense feature group.
+func SdcaOptimizer(scope *Scope, sparse_example_indices []tf.Output, sparse_feature_indices []tf.Output, sparse_feature_values []tf.Output, dense_features []tf.Output, example_weights tf.Output, example_labels tf.Output, sparse_indices []tf.Output, sparse_weights []tf.Output, dense_weights []tf.Output, example_state_data tf.Output, loss_type string, l1 float32, l2 float32, num_loss_partitions int64, num_inner_iterations int64, optional ...SdcaOptimizerAttr) (out_example_state_data tf.Output, out_delta_sparse_weights []tf.Output, out_delta_dense_weights []tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"loss_type": loss_type, "l1": l1, "l2": l2, "num_loss_partitions": num_loss_partitions, "num_inner_iterations": num_inner_iterations}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "SdcaOptimizer",
+ Input: []tf.Input{
+ tf.OutputList(sparse_example_indices), tf.OutputList(sparse_feature_indices), tf.OutputList(sparse_feature_values), tf.OutputList(dense_features), example_weights, example_labels, tf.OutputList(sparse_indices), tf.OutputList(sparse_weights), tf.OutputList(dense_weights), example_state_data,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ if scope.Err() != nil {
+ return
+ }
+ var idx int
+ var err error
+ out_example_state_data = op.Output(idx)
+ if out_delta_sparse_weights, idx, err = makeOutputList(op, idx, "out_delta_sparse_weights"); err != nil {
+ scope.UpdateErr("SdcaOptimizer", err)
+ return
+ }
+ if out_delta_dense_weights, idx, err = makeOutputList(op, idx, "out_delta_dense_weights"); err != nil {
+ scope.UpdateErr("SdcaOptimizer", err)
+ return
+ }
+ return out_example_state_data, out_delta_sparse_weights, out_delta_dense_weights
+}
+
+// MutableDenseHashTableV2Attr is an optional argument to MutableDenseHashTableV2.
+type MutableDenseHashTableV2Attr func(optionalAttr)
+
+// MutableDenseHashTableV2Container sets the optional container attribute to value.
+//
+// value: If non-empty, this table is placed in the given container.
+// Otherwise, a default container is used.
+// If not specified, defaults to ""
+func MutableDenseHashTableV2Container(value string) MutableDenseHashTableV2Attr {
+ return func(m optionalAttr) {
+ m["container"] = value
+ }
+}
+
+// MutableDenseHashTableV2SharedName sets the optional shared_name attribute to value.
+//
+// value: If non-empty, this table is shared under the given name across
+// multiple sessions.
+// If not specified, defaults to ""
+func MutableDenseHashTableV2SharedName(value string) MutableDenseHashTableV2Attr {
+ return func(m optionalAttr) {
+ m["shared_name"] = value
+ }
+}
+
+// MutableDenseHashTableV2UseNodeNameSharing sets the optional use_node_name_sharing attribute to value.
+// If not specified, defaults to false
+func MutableDenseHashTableV2UseNodeNameSharing(value bool) MutableDenseHashTableV2Attr {
+ return func(m optionalAttr) {
+ m["use_node_name_sharing"] = value
+ }
+}
+
+// MutableDenseHashTableV2ValueShape sets the optional value_shape attribute to value.
+//
+// value: The shape of each value.
+// If not specified, defaults to <>
+func MutableDenseHashTableV2ValueShape(value tf.Shape) MutableDenseHashTableV2Attr {
+ return func(m optionalAttr) {
+ m["value_shape"] = value
+ }
+}
+
+// MutableDenseHashTableV2InitialNumBuckets sets the optional initial_num_buckets attribute to value.
+//
+// value: The initial number of hash table buckets. Must be a power
+// to 2.
+// If not specified, defaults to 131072
+func MutableDenseHashTableV2InitialNumBuckets(value int64) MutableDenseHashTableV2Attr {
+ return func(m optionalAttr) {
+ m["initial_num_buckets"] = value
+ }
+}
+
+// MutableDenseHashTableV2MaxLoadFactor sets the optional max_load_factor attribute to value.
+//
+// value: The maximum ratio between number of entries and number of
+// buckets before growing the table. Must be between 0 and 1.
+// If not specified, defaults to 0.8
+func MutableDenseHashTableV2MaxLoadFactor(value float32) MutableDenseHashTableV2Attr {
+ return func(m optionalAttr) {
+ m["max_load_factor"] = value
+ }
+}
+
+// Creates an empty hash table that uses tensors as the backing store.
+//
+// It uses "open addressing" with quadratic reprobing to resolve
+// collisions.
+//
+// This op creates a mutable hash table, specifying the type of its keys and
+// values. Each value must be a scalar. Data can be inserted into the table using
+// the insert operations. It does not support the initialization operation.
+//
+// Arguments:
+// empty_key: The key used to represent empty key buckets internally. Must not
+// be used in insert or lookup operations.
+//
+// value_dtype: Type of the table values.
+//
+// Returns Handle to a table.
+func MutableDenseHashTableV2(scope *Scope, empty_key tf.Output, deleted_key tf.Output, value_dtype tf.DataType, optional ...MutableDenseHashTableV2Attr) (table_handle tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{"value_dtype": value_dtype}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "MutableDenseHashTableV2",
+ Input: []tf.Input{
+ empty_key, deleted_key,
+ },
+ Attrs: attrs,
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// CompilationResultProto indicating the status of the TPU compilation.
+func TPUCompilationResult(scope *Scope) (output tf.Output) {
if scope.Err() != nil {
return
}
opspec := tf.OpSpec{
- Type: "StatelessRandomUniformInt",
+ Type: "TPUCompilationResult",
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// AssertAttr is an optional argument to Assert.
+type AssertAttr func(optionalAttr)
+
+// AssertSummarize sets the optional summarize attribute to value.
+//
+// value: Print this many entries of each tensor.
+// If not specified, defaults to 3
+func AssertSummarize(value int64) AssertAttr {
+ return func(m optionalAttr) {
+ m["summarize"] = value
+ }
+}
+
+// Asserts that the given condition is true.
+//
+// If `condition` evaluates to false, print the list of tensors in `data`.
+// `summarize` determines how many entries of the tensors to print.
+//
+// Arguments:
+// condition: The condition to evaluate.
+// data: The tensors to print out when condition is false.
+//
+// Returns the created operation.
+func Assert(scope *Scope, condition tf.Output, data []tf.Output, optional ...AssertAttr) (o *tf.Operation) {
+ if scope.Err() != nil {
+ return
+ }
+ attrs := map[string]interface{}{}
+ for _, a := range optional {
+ a(attrs)
+ }
+ opspec := tf.OpSpec{
+ Type: "Assert",
Input: []tf.Input{
- shape, seed, minval, maxval,
+ condition, tf.OutputList(data),
+ },
+ Attrs: attrs,
+ }
+ return scope.AddOperation(opspec)
+}
+
+// Decode web-safe base64-encoded strings.
+//
+// Input may or may not have padding at the end. See EncodeBase64 for padding.
+// Web-safe means that input must use - and _ instead of + and /.
+//
+// Arguments:
+// input: Base64 strings to decode.
+//
+// Returns Decoded strings.
+func DecodeBase64(scope *Scope, input tf.Output) (output tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ opspec := tf.OpSpec{
+ Type: "DecodeBase64",
+ Input: []tf.Input{
+ input,
},
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
-// Deserialize `SparseTensor` objects.
+// Scatter the data from the input value into specific TensorArray elements.
//
-// The input `serialized_sparse` must have the shape `[?, ?, ..., ?, 3]` where
-// the last dimension stores serialized `SparseTensor` objects and the other N
-// dimensions (N >= 0) correspond to a batch. The ranks of the original
-// `SparseTensor` objects must all match. When the final `SparseTensor` is
-// created, its rank is the rank of the incoming `SparseTensor` objects plus N;
-// the sparse tensors have been concatenated along new dimensions, one for each
-// batch.
-//
-// The output `SparseTensor` object's shape values for the original dimensions
-// are the max across the input `SparseTensor` objects' shape values for the
-// corresponding dimensions. The new dimensions match the size of the batch.
-//
-// The input `SparseTensor` objects' indices are assumed ordered in
-// standard lexicographic order. If this is not the case, after this
-// step run `SparseReorder` to restore index ordering.
-//
-// For example, if the serialized input is a `[2 x 3]` matrix representing two
-// original `SparseTensor` objects:
-//
-// index = [ 0]
-// [10]
-// [20]
-// values = [1, 2, 3]
-// shape = [50]
-//
-// and
-//
-// index = [ 2]
-// [10]
-// values = [4, 5]
-// shape = [30]
-//
-// then the final deserialized `SparseTensor` will be:
-//
-// index = [0 0]
-// [0 10]
-// [0 20]
-// [1 2]
-// [1 10]
-// values = [1, 2, 3, 4, 5]
-// shape = [2 50]
+// `indices` must be a vector, its length must match the first dim of `value`.
//
// Arguments:
-// serialized_sparse: The serialized `SparseTensor` objects. The last dimension
-// must have 3 columns.
-// dtype: The `dtype` of the serialized `SparseTensor` objects.
-func DeserializeSparse(scope *Scope, serialized_sparse tf.Output, dtype tf.DataType) (sparse_indices tf.Output, sparse_values tf.Output, sparse_shape tf.Output) {
+// handle: The handle to a TensorArray.
+// indices: The locations at which to write the tensor elements.
+// value: The concatenated tensor to write to the TensorArray.
+// flow_in: A float scalar that enforces proper chaining of operations.
+//
+// Returns A float scalar that enforces proper chaining of operations.
+func TensorArrayScatterV3(scope *Scope, handle tf.Output, indices tf.Output, value tf.Output, flow_in tf.Output) (flow_out tf.Output) {
if scope.Err() != nil {
return
}
- attrs := map[string]interface{}{"dtype": dtype}
opspec := tf.OpSpec{
- Type: "DeserializeSparse",
+ Type: "TensorArrayScatterV3",
Input: []tf.Input{
- serialized_sparse,
+ handle, indices, value, flow_in,
},
- Attrs: attrs,
}
op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1), op.Output(2)
+ return op.Output(0)
}
-// RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebugAttr is an optional argument to RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebug.
-type RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebugAttr func(optionalAttr)
-
-// RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebugTableId sets the optional table_id attribute to value.
-// If not specified, defaults to -1
+// Strip leading and trailing whitespaces from the Tensor.
//
-// REQUIRES: value >= -1
-func RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebugTableId(value int64) RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebugAttr {
- return func(m optionalAttr) {
- m["table_id"] = value
- }
-}
-
-// RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebugTableName sets the optional table_name attribute to value.
-// If not specified, defaults to ""
-func RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebugTableName(value string) RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebugAttr {
- return func(m optionalAttr) {
- m["table_name"] = value
- }
-}
-
-// Retrieve proximal Adagrad embedding parameters with debug support.
+// Arguments:
+// input: A string `Tensor` of any shape.
//
-// An op that retrieves optimization parameters from embedding to host
-// memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up
-// the correct embedding table configuration. For example, this op is
-// used to retrieve updated parameters before saving a checkpoint.
-//
-// Returns Parameter parameters updated by the proximal Adagrad optimization algorithm.Parameter accumulators updated by the proximal Adagrad optimization algorithm.Parameter gradient_accumulators updated by the proximal Adagrad optimization algorithm.
-func RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebug(scope *Scope, num_shards int64, shard_id int64, optional ...RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebugAttr) (parameters tf.Output, accumulators tf.Output, gradient_accumulators tf.Output) {
+// Returns A string `Tensor` of the same shape as the input.
+func StringStrip(scope *Scope, input tf.Output) (output tf.Output) {
if scope.Err() != nil {
return
}
- attrs := map[string]interface{}{"num_shards": num_shards, "shard_id": shard_id}
- for _, a := range optional {
- a(attrs)
- }
opspec := tf.OpSpec{
- Type: "RetrieveTPUEmbeddingProximalAdagradParametersGradAccumDebug",
-
- Attrs: attrs,
+ Type: "StringStrip",
+ Input: []tf.Input{
+ input,
+ },
}
op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1), op.Output(2)
+ return op.Output(0)
}
// Returns the last element of the input list as well as a list with all but that element.
@@ -25233,375 +26977,158 @@ func FloorDiv(scope *Scope, x tf.Output, y tf.Output) (z tf.Output) {
return op.Output(0)
}
-// Inverse 2D fast Fourier transform.
+// Outputs deterministic pseudorandom random integers from a uniform distribution.
//
-// Computes the inverse 2-dimensional discrete Fourier transform over the
-// inner-most 2 dimensions of `input`.
+// The generated values follow a uniform distribution in the range `[minval, maxval)`.
+//
+// The outputs are a deterministic function of `shape`, `seed`, `minval`, and `maxval`.
//
// Arguments:
-// input: A complex tensor.
+// shape: The shape of the output tensor.
+// seed: 2 seeds (shape [2]).
+// minval: Minimum value (inclusive, scalar).
+// maxval: Maximum value (exclusive, scalar).
//
-// Returns A complex tensor of the same shape as `input`. The inner-most 2
-// dimensions of `input` are replaced with their inverse 2D Fourier transform.
-//
-// @compatibility(numpy)
-// Equivalent to np.fft.ifft2
-// @end_compatibility
-func IFFT2D(scope *Scope, input tf.Output) (output tf.Output) {
+// Returns Random values with specified shape.
+func StatelessRandomUniformInt(scope *Scope, shape tf.Output, seed tf.Output, minval tf.Output, maxval tf.Output) (output tf.Output) {
if scope.Err() != nil {
return
}
opspec := tf.OpSpec{
- Type: "IFFT2D",
+ Type: "StatelessRandomUniformInt",
Input: []tf.Input{
- input,
+ shape, seed, minval, maxval,
},
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
-// Computes the reciprocal of x element-wise.
-//
-// I.e., \\(y = 1 / x\\).
-func Reciprocal(scope *Scope, x tf.Output) (y tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "Reciprocal",
- Input: []tf.Input{
- x,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
+// UnicodeDecodeWithOffsetsAttr is an optional argument to UnicodeDecodeWithOffsets.
+type UnicodeDecodeWithOffsetsAttr func(optionalAttr)
-// An op enabling differentiation of TPU Embeddings.
+// UnicodeDecodeWithOffsetsErrors sets the optional errors attribute to value.
//
-// This op simply returns its first input, which is assumed to have been sliced
-// from the Tensors returned by TPUEmbeddingDequeueActivations. The presence of
-// this op, and its first argument being a trainable Variable, enables automatic
-// differentiation of graphs containing embeddings via the TPU Embedding Python
-// libraries.
-//
-// Arguments:
-// embedding_variable: A trainable variable, enabling optimizers to find this op.
-// sliced_activations: The embedding activations Tensor to return.
-// table_id: The id of the table in the embedding layer configuration from which
-// these activations were computed.
-// lookup_id: Identifier of the set of embedding indices which produced these
-// activations.
-func TPUEmbeddingActivations(scope *Scope, embedding_variable tf.Output, sliced_activations tf.Output, table_id int64, lookup_id int64) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"table_id": table_id, "lookup_id": lookup_id}
- opspec := tf.OpSpec{
- Type: "TPUEmbeddingActivations",
- Input: []tf.Input{
- embedding_variable, sliced_activations,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Looks up keys in a table, outputs the corresponding values.
-//
-// The tensor `keys` must of the same type as the keys of the table.
-// The output `values` is of the type of the table values.
-//
-// The scalar `default_value` is the value output for keys not present in the
-// table. It must also be of the same type as the table values.
-//
-// Arguments:
-// table_handle: Handle to the table.
-// keys: Any shape. Keys to look up.
-//
-//
-// Returns Same shape as `keys`. Values found in the table, or `default_values`
-// for missing keys.
-func LookupTableFindV2(scope *Scope, table_handle tf.Output, keys tf.Output, default_value tf.Output) (values tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "LookupTableFindV2",
- Input: []tf.Input{
- table_handle, keys, default_value,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// FusedBatchNormGradV2Attr is an optional argument to FusedBatchNormGradV2.
-type FusedBatchNormGradV2Attr func(optionalAttr)
-
-// FusedBatchNormGradV2Epsilon sets the optional epsilon attribute to value.
-//
-// value: A small float number added to the variance of x.
-// If not specified, defaults to 0.0001
-func FusedBatchNormGradV2Epsilon(value float32) FusedBatchNormGradV2Attr {
+// value: Error handling policy when there is invalid formatting found in the input.
+// The value of 'strict' will cause the operation to produce a InvalidArgument
+// error on any invalid input formatting. A value of 'replace' (the default) will
+// cause the operation to replace any invalid formatting in the input with the
+// `replacement_char` codepoint. A value of 'ignore' will cause the operation to
+// skip any invalid formatting in the input and produce no corresponding output
+// character.
+// If not specified, defaults to "replace"
+func UnicodeDecodeWithOffsetsErrors(value string) UnicodeDecodeWithOffsetsAttr {
return func(m optionalAttr) {
- m["epsilon"] = value
+ m["errors"] = value
}
}
-// FusedBatchNormGradV2DataFormat sets the optional data_format attribute to value.
+// UnicodeDecodeWithOffsetsReplacementChar sets the optional replacement_char attribute to value.
//
-// value: The data format for y_backprop, x, x_backprop.
-// Either "NHWC" (default) or "NCHW".
-// If not specified, defaults to "NHWC"
-func FusedBatchNormGradV2DataFormat(value string) FusedBatchNormGradV2Attr {
+// value: The replacement character codepoint to be used in place of any invalid
+// formatting in the input when `errors='replace'`. Any valid unicode codepoint may
+// be used. The default value is the default unicode replacement character is
+// 0xFFFD or U+65533.)
+// If not specified, defaults to 65533
+func UnicodeDecodeWithOffsetsReplacementChar(value int64) UnicodeDecodeWithOffsetsAttr {
return func(m optionalAttr) {
- m["data_format"] = value
+ m["replacement_char"] = value
}
}
-// FusedBatchNormGradV2IsTraining sets the optional is_training attribute to value.
+// UnicodeDecodeWithOffsetsReplaceControlCharacters sets the optional replace_control_characters attribute to value.
//
-// value: A bool value to indicate the operation is for training (default)
-// or inference.
-// If not specified, defaults to true
-func FusedBatchNormGradV2IsTraining(value bool) FusedBatchNormGradV2Attr {
+// value: Whether to replace the C0 control characters (00-1F) with the
+// `replacement_char`. Default is false.
+// If not specified, defaults to false
+func UnicodeDecodeWithOffsetsReplaceControlCharacters(value bool) UnicodeDecodeWithOffsetsAttr {
return func(m optionalAttr) {
- m["is_training"] = value
+ m["replace_control_characters"] = value
}
}
-// Gradient for batch normalization.
+// UnicodeDecodeWithOffsetsTsplits sets the optional Tsplits attribute to value.
+// If not specified, defaults to DT_INT64
+func UnicodeDecodeWithOffsetsTsplits(value tf.DataType) UnicodeDecodeWithOffsetsAttr {
+ return func(m optionalAttr) {
+ m["Tsplits"] = value
+ }
+}
+
+// Decodes each string in `input` into a sequence of Unicode code points.
//
-// Note that the size of 4D Tensors are defined by either "NHWC" or "NCHW".
-// The size of 1D Tensors matches the dimension C of the 4D Tensors.
+// The character codepoints for all strings are returned using a single vector
+// `char_values`, with strings expanded to characters in row-major order.
+// Similarly, the character start byte offsets are returned using a single vector
+// `char_to_byte_starts`, with strings expanded in row-major order.
+//
+// The `row_splits` tensor indicates where the codepoints and start offsets for
+// each input string begin and end within the `char_values` and
+// `char_to_byte_starts` tensors. In particular, the values for the `i`th
+// string (in row-major order) are stored in the slice
+// `[row_splits[i]:row_splits[i+1]]`. Thus:
+//
+// * `char_values[row_splits[i]+j]` is the Unicode codepoint for the `j`th
+// character in the `i`th string (in row-major order).
+// * `char_to_bytes_starts[row_splits[i]+j]` is the start byte offset for the `j`th
+// character in the `i`th string (in row-major order).
+// * `row_splits[i+1] - row_splits[i]` is the number of characters in the `i`th
+// string (in row-major order).
//
// Arguments:
-// y_backprop: A 4D Tensor for the gradient with respect to y.
-// x: A 4D Tensor for input data.
-// scale: A 1D Tensor for scaling factor, to scale the normalized x.
-// reserve_space_1: When is_training is True, a 1D Tensor for the computed batch
-// mean to be reused in gradient computation. When is_training is
-// False, a 1D Tensor for the population mean to be reused in both
-// 1st and 2nd order gradient computation.
-// reserve_space_2: When is_training is True, a 1D Tensor for the computed batch
-// variance (inverted variance in the cuDNN case) to be reused in
-// gradient computation. When is_training is False, a 1D Tensor
-// for the population variance to be reused in both 1st and 2nd
-// order gradient computation.
+// input: The text to be decoded. Can have any shape. Note that the output is flattened
+// to a vector of char values.
+// input_encoding: Text encoding of the input strings. This is any of the encodings supported
+// by ICU ucnv algorithmic converters. Examples: `"UTF-16", "US ASCII", "UTF-8"`.
//
-// Returns A 4D Tensor for the gradient with respect to x.A 1D Tensor for the gradient with respect to scale.A 1D Tensor for the gradient with respect to offset.Unused placeholder to match the mean input in FusedBatchNorm.Unused placeholder to match the variance input
-// in FusedBatchNorm.
-func FusedBatchNormGradV2(scope *Scope, y_backprop tf.Output, x tf.Output, scale tf.Output, reserve_space_1 tf.Output, reserve_space_2 tf.Output, optional ...FusedBatchNormGradV2Attr) (x_backprop tf.Output, scale_backprop tf.Output, offset_backprop tf.Output, reserve_space_3 tf.Output, reserve_space_4 tf.Output) {
+// Returns A 1D int32 tensor containing the row splits.A 1D int32 Tensor containing the decoded codepoints.A 1D int32 Tensor containing the byte index in the input string where each
+// character in `char_values` starts.
+func UnicodeDecodeWithOffsets(scope *Scope, input tf.Output, input_encoding string, optional ...UnicodeDecodeWithOffsetsAttr) (row_splits tf.Output, char_values tf.Output, char_to_byte_starts tf.Output) {
if scope.Err() != nil {
return
}
- attrs := map[string]interface{}{}
+ attrs := map[string]interface{}{"input_encoding": input_encoding}
for _, a := range optional {
a(attrs)
}
opspec := tf.OpSpec{
- Type: "FusedBatchNormGradV2",
- Input: []tf.Input{
- y_backprop, x, scale, reserve_space_1, reserve_space_2,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1), op.Output(2), op.Output(3), op.Output(4)
-}
-
-// The gradient operator for the SparseSlice op.
-//
-// This op takes in the upstream gradient w.r.t. non-empty values of
-// the sliced `SparseTensor`, and outputs the gradients w.r.t.
-// the non-empty values of input `SparseTensor`.
-//
-// Arguments:
-// backprop_val_grad: 1-D. The gradient with respect to
-// the non-empty values of the sliced `SparseTensor`.
-// input_indices: 2-D. The `indices` of the input `SparseTensor`.
-// input_start: 1-D. tensor represents the start of the slice.
-// output_indices: 2-D. The `indices` of the sliced `SparseTensor`.
-//
-// Returns 1-D. The gradient with respect to the non-empty values of input `SparseTensor`.
-func SparseSliceGrad(scope *Scope, backprop_val_grad tf.Output, input_indices tf.Output, input_start tf.Output, output_indices tf.Output) (val_grad tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "SparseSliceGrad",
- Input: []tf.Input{
- backprop_val_grad, input_indices, input_start, output_indices,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Computes fingerprints of the input strings.
-//
-// Arguments:
-// input: vector of strings to compute fingerprints on.
-//
-// Returns a (N,2) shaped matrix where N is the number of elements in the input
-// vector. Each row contains the low and high parts of the fingerprint.
-func SdcaFprint(scope *Scope, input tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "SdcaFprint",
- Input: []tf.Input{
- input,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// RegexReplaceAttr is an optional argument to RegexReplace.
-type RegexReplaceAttr func(optionalAttr)
-
-// RegexReplaceReplaceGlobal sets the optional replace_global attribute to value.
-//
-// value: If True, the replacement is global (that is, all matches of the `pattern` regular
-// expression in each input string are rewritten), otherwise the `rewrite`
-// substitution is only made for the first `pattern` match.
-// If not specified, defaults to true
-func RegexReplaceReplaceGlobal(value bool) RegexReplaceAttr {
- return func(m optionalAttr) {
- m["replace_global"] = value
- }
-}
-
-// Replaces matches of the `pattern` regular expression in `input` with the
-// replacement string provided in `rewrite`.
-//
-// It follows the re2 syntax (https://github.com/google/re2/wiki/Syntax)
-//
-// Arguments:
-// input: The text to be processed.
-// pattern: The regular expression to be matched in the `input` strings.
-// rewrite: The rewrite string to be substituted for the `pattern` expression where it is
-// matched in the `input` strings.
-//
-// Returns The text after applying pattern match and rewrite substitution.
-func RegexReplace(scope *Scope, input tf.Output, pattern tf.Output, rewrite tf.Output, optional ...RegexReplaceAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "RegexReplace",
- Input: []tf.Input{
- input, pattern, rewrite,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Converts each string in the input Tensor to its hash mod by a number of buckets.
-//
-// The hash function is deterministic on the content of the string within the
-// process. The hash function is a keyed hash function, where attribute `key`
-// defines the key of the hash function. `key` is an array of 2 elements.
-//
-// A strong hash is important when inputs may be malicious, e.g. URLs with
-// additional components. Adversaries could try to make their inputs hash to the
-// same bucket for a denial-of-service attack or to skew the results. A strong
-// hash prevents this by making it difficult, if not infeasible, to compute inputs
-// that hash to the same bucket. This comes at a cost of roughly 4x higher compute
-// time than `tf.string_to_hash_bucket_fast`.
-//
-// Arguments:
-// input: The strings to assign a hash bucket.
-// num_buckets: The number of buckets.
-// key: The key for the keyed hash function passed as a list of two uint64
-// elements.
-//
-// Returns A Tensor of the same shape as the input `string_tensor`.
-func StringToHashBucketStrong(scope *Scope, input tf.Output, num_buckets int64, key []int64) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"num_buckets": num_buckets, "key": key}
- opspec := tf.OpSpec{
- Type: "StringToHashBucketStrong",
+ Type: "UnicodeDecodeWithOffsets",
Input: []tf.Input{
input,
},
Attrs: attrs,
}
op := scope.AddOperation(opspec)
- return op.Output(0)
+ return op.Output(0), op.Output(1), op.Output(2)
}
-// ReduceJoinAttr is an optional argument to ReduceJoin.
-type ReduceJoinAttr func(optionalAttr)
+// StatelessTruncatedNormalAttr is an optional argument to StatelessTruncatedNormal.
+type StatelessTruncatedNormalAttr func(optionalAttr)
-// ReduceJoinKeepDims sets the optional keep_dims attribute to value.
+// StatelessTruncatedNormalDtype sets the optional dtype attribute to value.
//
-// value: If `True`, retain reduced dimensions with length `1`.
-// If not specified, defaults to false
-func ReduceJoinKeepDims(value bool) ReduceJoinAttr {
+// value: The type of the output.
+// If not specified, defaults to DT_FLOAT
+func StatelessTruncatedNormalDtype(value tf.DataType) StatelessTruncatedNormalAttr {
return func(m optionalAttr) {
- m["keep_dims"] = value
+ m["dtype"] = value
}
}
-// ReduceJoinSeparator sets the optional separator attribute to value.
+// Outputs deterministic pseudorandom values from a truncated normal distribution.
//
-// value: The separator to use when joining.
-// If not specified, defaults to ""
-func ReduceJoinSeparator(value string) ReduceJoinAttr {
- return func(m optionalAttr) {
- m["separator"] = value
- }
-}
-
-// Joins a string Tensor across the given dimensions.
+// The generated values follow a normal distribution with mean 0 and standard
+// deviation 1, except that values whose magnitude is more than 2 standard
+// deviations from the mean are dropped and re-picked.
//
-// Computes the string join across dimensions in the given string Tensor of shape
-// `[\\(d_0, d_1, ..., d_{n-1}\\)]`. Returns a new Tensor created by joining the input
-// strings with the given separator (default: empty string). Negative indices are
-// counted backwards from the end, with `-1` being equivalent to `n - 1`. If
-// indices are not specified, joins across all dimensions beginning from `n - 1`
-// through `0`.
-//
-// For example:
-//
-// ```python
-// # tensor `a` is [["a", "b"], ["c", "d"]]
-// tf.reduce_join(a, 0) ==> ["ac", "bd"]
-// tf.reduce_join(a, 1) ==> ["ab", "cd"]
-// tf.reduce_join(a, -2) = tf.reduce_join(a, 0) ==> ["ac", "bd"]
-// tf.reduce_join(a, -1) = tf.reduce_join(a, 1) ==> ["ab", "cd"]
-// tf.reduce_join(a, 0, keep_dims=True) ==> [["ac", "bd"]]
-// tf.reduce_join(a, 1, keep_dims=True) ==> [["ab"], ["cd"]]
-// tf.reduce_join(a, 0, separator=".") ==> ["a.c", "b.d"]
-// tf.reduce_join(a, [0, 1]) ==> "acbd"
-// tf.reduce_join(a, [1, 0]) ==> "abcd"
-// tf.reduce_join(a, []) ==> [["a", "b"], ["c", "d"]]
-// tf.reduce_join(a) = tf.reduce_join(a, [1, 0]) ==> "abcd"
-// ```
+// The outputs are a deterministic function of `shape` and `seed`.
//
// Arguments:
-// inputs: The input to be joined. All reduced indices must have non-zero size.
-// reduction_indices: The dimensions to reduce over. Dimensions are reduced in the
-// order specified. Omitting `reduction_indices` is equivalent to passing
-// `[n-1, n-2, ..., 0]`. Negative indices from `-n` to `-1` are supported.
+// shape: The shape of the output tensor.
+// seed: 2 seeds (shape [2]).
//
-// Returns Has shape equal to that of the input with reduced dimensions removed or
-// set to `1` depending on `keep_dims`.
-func ReduceJoin(scope *Scope, inputs tf.Output, reduction_indices tf.Output, optional ...ReduceJoinAttr) (output tf.Output) {
+// Returns Random values with specified shape.
+func StatelessTruncatedNormal(scope *Scope, shape tf.Output, seed tf.Output, optional ...StatelessTruncatedNormalAttr) (output tf.Output) {
if scope.Err() != nil {
return
}
@@ -25610,9 +27137,9 @@ func ReduceJoin(scope *Scope, inputs tf.Output, reduction_indices tf.Output, opt
a(attrs)
}
opspec := tf.OpSpec{
- Type: "ReduceJoin",
+ Type: "StatelessTruncatedNormal",
Input: []tf.Input{
- inputs, reduction_indices,
+ shape, seed,
},
Attrs: attrs,
}
@@ -25620,44 +27147,98 @@ func ReduceJoin(scope *Scope, inputs tf.Output, reduction_indices tf.Output, opt
return op.Output(0)
}
-// ResourceSparseApplyAdagradAttr is an optional argument to ResourceSparseApplyAdagrad.
-type ResourceSparseApplyAdagradAttr func(optionalAttr)
-
-// ResourceSparseApplyAdagradUseLocking sets the optional use_locking attribute to value.
+// Decode the frame(s) of a GIF-encoded image to a uint8 tensor.
//
-// value: If `True`, updating of the var and accum tensors will be protected
-// by a lock; otherwise the behavior is undefined, but may exhibit less
-// contention.
-// If not specified, defaults to false
-func ResourceSparseApplyAdagradUseLocking(value bool) ResourceSparseApplyAdagradAttr {
- return func(m optionalAttr) {
- m["use_locking"] = value
- }
-}
-
-// ResourceSparseApplyAdagradUpdateSlots sets the optional update_slots attribute to value.
-// If not specified, defaults to true
-func ResourceSparseApplyAdagradUpdateSlots(value bool) ResourceSparseApplyAdagradAttr {
- return func(m optionalAttr) {
- m["update_slots"] = value
- }
-}
-
-// Update relevant entries in '*var' and '*accum' according to the adagrad scheme.
+// GIF images with frame or transparency compression are not supported.
+// On Linux and MacOS systems, convert animated GIFs from compressed to
+// uncompressed by running:
//
-// That is for rows we have grad for, we update var and accum as follows:
-// accum += grad * grad
-// var -= lr * grad * (1 / sqrt(accum))
+// convert $src.gif -coalesce $dst.gif
+//
+// This op also supports decoding JPEGs and PNGs, though it is cleaner to use
+// `tf.image.decode_image`.
//
// Arguments:
-// var_: Should be from a Variable().
-// accum: Should be from a Variable().
-// lr: Learning rate. Must be a scalar.
-// grad: The gradient.
-// indices: A vector of indices into the first dimension of var and accum.
+// contents: 0-D. The GIF-encoded image.
//
-// Returns the created operation.
-func ResourceSparseApplyAdagrad(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, grad tf.Output, indices tf.Output, optional ...ResourceSparseApplyAdagradAttr) (o *tf.Operation) {
+// Returns 4-D with shape `[num_frames, height, width, 3]`. RGB channel order.
+func DecodeGif(scope *Scope, contents tf.Output) (image tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ opspec := tf.OpSpec{
+ Type: "DecodeGif",
+ Input: []tf.Input{
+ contents,
+ },
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// Computes gradients for the scaled exponential linear (Selu) operation.
+//
+// Arguments:
+// gradients: The backpropagated gradients to the corresponding Selu operation.
+// outputs: The outputs of the corresponding Selu operation.
+//
+// Returns The gradients: `gradients * (outputs + scale * alpha)`
+// if outputs < 0, `scale * gradients` otherwise.
+func SeluGrad(scope *Scope, gradients tf.Output, outputs tf.Output) (backprops tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ opspec := tf.OpSpec{
+ Type: "SeluGrad",
+ Input: []tf.Input{
+ gradients, outputs,
+ },
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// RandomGammaAttr is an optional argument to RandomGamma.
+type RandomGammaAttr func(optionalAttr)
+
+// RandomGammaSeed sets the optional seed attribute to value.
+//
+// value: If either `seed` or `seed2` are set to be non-zero, the random number
+// generator is seeded by the given seed. Otherwise, it is seeded by a
+// random seed.
+// If not specified, defaults to 0
+func RandomGammaSeed(value int64) RandomGammaAttr {
+ return func(m optionalAttr) {
+ m["seed"] = value
+ }
+}
+
+// RandomGammaSeed2 sets the optional seed2 attribute to value.
+//
+// value: A second seed to avoid seed collision.
+// If not specified, defaults to 0
+func RandomGammaSeed2(value int64) RandomGammaAttr {
+ return func(m optionalAttr) {
+ m["seed2"] = value
+ }
+}
+
+// Outputs random values from the Gamma distribution(s) described by alpha.
+//
+// This op uses the algorithm by Marsaglia et al. to acquire samples via
+// transformation-rejection from pairs of uniform and normal random variables.
+// See http://dl.acm.org/citation.cfm?id=358414
+//
+// Arguments:
+// shape: 1-D integer tensor. Shape of independent samples to draw from each
+// distribution described by the shape parameters given in alpha.
+// alpha: A tensor in which each scalar is a "shape" parameter describing the
+// associated gamma distribution.
+//
+// Returns A tensor with shape `shape + shape(alpha)`. Each slice
+// `[:, ..., :, i0, i1, ...iN]` contains the samples drawn for
+// `alpha[i0, i1, ...iN]`. The dtype of the output matches the dtype of alpha.
+func RandomGamma(scope *Scope, shape tf.Output, alpha tf.Output, optional ...RandomGammaAttr) (output tf.Output) {
if scope.Err() != nil {
return
}
@@ -25666,101 +27247,9 @@ func ResourceSparseApplyAdagrad(scope *Scope, var_ tf.Output, accum tf.Output, l
a(attrs)
}
opspec := tf.OpSpec{
- Type: "ResourceSparseApplyAdagrad",
+ Type: "RandomGamma",
Input: []tf.Input{
- var_, accum, lr, grad, indices,
- },
- Attrs: attrs,
- }
- return scope.AddOperation(opspec)
-}
-
-// Computes the mean along sparse segments of a tensor.
-//
-// Like `SparseSegmentMean`, but allows missing ids in `segment_ids`. If an id is
-// misisng, the `output` tensor at that position will be zeroed.
-//
-// Read
-// [the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation)
-// for an explanation of segments.
-//
-// Arguments:
-//
-// indices: A 1-D tensor. Has same rank as `segment_ids`.
-// segment_ids: A 1-D tensor. Values should be sorted and can be repeated.
-// num_segments: Should equal the number of distinct segment IDs.
-//
-// Returns Has same shape as data, except for dimension 0 which has size
-// `num_segments`.
-func SparseSegmentMeanWithNumSegments(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output, num_segments tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "SparseSegmentMeanWithNumSegments",
- Input: []tf.Input{
- data, indices, segment_ids, num_segments,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// AllAttr is an optional argument to All.
-type AllAttr func(optionalAttr)
-
-// AllKeepDims sets the optional keep_dims attribute to value.
-//
-// value: If true, retain reduced dimensions with length 1.
-// If not specified, defaults to false
-func AllKeepDims(value bool) AllAttr {
- return func(m optionalAttr) {
- m["keep_dims"] = value
- }
-}
-
-// Computes the "logical and" of elements across dimensions of a tensor.
-//
-// Reduces `input` along the dimensions given in `axis`. Unless
-// `keep_dims` is true, the rank of the tensor is reduced by 1 for each entry in
-// `axis`. If `keep_dims` is true, the reduced dimensions are
-// retained with length 1.
-//
-// Arguments:
-// input: The tensor to reduce.
-// axis: The dimensions to reduce. Must be in the range
-// `[-rank(input), rank(input))`.
-//
-// Returns The reduced tensor.
-func All(scope *Scope, input tf.Output, axis tf.Output, optional ...AllAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "All",
- Input: []tf.Input{
- input, axis,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Creates a dataset that zips together `input_datasets`.
-func ZipDataset(scope *Scope, input_datasets []tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"output_types": output_types, "output_shapes": output_shapes}
- opspec := tf.OpSpec{
- Type: "ZipDataset",
- Input: []tf.Input{
- tf.OutputList(input_datasets),
+ shape, alpha,
},
Attrs: attrs,
}
@@ -25832,317 +27321,41 @@ func DeserializeManySparse(scope *Scope, serialized_sparse tf.Output, dtype tf.D
return op.Output(0), op.Output(1), op.Output(2)
}
-// DataFormatDimMapAttr is an optional argument to DataFormatDimMap.
-type DataFormatDimMapAttr func(optionalAttr)
+// FractionalMaxPoolGradAttr is an optional argument to FractionalMaxPoolGrad.
+type FractionalMaxPoolGradAttr func(optionalAttr)
-// DataFormatDimMapSrcFormat sets the optional src_format attribute to value.
+// FractionalMaxPoolGradOverlapping sets the optional overlapping attribute to value.
//
-// value: source data format.
-// If not specified, defaults to "NHWC"
-func DataFormatDimMapSrcFormat(value string) DataFormatDimMapAttr {
- return func(m optionalAttr) {
- m["src_format"] = value
- }
-}
-
-// DataFormatDimMapDstFormat sets the optional dst_format attribute to value.
+// value: When set to True, it means when pooling, the values at the boundary
+// of adjacent pooling cells are used by both cells. For example:
//
-// value: destination data format.
-// If not specified, defaults to "NCHW"
-func DataFormatDimMapDstFormat(value string) DataFormatDimMapAttr {
- return func(m optionalAttr) {
- m["dst_format"] = value
- }
-}
-
-// Returns the dimension index in the destination data format given the one in
+// `index 0 1 2 3 4`
//
-// the source data format.
+// `value 20 5 16 3 7`
//
-// Arguments:
-// x: A Tensor with each element as a dimension index in source data format.
-// Must be in the range [-4, 4).
-//
-// Returns A Tensor with each element as a dimension index in destination data format.
-func DataFormatDimMap(scope *Scope, x tf.Output, optional ...DataFormatDimMapAttr) (y tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "DataFormatDimMap",
- Input: []tf.Input{
- x,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Computes the gradient for the rsqrt of `x` wrt its input.
-//
-// Specifically, `grad = dy * -0.5 * y^3`, where `y = rsqrt(x)`, and `dy`
-// is the corresponding input gradient.
-func RsqrtGrad(scope *Scope, y tf.Output, dy tf.Output) (z tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "RsqrtGrad",
- Input: []tf.Input{
- y, dy,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// MutableHashTableV2Attr is an optional argument to MutableHashTableV2.
-type MutableHashTableV2Attr func(optionalAttr)
-
-// MutableHashTableV2Container sets the optional container attribute to value.
-//
-// value: If non-empty, this table is placed in the given container.
-// Otherwise, a default container is used.
-// If not specified, defaults to ""
-func MutableHashTableV2Container(value string) MutableHashTableV2Attr {
- return func(m optionalAttr) {
- m["container"] = value
- }
-}
-
-// MutableHashTableV2SharedName sets the optional shared_name attribute to value.
-//
-// value: If non-empty, this table is shared under the given name across
-// multiple sessions.
-// If not specified, defaults to ""
-func MutableHashTableV2SharedName(value string) MutableHashTableV2Attr {
- return func(m optionalAttr) {
- m["shared_name"] = value
- }
-}
-
-// MutableHashTableV2UseNodeNameSharing sets the optional use_node_name_sharing attribute to value.
-//
-// value: If true and shared_name is empty, the table is shared
-// using the node name.
+// If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice.
+// The result would be [20, 16] for fractional max pooling.
// If not specified, defaults to false
-func MutableHashTableV2UseNodeNameSharing(value bool) MutableHashTableV2Attr {
+func FractionalMaxPoolGradOverlapping(value bool) FractionalMaxPoolGradAttr {
return func(m optionalAttr) {
- m["use_node_name_sharing"] = value
+ m["overlapping"] = value
}
}
-// Creates an empty hash table.
-//
-// This op creates a mutable hash table, specifying the type of its keys and
-// values. Each value must be a scalar. Data can be inserted into the table using
-// the insert operations. It does not support the initialization operation.
+// Computes gradient of the FractionalMaxPool function.
//
// Arguments:
-// key_dtype: Type of the table keys.
-// value_dtype: Type of the table values.
+// orig_input: Original input for `fractional_max_pool`
+// orig_output: Original output for `fractional_max_pool`
+// out_backprop: 4-D with shape `[batch, height, width, channels]`. Gradients
+// w.r.t. the output of `fractional_max_pool`.
+// row_pooling_sequence: row pooling sequence, form pooling region with
+// col_pooling_sequence.
+// col_pooling_sequence: column pooling sequence, form pooling region with
+// row_pooling sequence.
//
-// Returns Handle to a table.
-func MutableHashTableV2(scope *Scope, key_dtype tf.DataType, value_dtype tf.DataType, optional ...MutableHashTableV2Attr) (table_handle tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"key_dtype": key_dtype, "value_dtype": value_dtype}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "MutableHashTableV2",
-
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Computes the determinant of one or more square matrices.
-//
-// The input is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions
-// form square matrices. The output is a tensor containing the determinants
-// for all input submatrices `[..., :, :]`.
-//
-// Arguments:
-// input: Shape is `[..., M, M]`.
-//
-// Returns Shape is `[...]`.
-func MatrixDeterminant(scope *Scope, input tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "MatrixDeterminant",
- Input: []tf.Input{
- input,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Reduces sparse updates into the variable referenced by `resource` using the `min` operation.
-//
-// This operation computes
-//
-// # Scalar indices
-// ref[indices, ...] = min(ref[indices, ...], updates[...])
-//
-// # Vector indices (for each i)
-// ref[indices[i], ...] = min(ref[indices[i], ...], updates[i, ...])
-//
-// # High rank indices (for each i, ..., j)
-// ref[indices[i, ..., j], ...] = min(ref[indices[i, ..., j], ...], updates[i, ..., j, ...])
-//
-// Duplicate entries are handled correctly: if multiple `indices` reference
-// the same location, their contributions are combined.
-//
-// Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
-//
-//
-//
-//
-// Shai Shalev-Shwartz, Tong Zhang. 2012
-//
-// $$Loss Objective = \sum f_{i} (wx_{i}) + (l2 / 2) * |w|^2 + l1 * |w|$$
-//
-// [Adding vs. Averaging in Distributed Primal-Dual Optimization](http://arxiv.org/abs/1502.03508).
-// Chenxin Ma, Virginia Smith, Martin Jaggi, Michael I. Jordan,
-// Peter Richtarik, Martin Takac. 2015
-//
-// [Stochastic Dual Coordinate Ascent with Adaptive Probabilities](https://arxiv.org/abs/1502.08053).
-// Dominik Csiba, Zheng Qu, Peter Richtarik. 2015
-//
-// Arguments:
-// sparse_example_indices: a list of vectors which contain example indices.
-// sparse_feature_indices: a list of vectors which contain feature indices.
-// sparse_feature_values: a list of vectors which contains feature value
-// associated with each feature group.
-// dense_features: a list of matrices which contains the dense feature values.
-// example_weights: a vector which contains the weight associated with each
-// example.
-// example_labels: a vector which contains the label/target associated with each
-// example.
-// sparse_indices: a list of vectors where each value is the indices which has
-// corresponding weights in sparse_weights. This field maybe omitted for the
-// dense approach.
-// sparse_weights: a list of vectors where each value is the weight associated with
-// a sparse feature group.
-// dense_weights: a list of vectors where the values are the weights associated
-// with a dense feature group.
-// example_state_data: a list of vectors containing the example state data.
-// loss_type: Type of the primal loss. Currently SdcaSolver supports logistic,
-// squared and hinge losses.
-// l1: Symmetric l1 regularization strength.
-// l2: Symmetric l2 regularization strength.
-// num_loss_partitions: Number of partitions of the global loss function.
-// num_inner_iterations: Number of iterations per mini-batch.
-//
-// Returns a list of vectors containing the updated example state
-// data.a list of vectors where each value is the delta
-// weights associated with a sparse feature group.a list of vectors where the values are the delta
-// weights associated with a dense feature group.
-func SdcaOptimizerV2(scope *Scope, sparse_example_indices []tf.Output, sparse_feature_indices []tf.Output, sparse_feature_values []tf.Output, dense_features []tf.Output, example_weights tf.Output, example_labels tf.Output, sparse_indices []tf.Output, sparse_weights []tf.Output, dense_weights []tf.Output, example_state_data tf.Output, loss_type string, l1 float32, l2 float32, num_loss_partitions int64, num_inner_iterations int64, optional ...SdcaOptimizerV2Attr) (out_example_state_data tf.Output, out_delta_sparse_weights []tf.Output, out_delta_dense_weights []tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"loss_type": loss_type, "l1": l1, "l2": l2, "num_loss_partitions": num_loss_partitions, "num_inner_iterations": num_inner_iterations}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "SdcaOptimizerV2",
- Input: []tf.Input{
- tf.OutputList(sparse_example_indices), tf.OutputList(sparse_feature_indices), tf.OutputList(sparse_feature_values), tf.OutputList(dense_features), example_weights, example_labels, tf.OutputList(sparse_indices), tf.OutputList(sparse_weights), tf.OutputList(dense_weights), example_state_data,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- if scope.Err() != nil {
- return
- }
- var idx int
- var err error
- out_example_state_data = op.Output(idx)
- if out_delta_sparse_weights, idx, err = makeOutputList(op, idx, "out_delta_sparse_weights"); err != nil {
- scope.UpdateErr("SdcaOptimizerV2", err)
- return
- }
- if out_delta_dense_weights, idx, err = makeOutputList(op, idx, "out_delta_dense_weights"); err != nil {
- scope.UpdateErr("SdcaOptimizerV2", err)
- return
- }
- return out_example_state_data, out_delta_sparse_weights, out_delta_dense_weights
-}
-
-// Creates a dataset that concatenates `input_dataset` with `another_dataset`.
-func ConcatenateDataset(scope *Scope, input_dataset tf.Output, another_dataset tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"output_types": output_types, "output_shapes": output_shapes}
- opspec := tf.OpSpec{
- Type: "ConcatenateDataset",
- Input: []tf.Input{
- input_dataset, another_dataset,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// 3D fast Fourier transform.
-//
-// Computes the 3-dimensional discrete Fourier transform over the inner-most 3
-// dimensions of `input`.
-//
-// Arguments:
-// input: A complex64 tensor.
-//
-// Returns A complex64 tensor of the same shape as `input`. The inner-most 3
-// dimensions of `input` are replaced with their 3D Fourier transform.
-//
-// @compatibility(numpy)
-// Equivalent to np.fft.fftn with 3 dimensions.
-// @end_compatibility
-func FFT3D(scope *Scope, input tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "FFT3D",
- Input: []tf.Input{
- input,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// LoadTPUEmbeddingProximalAdagradParametersAttr is an optional argument to LoadTPUEmbeddingProximalAdagradParameters.
-type LoadTPUEmbeddingProximalAdagradParametersAttr func(optionalAttr)
-
-// LoadTPUEmbeddingProximalAdagradParametersTableId sets the optional table_id attribute to value.
-// If not specified, defaults to -1
-//
-// REQUIRES: value >= -1
-func LoadTPUEmbeddingProximalAdagradParametersTableId(value int64) LoadTPUEmbeddingProximalAdagradParametersAttr {
- return func(m optionalAttr) {
- m["table_id"] = value
- }
-}
-
-// LoadTPUEmbeddingProximalAdagradParametersTableName sets the optional table_name attribute to value.
-// If not specified, defaults to ""
-func LoadTPUEmbeddingProximalAdagradParametersTableName(value string) LoadTPUEmbeddingProximalAdagradParametersAttr {
- return func(m optionalAttr) {
- m["table_name"] = value
- }
-}
-
-// Load proximal Adagrad embedding parameters.
-//
-// An op that loads optimization parameters into HBM for embedding. Must be
-// preceded by a ConfigureTPUEmbeddingHost op that sets up the correct
-// embedding table configuration. For example, this op is used to install
-// parameters that are loaded from a checkpoint before a training loop is
-// executed.
-//
-// Arguments:
-// parameters: Value of parameters used in the proximal Adagrad optimization algorithm.
-// accumulators: Value of accumulators used in the proximal Adagrad optimization algorithm.
-//
-//
-//
-// Returns the created operation.
-func LoadTPUEmbeddingProximalAdagradParameters(scope *Scope, parameters tf.Output, accumulators tf.Output, num_shards int64, shard_id int64, optional ...LoadTPUEmbeddingProximalAdagradParametersAttr) (o *tf.Operation) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"num_shards": num_shards, "shard_id": shard_id}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "LoadTPUEmbeddingProximalAdagradParameters",
- Input: []tf.Input{
- parameters, accumulators,
- },
- Attrs: attrs,
- }
- return scope.AddOperation(opspec)
-}
-
-// Computes the sum along sparse segments of a tensor.
-//
-// Like `SparseSegmentSum`, but allows missing ids in `segment_ids`. If an id is
-// misisng, the `output` tensor at that position will be zeroed.
-//
-// Read
-// [the section on segmentation](https://tensorflow.org/api_docs/python/tf/sparse#Segmentation)
-// for an explanation of segments.
-//
-// For example:
-//
-// ```python
-// c = tf.constant([[1,2,3,4], [-1,-2,-3,-4], [5,6,7,8]])
-//
-// tf.sparse_segment_sum_with_num_segments(
-// c, tf.constant([0, 1]), tf.constant([0, 0]), num_segments=3)
-// # => [[0 0 0 0]
-// # [0 0 0 0]
-// # [0 0 0 0]]
-//
-// tf.sparse_segment_sum_with_num_segments(c,
-// tf.constant([0, 1]),
-// tf.constant([0, 2],
-// num_segments=4))
-// # => [[ 1 2 3 4]
-// # [ 0 0 0 0]
-// # [-1 -2 -3 -4]
-// # [ 0 0 0 0]]
-// ```
-//
-// Arguments:
-//
-// indices: A 1-D tensor. Has same rank as `segment_ids`.
-// segment_ids: A 1-D tensor. Values should be sorted and can be repeated.
-// num_segments: Should equal the number of distinct segment IDs.
-//
-// Returns Has same shape as data, except for dimension 0 which
-// has size `num_segments`.
-func SparseSegmentSumWithNumSegments(scope *Scope, data tf.Output, indices tf.Output, segment_ids tf.Output, num_segments tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "SparseSegmentSumWithNumSegments",
- Input: []tf.Input{
- data, indices, segment_ids, num_segments,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Computes gradients for the scaled exponential linear (Selu) operation.
-//
-// Arguments:
-// gradients: The backpropagated gradients to the corresponding Selu operation.
-// outputs: The outputs of the corresponding Selu operation.
-//
-// Returns The gradients: `gradients * (outputs + scale * alpha)`
-// if outputs < 0, `scale * gradients` otherwise.
-func SeluGrad(scope *Scope, gradients tf.Output, outputs tf.Output) (backprops tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "SeluGrad",
- Input: []tf.Input{
- gradients, outputs,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// RandomGammaAttr is an optional argument to RandomGamma.
-type RandomGammaAttr func(optionalAttr)
-
-// RandomGammaSeed sets the optional seed attribute to value.
-//
-// value: If either `seed` or `seed2` are set to be non-zero, the random number
-// generator is seeded by the given seed. Otherwise, it is seeded by a
-// random seed.
-// If not specified, defaults to 0
-func RandomGammaSeed(value int64) RandomGammaAttr {
- return func(m optionalAttr) {
- m["seed"] = value
- }
-}
-
-// RandomGammaSeed2 sets the optional seed2 attribute to value.
-//
-// value: A second seed to avoid seed collision.
-// If not specified, defaults to 0
-func RandomGammaSeed2(value int64) RandomGammaAttr {
- return func(m optionalAttr) {
- m["seed2"] = value
- }
-}
-
-// Outputs random values from the Gamma distribution(s) described by alpha.
-//
-// This op uses the algorithm by Marsaglia et al. to acquire samples via
-// transformation-rejection from pairs of uniform and normal random variables.
-// See http://dl.acm.org/citation.cfm?id=358414
-//
-// Arguments:
-// shape: 1-D integer tensor. Shape of independent samples to draw from each
-// distribution described by the shape parameters given in alpha.
-// alpha: A tensor in which each scalar is a "shape" parameter describing the
-// associated gamma distribution.
-//
-// Returns A tensor with shape `shape + shape(alpha)`. Each slice
-// `[:, ..., :, i0, i1, ...iN]` contains the samples drawn for
-// `alpha[i0, i1, ...iN]`. The dtype of the output matches the dtype of alpha.
-func RandomGamma(scope *Scope, shape tf.Output, alpha tf.Output, optional ...RandomGammaAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "RandomGamma",
- Input: []tf.Input{
- shape, alpha,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// MapClearAttr is an optional argument to MapClear.
-type MapClearAttr func(optionalAttr)
-
-// MapClearCapacity sets the optional capacity attribute to value.
-// If not specified, defaults to 0
-//
-// REQUIRES: value >= 0
-func MapClearCapacity(value int64) MapClearAttr {
- return func(m optionalAttr) {
- m["capacity"] = value
- }
-}
-
-// MapClearMemoryLimit sets the optional memory_limit attribute to value.
-// If not specified, defaults to 0
-//
-// REQUIRES: value >= 0
-func MapClearMemoryLimit(value int64) MapClearAttr {
- return func(m optionalAttr) {
- m["memory_limit"] = value
- }
-}
-
-// MapClearContainer sets the optional container attribute to value.
-// If not specified, defaults to ""
-func MapClearContainer(value string) MapClearAttr {
- return func(m optionalAttr) {
- m["container"] = value
- }
-}
-
-// MapClearSharedName sets the optional shared_name attribute to value.
-// If not specified, defaults to ""
-func MapClearSharedName(value string) MapClearAttr {
- return func(m optionalAttr) {
- m["shared_name"] = value
- }
-}
-
-// Op removes all elements in the underlying container.
-//
-// Returns the created operation.
-func MapClear(scope *Scope, dtypes []tf.DataType, optional ...MapClearAttr) (o *tf.Operation) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"dtypes": dtypes}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "MapClear",
-
- Attrs: attrs,
- }
- return scope.AddOperation(opspec)
-}
-
-// Creates a sequence of numbers.
-//
-// This operation creates a sequence of numbers that begins at `start` and
-// extends by increments of `delta` up to but not including `limit`.
-//
-// For example:
-//
-// ```
-// # 'start' is 3
-// # 'limit' is 18
-// # 'delta' is 3
-// tf.range(start, limit, delta) ==> [3, 6, 9, 12, 15]
-// ```
-//
-// Arguments:
-// start: 0-D (scalar). First entry in the sequence.
-// limit: 0-D (scalar). Upper limit of sequence, exclusive.
-// delta: 0-D (scalar). Optional. Default is 1. Number that increments `start`.
-//
-// Returns 1-D.
-func Range(scope *Scope, start tf.Output, limit tf.Output, delta tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "Range",
- Input: []tf.Input{
- start, limit, delta,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// FractionalAvgPoolAttr is an optional argument to FractionalAvgPool.
-type FractionalAvgPoolAttr func(optionalAttr)
-
-// FractionalAvgPoolPseudoRandom sets the optional pseudo_random attribute to value.
-//
-// value: When set to True, generates the pooling sequence in a
-// pseudorandom fashion, otherwise, in a random fashion. Check paper [Benjamin
-// Graham, Fractional Max-Pooling](http://arxiv.org/abs/1412.6071) for
-// difference between pseudorandom and random.
-// If not specified, defaults to false
-func FractionalAvgPoolPseudoRandom(value bool) FractionalAvgPoolAttr {
- return func(m optionalAttr) {
- m["pseudo_random"] = value
- }
-}
-
-// FractionalAvgPoolOverlapping sets the optional overlapping attribute to value.
-//
-// value: When set to True, it means when pooling, the values at the boundary
-// of adjacent pooling cells are used by both cells. For example:
-//
-// `index 0 1 2 3 4`
-//
-// `value 20 5 16 3 7`
-//
-// If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice.
-// The result would be [41/3, 26/3] for fractional avg pooling.
-// If not specified, defaults to false
-func FractionalAvgPoolOverlapping(value bool) FractionalAvgPoolAttr {
- return func(m optionalAttr) {
- m["overlapping"] = value
- }
-}
-
-// FractionalAvgPoolDeterministic sets the optional deterministic attribute to value.
-//
-// value: When set to True, a fixed pooling region will be used when
-// iterating over a FractionalAvgPool node in the computation graph. Mainly used
-// in unit test to make FractionalAvgPool deterministic.
-// If not specified, defaults to false
-func FractionalAvgPoolDeterministic(value bool) FractionalAvgPoolAttr {
- return func(m optionalAttr) {
- m["deterministic"] = value
- }
-}
-
-// FractionalAvgPoolSeed sets the optional seed attribute to value.
-//
-// value: If either seed or seed2 are set to be non-zero, the random number
-// generator is seeded by the given seed. Otherwise, it is seeded by a
-// random seed.
-// If not specified, defaults to 0
-func FractionalAvgPoolSeed(value int64) FractionalAvgPoolAttr {
- return func(m optionalAttr) {
- m["seed"] = value
- }
-}
-
-// FractionalAvgPoolSeed2 sets the optional seed2 attribute to value.
-//
-// value: An second seed to avoid seed collision.
-// If not specified, defaults to 0
-func FractionalAvgPoolSeed2(value int64) FractionalAvgPoolAttr {
- return func(m optionalAttr) {
- m["seed2"] = value
- }
-}
-
-// Performs fractional average pooling on the input.
-//
-// Fractional average pooling is similar to Fractional max pooling in the pooling
-// region generation step. The only difference is that after pooling regions are
-// generated, a mean operation is performed instead of a max operation in each
-// pooling region.
-//
-// Arguments:
-// value: 4-D with shape `[batch, height, width, channels]`.
-// pooling_ratio: Pooling ratio for each dimension of `value`, currently only
-// supports row and col dimension and should be >= 1.0. For example, a valid
-// pooling ratio looks like [1.0, 1.44, 1.73, 1.0]. The first and last elements
-// must be 1.0 because we don't allow pooling on batch and channels
-// dimensions. 1.44 and 1.73 are pooling ratio on height and width dimensions
-// respectively.
-//
-// Returns output tensor after fractional avg pooling.row pooling sequence, needed to calculate gradient.column pooling sequence, needed to calculate gradient.
-func FractionalAvgPool(scope *Scope, value tf.Output, pooling_ratio []float32, optional ...FractionalAvgPoolAttr) (output tf.Output, row_pooling_sequence tf.Output, col_pooling_sequence tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"pooling_ratio": pooling_ratio}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "FractionalAvgPool",
- Input: []tf.Input{
- value,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1), op.Output(2)
-}
-
-// BiasAddAttr is an optional argument to BiasAdd.
-type BiasAddAttr func(optionalAttr)
-
-// BiasAddDataFormat sets the optional data_format attribute to value.
-//
-// value: Specify the data format of the input and output data. With the
-// default format "NHWC", the bias tensor will be added to the last dimension
-// of the value tensor.
-// Alternatively, the format could be "NCHW", the data storage order of:
-// [batch, in_channels, in_height, in_width].
-// The tensor will be added to "in_channels", the third-to-the-last
-// dimension.
-// If not specified, defaults to "NHWC"
-func BiasAddDataFormat(value string) BiasAddAttr {
- return func(m optionalAttr) {
- m["data_format"] = value
- }
-}
-
-// Adds `bias` to `value`.
-//
-// This is a special case of `tf.add` where `bias` is restricted to be 1-D.
-// Broadcasting is supported, so `value` may have any number of dimensions.
-//
-// Arguments:
-// value: Any number of dimensions.
-// bias: 1-D with size the last dimension of `value`.
-//
-// Returns Broadcasted sum of `value` and `bias`.
-func BiasAdd(scope *Scope, value tf.Output, bias tf.Output, optional ...BiasAddAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "BiasAdd",
- Input: []tf.Input{
- value, bias,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// StatefulTruncatedNormalAttr is an optional argument to StatefulTruncatedNormal.
-type StatefulTruncatedNormalAttr func(optionalAttr)
-
-// StatefulTruncatedNormalDtype sets the optional dtype attribute to value.
-//
-// value: The type of the output.
-// If not specified, defaults to DT_FLOAT
-func StatefulTruncatedNormalDtype(value tf.DataType) StatefulTruncatedNormalAttr {
- return func(m optionalAttr) {
- m["dtype"] = value
- }
-}
-
-// Outputs random values from a truncated normal distribution.
-//
-// The generated values follow a normal distribution with mean 0 and standard
-// deviation 1, except that values whose magnitude is more than 2 standard
-// deviations from the mean are dropped and re-picked.
-//
-// Arguments:
-// resource: The handle of the resource variable that stores the state of the RNG.
-// algorithm: The RNG algorithm.
-// shape: The shape of the output tensor.
-//
-// Returns Random values with specified shape.
-func StatefulTruncatedNormal(scope *Scope, resource tf.Output, algorithm tf.Output, shape tf.Output, optional ...StatefulTruncatedNormalAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "StatefulTruncatedNormal",
- Input: []tf.Input{
- resource, algorithm, shape,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Calculates gains for each feature and returns the best possible split information for the feature.
-//
-// The split information is the best threshold (bucket id), gains and left/right node contributions per node for each feature.
-//
-// It is possible that not all nodes can be split on each feature. Hence, the list of possible nodes can differ between the features. Therefore, we return `node_ids_list` for each feature, containing the list of nodes that this feature can be used to split.
-//
-// In this manner, the output is the best split per features and per node, so that it needs to be combined later to produce the best split for each node (among all possible features).
-//
-// The length of output lists are all of the same length, `num_features`.
-// The output shapes are compatible in a way that the first dimension of all tensors of all lists are the same and equal to the number of possible split nodes for each feature.
-//
-// Arguments:
-// node_id_range: A Rank 1 tensor (shape=[2]) to specify the range [first, last) of node ids to process within `stats_summary_list`. The nodes are iterated between the two nodes specified by the tensor, as like `for node_id in range(node_id_range[0], node_id_range[1])` (Note that the last index node_id_range[1] is exclusive).
-// stats_summary_list: A list of Rank 3 tensor (#shape=[max_splits, bucket, 2]) for accumulated stats summary (gradient/hessian) per node per buckets for each feature. The first dimension of the tensor is the maximum number of splits, and thus not all elements of it will be used, but only the indexes specified by node_ids will be used.
-// l1: l1 regularization factor on leaf weights, per instance based.
-// l2: l2 regularization factor on leaf weights, per instance based.
-// tree_complexity: adjustment to the gain, per leaf based.
-// min_node_weight: mininum avg of hessians in a node before required for the node to be considered for splitting.
-// max_splits: the number of nodes that can be split in the whole tree. Used as a dimension of output tensors.
-//
-// Returns An output list of Rank 1 tensors indicating possible split node ids for each feature. The length of the list is num_features, but each tensor has different size as each feature provides different possible nodes. See above for details like shapes and sizes.An output list of Rank 1 tensors indicating the best gains for each feature to split for certain nodes. See above for details like shapes and sizes.An output list of Rank 1 tensors indicating the bucket id to compare with (as a threshold) for split in each node. See above for details like shapes and sizes.A list of Rank 2 tensors indicating the contribution of the left nodes when branching from parent nodes (given by the tensor element in the output node_ids_list) to the left direction by the given threshold for each feature. This value will be used to make the left node value by adding to the parent node value. Second dimension size is 1 for 1-dimensional logits, but would be larger for multi-class problems. See above for details like shapes and sizes.A list of Rank 2 tensors, with the same shape/conditions as left_node_contribs_list, but just that the value is for the right node.
-func BoostedTreesCalculateBestGainsPerFeature(scope *Scope, node_id_range tf.Output, stats_summary_list []tf.Output, l1 tf.Output, l2 tf.Output, tree_complexity tf.Output, min_node_weight tf.Output, max_splits int64) (node_ids_list []tf.Output, gains_list []tf.Output, thresholds_list []tf.Output, left_node_contribs_list []tf.Output, right_node_contribs_list []tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"max_splits": max_splits}
- opspec := tf.OpSpec{
- Type: "BoostedTreesCalculateBestGainsPerFeature",
- Input: []tf.Input{
- node_id_range, tf.OutputList(stats_summary_list), l1, l2, tree_complexity, min_node_weight,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- if scope.Err() != nil {
- return
- }
- var idx int
- var err error
- if node_ids_list, idx, err = makeOutputList(op, idx, "node_ids_list"); err != nil {
- scope.UpdateErr("BoostedTreesCalculateBestGainsPerFeature", err)
- return
- }
- if gains_list, idx, err = makeOutputList(op, idx, "gains_list"); err != nil {
- scope.UpdateErr("BoostedTreesCalculateBestGainsPerFeature", err)
- return
- }
- if thresholds_list, idx, err = makeOutputList(op, idx, "thresholds_list"); err != nil {
- scope.UpdateErr("BoostedTreesCalculateBestGainsPerFeature", err)
- return
- }
- if left_node_contribs_list, idx, err = makeOutputList(op, idx, "left_node_contribs_list"); err != nil {
- scope.UpdateErr("BoostedTreesCalculateBestGainsPerFeature", err)
- return
- }
- if right_node_contribs_list, idx, err = makeOutputList(op, idx, "right_node_contribs_list"); err != nil {
- scope.UpdateErr("BoostedTreesCalculateBestGainsPerFeature", err)
- return
- }
- return node_ids_list, gains_list, thresholds_list, left_node_contribs_list, right_node_contribs_list
-}
-
-// Enqueue multiple Tensor values on the computation outfeed.
-//
-// Arguments:
-// inputs: A list of tensors that will be inserted into the outfeed queue as an
-// XLA tuple.
-//
-// Returns the created operation.
-func OutfeedEnqueueTuple(scope *Scope, inputs []tf.Output) (o *tf.Operation) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "OutfeedEnqueueTuple",
- Input: []tf.Input{
- tf.OutputList(inputs),
- },
- }
- return scope.AddOperation(opspec)
-}
-
-// DecodeCSVAttr is an optional argument to DecodeCSV.
-type DecodeCSVAttr func(optionalAttr)
-
-// DecodeCSVFieldDelim sets the optional field_delim attribute to value.
-//
-// value: char delimiter to separate fields in a record.
-// If not specified, defaults to ","
-func DecodeCSVFieldDelim(value string) DecodeCSVAttr {
- return func(m optionalAttr) {
- m["field_delim"] = value
- }
-}
-
-// DecodeCSVUseQuoteDelim sets the optional use_quote_delim attribute to value.
-//
-// value: If false, treats double quotation marks as regular
-// characters inside of the string fields (ignoring RFC 4180, Section 2,
-// Bullet 5).
-// If not specified, defaults to true
-func DecodeCSVUseQuoteDelim(value bool) DecodeCSVAttr {
- return func(m optionalAttr) {
- m["use_quote_delim"] = value
- }
-}
-
-// DecodeCSVNaValue sets the optional na_value attribute to value.
-//
-// value: Additional string to recognize as NA/NaN.
-// If not specified, defaults to ""
-func DecodeCSVNaValue(value string) DecodeCSVAttr {
- return func(m optionalAttr) {
- m["na_value"] = value
- }
-}
-
-// DecodeCSVSelectCols sets the optional select_cols attribute to value.
-// If not specified, defaults to <>
-func DecodeCSVSelectCols(value []int64) DecodeCSVAttr {
- return func(m optionalAttr) {
- m["select_cols"] = value
- }
-}
-
-// Convert CSV records to tensors. Each column maps to one tensor.
-//
-// RFC 4180 format is expected for the CSV records.
-// (https://tools.ietf.org/html/rfc4180)
-// Note that we allow leading and trailing spaces with int or float field.
-//
-// Arguments:
-// records: Each string is a record/row in the csv and all records should have
-// the same format.
-// record_defaults: One tensor per column of the input record, with either a
-// scalar default value for that column or an empty vector if the column is
-// required.
-//
-// Returns Each tensor will have the same shape as records.
-func DecodeCSV(scope *Scope, records tf.Output, record_defaults []tf.Output, optional ...DecodeCSVAttr) (output []tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "DecodeCSV",
- Input: []tf.Input{
- records, tf.OutputList(record_defaults),
+ axis, value,
},
Attrs: attrs,
}
@@ -27304,37 +27602,12 @@ func DecodeCSV(scope *Scope, records tf.Output, record_defaults []tf.Output, opt
var idx int
var err error
if output, idx, err = makeOutputList(op, idx, "output"); err != nil {
- scope.UpdateErr("DecodeCSV", err)
+ scope.UpdateErr("Split", err)
return
}
return output
}
-// A substitute for `InterleaveDataset` on a fixed list of `N` datasets.
-//
-// Arguments:
-// selector_input_dataset: A dataset of scalar `DT_INT64` elements that determines which of the
-// `N` data inputs should produce the next output element.
-// data_input_datasets: `N` datasets with the same type that will be interleaved according to
-// the values of `selector_input_dataset`.
-//
-//
-func ExperimentalDirectedInterleaveDataset(scope *Scope, selector_input_dataset tf.Output, data_input_datasets []tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"output_types": output_types, "output_shapes": output_shapes}
- opspec := tf.OpSpec{
- Type: "ExperimentalDirectedInterleaveDataset",
- Input: []tf.Input{
- selector_input_dataset, tf.OutputList(data_input_datasets),
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
// Computes softmax activations.
//
// For each batch `i` and class `j` we have
@@ -27359,36 +27632,6 @@ func Softmax(scope *Scope, logits tf.Output) (softmax tf.Output) {
return op.Output(0)
}
-// An Op to sum inputs across replicated TPU instances.
-//
-// Each instance supplies its own input.
-//
-// For example, suppose there are 8 TPU instances: `[A, B, C, D, E, F, G, H]`.
-// Passing group_assignment=`[[0,2,4,6],[1,3,5,7]]` sets `A, C, E, G` as group 0,
-// and `B, D, F, H` as group 1. Thus we get the outputs:
-// `[A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H]`.
-//
-// Arguments:
-// input: The local input to the sum.
-// group_assignment: An int32 tensor with shape
-// [num_groups, num_replicas_per_group]. `group_assignment[i]` represents the
-// replica ids in the ith subgroup.
-//
-// Returns The sum of all the distributed inputs.
-func CrossReplicaSum(scope *Scope, input tf.Output, group_assignment tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "CrossReplicaSum",
- Input: []tf.Input{
- input, group_assignment,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
// ResourceScatterNdAddAttr is an optional argument to ResourceScatterNdAdd.
type ResourceScatterNdAddAttr func(optionalAttr)
@@ -27466,74 +27709,117 @@ func ResourceScatterNdAdd(scope *Scope, ref tf.Output, indices tf.Output, update
return scope.AddOperation(opspec)
}
-// Decode the frame(s) of a GIF-encoded image to a uint8 tensor.
+// FractionalAvgPoolGradAttr is an optional argument to FractionalAvgPoolGrad.
+type FractionalAvgPoolGradAttr func(optionalAttr)
+
+// FractionalAvgPoolGradOverlapping sets the optional overlapping attribute to value.
//
-// GIF images with frame or transparency compression are not supported.
-// On Linux and MacOS systems, convert animated GIFs from compressed to
-// uncompressed by running:
+// value: When set to True, it means when pooling, the values at the boundary
+// of adjacent pooling cells are used by both cells. For example:
//
-// convert $src.gif -coalesce $dst.gif
+// `index 0 1 2 3 4`
//
-// This op also supports decoding JPEGs and PNGs, though it is cleaner to use
-// `tf.image.decode_image`.
+// `value 20 5 16 3 7`
+//
+// If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice.
+// The result would be [41/3, 26/3] for fractional avg pooling.
+// If not specified, defaults to false
+func FractionalAvgPoolGradOverlapping(value bool) FractionalAvgPoolGradAttr {
+ return func(m optionalAttr) {
+ m["overlapping"] = value
+ }
+}
+
+// Computes gradient of the FractionalAvgPool function.
+//
+// Unlike FractionalMaxPoolGrad, we don't need to find arg_max for
+// FractionalAvgPoolGrad, we just need to evenly back-propagate each element of
+// out_backprop to those indices that form the same pooling cell. Therefore, we
+// just need to know the shape of original input tensor, instead of the whole
+// tensor.
//
// Arguments:
-// contents: 0-D. The GIF-encoded image.
+// orig_input_tensor_shape: Original input tensor shape for `fractional_avg_pool`
+// out_backprop: 4-D with shape `[batch, height, width, channels]`. Gradients
+// w.r.t. the output of `fractional_avg_pool`.
+// row_pooling_sequence: row pooling sequence, form pooling region with
+// col_pooling_sequence.
+// col_pooling_sequence: column pooling sequence, form pooling region with
+// row_pooling sequence.
//
-// Returns 4-D with shape `[num_frames, height, width, 3]`. RGB channel order.
-func DecodeGif(scope *Scope, contents tf.Output) (image tf.Output) {
+// Returns 4-D. Gradients w.r.t. the input of `fractional_avg_pool`.
+func FractionalAvgPoolGrad(scope *Scope, orig_input_tensor_shape tf.Output, out_backprop tf.Output, row_pooling_sequence tf.Output, col_pooling_sequence tf.Output, optional ...FractionalAvgPoolGradAttr) (output tf.Output) {
if scope.Err() != nil {
return
}
+ attrs := map[string]interface{}{}
+ for _, a := range optional {
+ a(attrs)
+ }
opspec := tf.OpSpec{
- Type: "DecodeGif",
+ Type: "FractionalAvgPoolGrad",
Input: []tf.Input{
- contents,
+ orig_input_tensor_shape, out_backprop, row_pooling_sequence, col_pooling_sequence,
},
+ Attrs: attrs,
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
-// LoadTPUEmbeddingADAMParametersGradAccumDebugAttr is an optional argument to LoadTPUEmbeddingADAMParametersGradAccumDebug.
-type LoadTPUEmbeddingADAMParametersGradAccumDebugAttr func(optionalAttr)
+// Subtracts a value from the current value of a variable.
+//
+// Any ReadVariableOp with a control dependency on this op is guaranteed to
+// see the decremented value or a subsequent newer one.
+//
+// Arguments:
+// resource: handle to the resource in which to store the variable.
+// value: the value by which the variable will be incremented.
+//
+// Returns the created operation.
+func AssignSubVariableOp(scope *Scope, resource tf.Output, value tf.Output) (o *tf.Operation) {
+ if scope.Err() != nil {
+ return
+ }
+ opspec := tf.OpSpec{
+ Type: "AssignSubVariableOp",
+ Input: []tf.Input{
+ resource, value,
+ },
+ }
+ return scope.AddOperation(opspec)
+}
-// LoadTPUEmbeddingADAMParametersGradAccumDebugTableId sets the optional table_id attribute to value.
+// RetrieveTPUEmbeddingFTRLParametersAttr is an optional argument to RetrieveTPUEmbeddingFTRLParameters.
+type RetrieveTPUEmbeddingFTRLParametersAttr func(optionalAttr)
+
+// RetrieveTPUEmbeddingFTRLParametersTableId sets the optional table_id attribute to value.
// If not specified, defaults to -1
//
// REQUIRES: value >= -1
-func LoadTPUEmbeddingADAMParametersGradAccumDebugTableId(value int64) LoadTPUEmbeddingADAMParametersGradAccumDebugAttr {
+func RetrieveTPUEmbeddingFTRLParametersTableId(value int64) RetrieveTPUEmbeddingFTRLParametersAttr {
return func(m optionalAttr) {
m["table_id"] = value
}
}
-// LoadTPUEmbeddingADAMParametersGradAccumDebugTableName sets the optional table_name attribute to value.
+// RetrieveTPUEmbeddingFTRLParametersTableName sets the optional table_name attribute to value.
// If not specified, defaults to ""
-func LoadTPUEmbeddingADAMParametersGradAccumDebugTableName(value string) LoadTPUEmbeddingADAMParametersGradAccumDebugAttr {
+func RetrieveTPUEmbeddingFTRLParametersTableName(value string) RetrieveTPUEmbeddingFTRLParametersAttr {
return func(m optionalAttr) {
m["table_name"] = value
}
}
-// Load ADAM embedding parameters with debug support.
+// Retrieve FTRL embedding parameters.
//
-// An op that loads optimization parameters into HBM for embedding. Must be
-// preceded by a ConfigureTPUEmbeddingHost op that sets up the correct
-// embedding table configuration. For example, this op is used to install
-// parameters that are loaded from a checkpoint before a training loop is
-// executed.
+// An op that retrieves optimization parameters from embedding to host
+// memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up
+// the correct embedding table configuration. For example, this op is
+// used to retrieve updated parameters before saving a checkpoint.
//
-// Arguments:
-// parameters: Value of parameters used in the ADAM optimization algorithm.
-// momenta: Value of momenta used in the ADAM optimization algorithm.
-// velocities: Value of velocities used in the ADAM optimization algorithm.
-// gradient_accumulators: Value of gradient_accumulators used in the ADAM optimization algorithm.
-//
-//
-//
-// Returns the created operation.
-func LoadTPUEmbeddingADAMParametersGradAccumDebug(scope *Scope, parameters tf.Output, momenta tf.Output, velocities tf.Output, gradient_accumulators tf.Output, num_shards int64, shard_id int64, optional ...LoadTPUEmbeddingADAMParametersGradAccumDebugAttr) (o *tf.Operation) {
+// Returns Parameter parameters updated by the FTRL optimization algorithm.Parameter accumulators updated by the FTRL optimization algorithm.Parameter linears updated by the FTRL optimization algorithm.
+func RetrieveTPUEmbeddingFTRLParameters(scope *Scope, num_shards int64, shard_id int64, optional ...RetrieveTPUEmbeddingFTRLParametersAttr) (parameters tf.Output, accumulators tf.Output, linears tf.Output) {
if scope.Err() != nil {
return
}
@@ -27542,214 +27828,69 @@ func LoadTPUEmbeddingADAMParametersGradAccumDebug(scope *Scope, parameters tf.Ou
a(attrs)
}
opspec := tf.OpSpec{
- Type: "LoadTPUEmbeddingADAMParametersGradAccumDebug",
- Input: []tf.Input{
- parameters, momenta, velocities, gradient_accumulators,
- },
+ Type: "RetrieveTPUEmbeddingFTRLParameters",
+
Attrs: attrs,
}
+ op := scope.AddOperation(opspec)
+ return op.Output(0), op.Output(1), op.Output(2)
+}
+
+// Computes inverse hyperbolic sine of x element-wise.
+func Asinh(scope *Scope, x tf.Output) (y tf.Output) {
+ if scope.Err() != nil {
+ return
+ }
+ opspec := tf.OpSpec{
+ Type: "Asinh",
+ Input: []tf.Input{
+ x,
+ },
+ }
+ op := scope.AddOperation(opspec)
+ return op.Output(0)
+}
+
+// Deserializes a serialized tree ensemble config and replaces current tree
+//
+// ensemble.
+//
+// Arguments:
+// tree_ensemble_handle: Handle to the tree ensemble.
+// stamp_token: Token to use as the new value of the resource stamp.
+// tree_ensemble_serialized: Serialized proto of the ensemble.
+//
+// Returns the created operation.
+func BoostedTreesDeserializeEnsemble(scope *Scope, tree_ensemble_handle tf.Output, stamp_token tf.Output, tree_ensemble_serialized tf.Output) (o *tf.Operation) {
+ if scope.Err() != nil {
+ return
+ }
+ opspec := tf.OpSpec{
+ Type: "BoostedTreesDeserializeEnsemble",
+ Input: []tf.Input{
+ tree_ensemble_handle, stamp_token, tree_ensemble_serialized,
+ },
+ }
return scope.AddOperation(opspec)
}
-// AngleAttr is an optional argument to Angle.
-type AngleAttr func(optionalAttr)
-
-// AngleTout sets the optional Tout attribute to value.
-// If not specified, defaults to DT_FLOAT
-func AngleTout(value tf.DataType) AngleAttr {
- return func(m optionalAttr) {
- m["Tout"] = value
- }
-}
-
-// Returns the argument of a complex number.
-//
-// Given a tensor `input` of complex numbers, this operation returns a tensor of
-// type `float` that is the argument of each element in `input`. All elements in
-// `input` must be complex numbers of the form \\(a + bj\\), where *a*
-// is the real part and *b* is the imaginary part.
-//
-// The argument returned by this operation is of the form \\(atan2(b, a)\\).
-//
-// For example:
-//
-// ```
-// # tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j]
-// tf.angle(input) ==> [2.0132, 1.056]
-// ```
-//
-// @compatibility(numpy)
-// Equivalent to np.angle.
-// @end_compatibility
-func Angle(scope *Scope, input tf.Output, optional ...AngleAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "Angle",
- Input: []tf.Input{
- input,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Returns the element-wise min of two SparseTensors.
-//
-// Assumes the two SparseTensors have the same shape, i.e., no broadcasting.
+// Creates a dataset that emits the outputs of `input_dataset` `count` times.
//
// Arguments:
-// a_indices: 2-D. `N x R` matrix with the indices of non-empty values in a
-// SparseTensor, in the canonical lexicographic ordering.
-// a_values: 1-D. `N` non-empty values corresponding to `a_indices`.
-// a_shape: 1-D. Shape of the input SparseTensor.
-// b_indices: counterpart to `a_indices` for the other operand.
-// b_values: counterpart to `a_values` for the other operand; must be of the same dtype.
-// b_shape: counterpart to `a_shape` for the other operand; the two shapes must be equal.
//
-// Returns 2-D. The indices of the output SparseTensor.1-D. The values of the output SparseTensor.
-func SparseSparseMinimum(scope *Scope, a_indices tf.Output, a_values tf.Output, a_shape tf.Output, b_indices tf.Output, b_values tf.Output, b_shape tf.Output) (output_indices tf.Output, output_values tf.Output) {
+// count: A scalar representing the number of times that `input_dataset` should
+// be repeated. A value of `-1` indicates that it should be repeated infinitely.
+//
+//
+func RepeatDataset(scope *Scope, input_dataset tf.Output, count tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output) {
if scope.Err() != nil {
return
}
+ attrs := map[string]interface{}{"output_types": output_types, "output_shapes": output_shapes}
opspec := tf.OpSpec{
- Type: "SparseSparseMinimum",
+ Type: "RepeatDataset",
Input: []tf.Input{
- a_indices, a_values, a_shape, b_indices, b_values, b_shape,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1)
-}
-
-// Clips tensor values to a specified min and max.
-//
-// Given a tensor `t`, this operation returns a tensor of the same type and
-// shape as `t` with its values clipped to `clip_value_min` and `clip_value_max`.
-// Any values less than `clip_value_min` are set to `clip_value_min`. Any values
-// greater than `clip_value_max` are set to `clip_value_max`.
-//
-// Arguments:
-// t: A `Tensor`.
-// clip_value_min: A 0-D (scalar) `Tensor`, or a `Tensor` with the same shape
-// as `t`. The minimum value to clip by.
-// clip_value_max: A 0-D (scalar) `Tensor`, or a `Tensor` with the same shape
-// as `t`. The maximum value to clip by.
-//
-// Returns A clipped `Tensor` with the same shape as input 't'.
-func ClipByValue(scope *Scope, t tf.Output, clip_value_min tf.Output, clip_value_max tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "ClipByValue",
- Input: []tf.Input{
- t, clip_value_min, clip_value_max,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// MatrixTriangularSolveAttr is an optional argument to MatrixTriangularSolve.
-type MatrixTriangularSolveAttr func(optionalAttr)
-
-// MatrixTriangularSolveLower sets the optional lower attribute to value.
-//
-// value: Boolean indicating whether the innermost matrices in `matrix` are
-// lower or upper triangular.
-// If not specified, defaults to true
-func MatrixTriangularSolveLower(value bool) MatrixTriangularSolveAttr {
- return func(m optionalAttr) {
- m["lower"] = value
- }
-}
-
-// MatrixTriangularSolveAdjoint sets the optional adjoint attribute to value.
-//
-// value: Boolean indicating whether to solve with `matrix` or its (block-wise)
-// adjoint.
-//
-// @compatibility(numpy)
-// Equivalent to scipy.linalg.solve_triangular
-// @end_compatibility
-// If not specified, defaults to false
-func MatrixTriangularSolveAdjoint(value bool) MatrixTriangularSolveAttr {
- return func(m optionalAttr) {
- m["adjoint"] = value
- }
-}
-
-// Solves systems of linear equations with upper or lower triangular matrices by backsubstitution.
-//
-//
-// `matrix` is a tensor of shape `[..., M, M]` whose inner-most 2 dimensions form
-// square matrices. If `lower` is `True` then the strictly upper triangular part
-// of each inner-most matrix is assumed to be zero and not accessed.
-// If `lower` is False then the strictly lower triangular part of each inner-most
-// matrix is assumed to be zero and not accessed.
-// `rhs` is a tensor of shape `[..., M, K]`.
-//
-// The output is a tensor of shape `[..., M, K]`. If `adjoint` is
-// `True` then the innermost matrices in `output` satisfy matrix equations
-// `matrix[..., :, :] * output[..., :, :] = rhs[..., :, :]`.
-// If `adjoint` is `False` then the strictly then the innermost matrices in
-// `output` satisfy matrix equations
-// `adjoint(matrix[..., i, k]) * output[..., k, j] = rhs[..., i, j]`.
-//
-// Example:
-// ```python
-//
-// a = tf.constant([[3, 0, 0, 0],
-// [2, 1, 0, 0],
-// [1, 0, 1, 0],
-// [1, 1, 1, 1]], dtype=tf.float32)
-//
-// b = tf.constant([[4],
-// [2],
-// [4],
-// [2]], dtype=tf.float32)
-//
-// x = tf.linalg.triangular_solve(a, b, lower=True)
-// x
-// #
-//
-// # in python3 one can use `a@x`
-// tf.matmul(a, x)
-// #
-// ```
-//
-// Arguments:
-// matrix: Shape is `[..., M, M]`.
-// rhs: Shape is `[..., M, K]`.
-//
-// Returns Shape is `[..., M, K]`.
-func MatrixTriangularSolve(scope *Scope, matrix tf.Output, rhs tf.Output, optional ...MatrixTriangularSolveAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "MatrixTriangularSolve",
- Input: []tf.Input{
- matrix, rhs,
+ input_dataset, count,
},
Attrs: attrs,
}
@@ -27904,52 +28045,6 @@ func StringFormat(scope *Scope, inputs []tf.Output, optional ...StringFormatAttr
return op.Output(0)
}
-// Greedily selects a subset of bounding boxes in descending order of score,
-//
-// pruning away boxes that have high intersection-over-union (IOU) overlap
-// with previously selected boxes. Bounding boxes are supplied as
-// [y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any
-// diagonal pair of box corners and the coordinates can be provided as normalized
-// (i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm
-// is agnostic to where the origin is in the coordinate system. Note that this
-// algorithm is invariant to orthogonal transformations and translations
-// of the coordinate system; thus translating or reflections of the coordinate
-// system result in the same boxes being selected by the algorithm.
-//
-// The output of this operation is a set of integers indexing into the input
-// collection of bounding boxes representing the selected boxes. The bounding
-// box coordinates corresponding to the selected indices can then be obtained
-// using the `tf.gather operation`. For example:
-//
-// selected_indices = tf.image.non_max_suppression_v2(
-// boxes, scores, max_output_size, iou_threshold)
-// selected_boxes = tf.gather(boxes, selected_indices)
-//
-// Arguments:
-// boxes: A 2-D float tensor of shape `[num_boxes, 4]`.
-// scores: A 1-D float tensor of shape `[num_boxes]` representing a single
-// score corresponding to each box (each row of boxes).
-// max_output_size: A scalar integer tensor representing the maximum number of
-// boxes to be selected by non max suppression.
-// iou_threshold: A 0-D float tensor representing the threshold for deciding whether
-// boxes overlap too much with respect to IOU.
-//
-// Returns A 1-D integer tensor of shape `[M]` representing the selected
-// indices from the boxes tensor, where `M <= max_output_size`.
-func NonMaxSuppressionV2(scope *Scope, boxes tf.Output, scores tf.Output, max_output_size tf.Output, iou_threshold tf.Output) (selected_indices tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "NonMaxSuppressionV2",
- Input: []tf.Input{
- boxes, scores, max_output_size, iou_threshold,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
// Gets the next output from the given iterator .
func IteratorGetNext(scope *Scope, iterator tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (components []tf.Output) {
if scope.Err() != nil {
@@ -27976,424 +28071,64 @@ func IteratorGetNext(scope *Scope, iterator tf.Output, output_types []tf.DataTyp
return components
}
-// Produces the max pool of the input tensor for quantized types.
+// Returns the set of files matching one or more glob patterns.
+//
+// Note that this routine only supports wildcard characters in the
+// basename portion of the pattern, not in the directory portion.
+// Note also that the order of filenames returned can be non-deterministic.
//
// Arguments:
-// input: The 4D (batch x rows x cols x depth) Tensor to MaxReduce over.
-// min_input: The float value that the lowest quantized input value represents.
-// max_input: The float value that the highest quantized input value represents.
-// ksize: The size of the window for each dimension of the input tensor.
-// The length must be 4 to match the number of dimensions of the input.
-// strides: The stride of the sliding window for each dimension of the input
-// tensor. The length must be 4 to match the number of dimensions of the input.
-// padding: The type of padding algorithm to use.
+// pattern: Shell wildcard pattern(s). Scalar or vector of type string.
//
-// Returns The float value that the lowest quantized output value represents.The float value that the highest quantized output value represents.
-func QuantizedMaxPool(scope *Scope, input tf.Output, min_input tf.Output, max_input tf.Output, ksize []int64, strides []int64, padding string) (output tf.Output, min_output tf.Output, max_output tf.Output) {
+// Returns A vector of matching filenames.
+func MatchingFiles(scope *Scope, pattern tf.Output) (filenames tf.Output) {
if scope.Err() != nil {
return
}
- attrs := map[string]interface{}{"ksize": ksize, "strides": strides, "padding": padding}
opspec := tf.OpSpec{
- Type: "QuantizedMaxPool",
+ Type: "MatchingFiles",
Input: []tf.Input{
- input, min_input, max_input,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1), op.Output(2)
-}
-
-// MergeV2CheckpointsAttr is an optional argument to MergeV2Checkpoints.
-type MergeV2CheckpointsAttr func(optionalAttr)
-
-// MergeV2CheckpointsDeleteOldDirs sets the optional delete_old_dirs attribute to value.
-//
-// value: see above.
-// If not specified, defaults to true
-func MergeV2CheckpointsDeleteOldDirs(value bool) MergeV2CheckpointsAttr {
- return func(m optionalAttr) {
- m["delete_old_dirs"] = value
- }
-}
-
-// V2 format specific: merges the metadata files of sharded checkpoints. The
-//
-// result is one logical checkpoint, with one physical metadata file and renamed
-// data files.
-//
-// Intended for "grouping" multiple checkpoints in a sharded checkpoint setup.
-//
-// If delete_old_dirs is true, attempts to delete recursively the dirname of each
-// path in the input checkpoint_prefixes. This is useful when those paths are non
-// user-facing temporary locations.
-//
-// Arguments:
-// checkpoint_prefixes: prefixes of V2 checkpoints to merge.
-// destination_prefix: scalar. The desired final prefix. Allowed to be the same
-// as one of the checkpoint_prefixes.
-//
-// Returns the created operation.
-func MergeV2Checkpoints(scope *Scope, checkpoint_prefixes tf.Output, destination_prefix tf.Output, optional ...MergeV2CheckpointsAttr) (o *tf.Operation) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "MergeV2Checkpoints",
- Input: []tf.Input{
- checkpoint_prefixes, destination_prefix,
- },
- Attrs: attrs,
- }
- return scope.AddOperation(opspec)
-}
-
-// PaddingFIFOQueueV2Attr is an optional argument to PaddingFIFOQueueV2.
-type PaddingFIFOQueueV2Attr func(optionalAttr)
-
-// PaddingFIFOQueueV2Shapes sets the optional shapes attribute to value.
-//
-// value: The shape of each component in a value. The length of this attr must
-// be either 0 or the same as the length of component_types.
-// Shapes of fixed rank but variable size are allowed by setting
-// any shape dimension to -1. In this case, the inputs' shape may vary along
-// the given dimension, and DequeueMany will pad the given dimension with
-// zeros up to the maximum shape of all elements in the given batch.
-// If the length of this attr is 0, different queue elements may have
-// different ranks and shapes, but only one element may be dequeued at a time.
-// If not specified, defaults to <>
-//
-// REQUIRES: len(value) >= 0
-func PaddingFIFOQueueV2Shapes(value []tf.Shape) PaddingFIFOQueueV2Attr {
- return func(m optionalAttr) {
- m["shapes"] = value
- }
-}
-
-// PaddingFIFOQueueV2Capacity sets the optional capacity attribute to value.
-//
-// value: The upper bound on the number of elements in this queue.
-// Negative numbers mean no limit.
-// If not specified, defaults to -1
-func PaddingFIFOQueueV2Capacity(value int64) PaddingFIFOQueueV2Attr {
- return func(m optionalAttr) {
- m["capacity"] = value
- }
-}
-
-// PaddingFIFOQueueV2Container sets the optional container attribute to value.
-//
-// value: If non-empty, this queue is placed in the given container.
-// Otherwise, a default container is used.
-// If not specified, defaults to ""
-func PaddingFIFOQueueV2Container(value string) PaddingFIFOQueueV2Attr {
- return func(m optionalAttr) {
- m["container"] = value
- }
-}
-
-// PaddingFIFOQueueV2SharedName sets the optional shared_name attribute to value.
-//
-// value: If non-empty, this queue will be shared under the given name
-// across multiple sessions.
-// If not specified, defaults to ""
-func PaddingFIFOQueueV2SharedName(value string) PaddingFIFOQueueV2Attr {
- return func(m optionalAttr) {
- m["shared_name"] = value
- }
-}
-
-// A queue that produces elements in first-in first-out order.
-//
-// Variable-size shapes are allowed by setting the corresponding shape dimensions
-// to 0 in the shape attr. In this case DequeueMany will pad up to the maximum
-// size of any given element in the minibatch. See below for details.
-//
-// Arguments:
-// component_types: The type of each component in a value.
-//
-// Returns The handle to the queue.
-func PaddingFIFOQueueV2(scope *Scope, component_types []tf.DataType, optional ...PaddingFIFOQueueV2Attr) (handle tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"component_types": component_types}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "PaddingFIFOQueueV2",
-
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Computes rectified linear gradients for a Relu operation.
-//
-// Arguments:
-// gradients: The backpropagated gradients to the corresponding Relu operation.
-// features: The features passed as input to the corresponding Relu operation, OR
-// the outputs of that operation (both work equivalently).
-//
-// Returns `gradients * (features > 0)`.
-func ReluGrad(scope *Scope, gradients tf.Output, features tf.Output) (backprops tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "ReluGrad",
- Input: []tf.Input{
- gradients, features,
+ pattern,
},
}
op := scope.AddOperation(opspec)
return op.Output(0)
}
-// MaxPoolWithArgmaxAttr is an optional argument to MaxPoolWithArgmax.
-type MaxPoolWithArgmaxAttr func(optionalAttr)
+// ResourceApplyAdaMaxAttr is an optional argument to ResourceApplyAdaMax.
+type ResourceApplyAdaMaxAttr func(optionalAttr)
-// MaxPoolWithArgmaxTargmax sets the optional Targmax attribute to value.
-// If not specified, defaults to DT_INT64
-func MaxPoolWithArgmaxTargmax(value tf.DataType) MaxPoolWithArgmaxAttr {
- return func(m optionalAttr) {
- m["Targmax"] = value
- }
-}
-
-// MaxPoolWithArgmaxIncludeBatchInIndex sets the optional include_batch_in_index attribute to value.
+// ResourceApplyAdaMaxUseLocking sets the optional use_locking attribute to value.
//
-// value: Whether to include batch dimension in flattened index of `argmax`.
-// If not specified, defaults to false
-func MaxPoolWithArgmaxIncludeBatchInIndex(value bool) MaxPoolWithArgmaxAttr {
- return func(m optionalAttr) {
- m["include_batch_in_index"] = value
- }
-}
-
-// Performs max pooling on the input and outputs both max values and indices.
-//
-// The indices in `argmax` are flattened, so that a maximum value at position
-// `[b, y, x, c]` becomes flattened index:
-// `(y * width + x) * channels + c` if `include_batch_in_index` is False;
-// `((b * height + y) * width + x) * channels + c` if `include_batch_in_index` is True.
-//
-// The indices returned are always in `[0, height) x [0, width)` before flattening,
-// even if padding is involved and the mathematically correct answer is outside
-// (either negative or too large). This is a bug, but fixing it is difficult to do
-// in a safe backwards compatible way, especially due to flattening.
-//
-// Arguments:
-// input: 4-D with shape `[batch, height, width, channels]`. Input to pool over.
-// ksize: The size of the window for each dimension of the input tensor.
-// strides: The stride of the sliding window for each dimension of the
-// input tensor.
-// padding: The type of padding algorithm to use.
-//
-// Returns The max pooled output tensor.4-D. The flattened indices of the max values chosen for each output.
-func MaxPoolWithArgmax(scope *Scope, input tf.Output, ksize []int64, strides []int64, padding string, optional ...MaxPoolWithArgmaxAttr) (output tf.Output, argmax tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"ksize": ksize, "strides": strides, "padding": padding}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "MaxPoolWithArgmax",
- Input: []tf.Input{
- input,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1)
-}
-
-// MaxPool3DGradAttr is an optional argument to MaxPool3DGrad.
-type MaxPool3DGradAttr func(optionalAttr)
-
-// MaxPool3DGradDataFormat sets the optional data_format attribute to value.
-//
-// value: The data format of the input and output data. With the
-// default format "NDHWC", the data is stored in the order of:
-// [batch, in_depth, in_height, in_width, in_channels].
-// Alternatively, the format could be "NCDHW", the data storage order is:
-// [batch, in_channels, in_depth, in_height, in_width].
-// If not specified, defaults to "NDHWC"
-func MaxPool3DGradDataFormat(value string) MaxPool3DGradAttr {
- return func(m optionalAttr) {
- m["data_format"] = value
- }
-}
-
-// Computes gradients of max pooling function.
-//
-// Arguments:
-// orig_input: The original input tensor.
-// orig_output: The original output tensor.
-// grad: Output backprop of shape `[batch, depth, rows, cols, channels]`.
-// ksize: 1-D tensor of length 5. The size of the window for each dimension of
-// the input tensor. Must have `ksize[0] = ksize[4] = 1`.
-// strides: 1-D tensor of length 5. The stride of the sliding window for each
-// dimension of `input`. Must have `strides[0] = strides[4] = 1`.
-// padding: The type of padding algorithm to use.
-func MaxPool3DGrad(scope *Scope, orig_input tf.Output, orig_output tf.Output, grad tf.Output, ksize []int64, strides []int64, padding string, optional ...MaxPool3DGradAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"ksize": ksize, "strides": strides, "padding": padding}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "MaxPool3DGrad",
- Input: []tf.Input{
- orig_input, orig_output, grad,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// VarHandleOpAttr is an optional argument to VarHandleOp.
-type VarHandleOpAttr func(optionalAttr)
-
-// VarHandleOpContainer sets the optional container attribute to value.
-//
-// value: the container this variable is placed in.
-// If not specified, defaults to ""
-func VarHandleOpContainer(value string) VarHandleOpAttr {
- return func(m optionalAttr) {
- m["container"] = value
- }
-}
-
-// VarHandleOpSharedName sets the optional shared_name attribute to value.
-//
-// value: the name by which this variable is referred to.
-// If not specified, defaults to ""
-func VarHandleOpSharedName(value string) VarHandleOpAttr {
- return func(m optionalAttr) {
- m["shared_name"] = value
- }
-}
-
-// Creates a handle to a Variable resource.
-//
-// Arguments:
-// dtype: the type of this variable. Must agree with the dtypes
-// of all ops using this variable.
-// shape: The (possibly partially specified) shape of this variable.
-func VarHandleOp(scope *Scope, dtype tf.DataType, shape tf.Shape, optional ...VarHandleOpAttr) (resource tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"dtype": dtype, "shape": shape}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "VarHandleOp",
-
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Decode web-safe base64-encoded strings.
-//
-// Input may or may not have padding at the end. See EncodeBase64 for padding.
-// Web-safe means that input must use - and _ instead of + and /.
-//
-// Arguments:
-// input: Base64 strings to decode.
-//
-// Returns Decoded strings.
-func DecodeBase64(scope *Scope, input tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "DecodeBase64",
- Input: []tf.Input{
- input,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Computes sin of x element-wise.
-func Sin(scope *Scope, x tf.Output) (y tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "Sin",
- Input: []tf.Input{
- x,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// ResourceSparseApplyKerasMomentumAttr is an optional argument to ResourceSparseApplyKerasMomentum.
-type ResourceSparseApplyKerasMomentumAttr func(optionalAttr)
-
-// ResourceSparseApplyKerasMomentumUseLocking sets the optional use_locking attribute to value.
-//
-// value: If `True`, updating of the var and accum tensors will be protected
+// value: If `True`, updating of the var, m, and v tensors will be protected
// by a lock; otherwise the behavior is undefined, but may exhibit less
// contention.
// If not specified, defaults to false
-func ResourceSparseApplyKerasMomentumUseLocking(value bool) ResourceSparseApplyKerasMomentumAttr {
+func ResourceApplyAdaMaxUseLocking(value bool) ResourceApplyAdaMaxAttr {
return func(m optionalAttr) {
m["use_locking"] = value
}
}
-// ResourceSparseApplyKerasMomentumUseNesterov sets the optional use_nesterov attribute to value.
+// Update '*var' according to the AdaMax algorithm.
//
-// value: If `True`, the tensor passed to compute grad will be
-// var + momentum * accum, so in the end, the var you get is actually
-// var + momentum * accum.
-// If not specified, defaults to false
-func ResourceSparseApplyKerasMomentumUseNesterov(value bool) ResourceSparseApplyKerasMomentumAttr {
- return func(m optionalAttr) {
- m["use_nesterov"] = value
- }
-}
-
-// Update relevant entries in '*var' and '*accum' according to the momentum scheme.
-//
-// Set use_nesterov = True if you want to use Nesterov momentum.
-//
-// That is for rows we have grad for, we update var and accum as follows:
-//
-// accum = accum * momentum - lr * grad
-// var += accum
+// m_t <- beta1 * m_{t-1} + (1 - beta1) * g
+// v_t <- max(beta2 * v_{t-1}, abs(g))
+// variable <- variable - learning_rate / (1 - beta1^t) * m_t / (v_t + epsilon)
//
// Arguments:
// var_: Should be from a Variable().
-// accum: Should be from a Variable().
-// lr: Learning rate. Must be a scalar.
+// m: Should be from a Variable().
+// v: Should be from a Variable().
+// beta1_power: Must be a scalar.
+// lr: Scaling factor. Must be a scalar.
+// beta1: Momentum factor. Must be a scalar.
+// beta2: Momentum factor. Must be a scalar.
+// epsilon: Ridge term. Must be a scalar.
// grad: The gradient.
-// indices: A vector of indices into the first dimension of var and accum.
-// momentum: Momentum. Must be a scalar.
//
// Returns the created operation.
-func ResourceSparseApplyKerasMomentum(scope *Scope, var_ tf.Output, accum tf.Output, lr tf.Output, grad tf.Output, indices tf.Output, momentum tf.Output, optional ...ResourceSparseApplyKerasMomentumAttr) (o *tf.Operation) {
+func ResourceApplyAdaMax(scope *Scope, var_ tf.Output, m tf.Output, v tf.Output, beta1_power tf.Output, lr tf.Output, beta1 tf.Output, beta2 tf.Output, epsilon tf.Output, grad tf.Output, optional ...ResourceApplyAdaMaxAttr) (o *tf.Operation) {
if scope.Err() != nil {
return
}
@@ -28402,117 +28137,34 @@ func ResourceSparseApplyKerasMomentum(scope *Scope, var_ tf.Output, accum tf.Out
a(attrs)
}
opspec := tf.OpSpec{
- Type: "ResourceSparseApplyKerasMomentum",
+ Type: "ResourceApplyAdaMax",
Input: []tf.Input{
- var_, accum, lr, grad, indices, momentum,
+ var_, m, v, beta1_power, lr, beta1, beta2, epsilon, grad,
},
Attrs: attrs,
}
return scope.AddOperation(opspec)
}
-// Inverse real-valued fast Fourier transform.
-//
-// Computes the inverse 1-dimensional discrete Fourier transform of a real-valued
-// signal over the inner-most dimension of `input`.
-//
-// The inner-most dimension of `input` is assumed to be the result of `RFFT`: the
-// `fft_length / 2 + 1` unique components of the DFT of a real-valued signal. If
-// `fft_length` is not provided, it is computed from the size of the inner-most
-// dimension of `input` (`fft_length = 2 * (inner - 1)`). If the FFT length used to
-// compute `input` is odd, it should be provided since it cannot be inferred
-// properly.
-//
-// Along the axis `IRFFT` is computed on, if `fft_length / 2 + 1` is smaller
-// than the corresponding dimension of `input`, the dimension is cropped. If it is
-// larger, the dimension is padded with zeros.
+// Increments variable pointed to by 'resource' until it reaches 'limit'.
//
// Arguments:
-// input: A complex64 tensor.
-// fft_length: An int32 tensor of shape [1]. The FFT length.
+// resource: Should be from a scalar `Variable` node.
+// limit: If incrementing ref would bring it above limit, instead generates an
+// 'OutOfRange' error.
//
-// Returns A float32 tensor of the same rank as `input`. The inner-most
-// dimension of `input` is replaced with the `fft_length` samples of its inverse
-// 1D Fourier transform.
//
-// @compatibility(numpy)
-// Equivalent to np.fft.irfft
-// @end_compatibility
-func IRFFT(scope *Scope, input tf.Output, fft_length tf.Output) (output tf.Output) {
+// Returns A copy of the input before increment. If nothing else modifies the
+// input, the values produced will all be distinct.
+func ResourceCountUpTo(scope *Scope, resource tf.Output, limit int64, T tf.DataType) (output tf.Output) {
if scope.Err() != nil {
return
}
+ attrs := map[string]interface{}{"limit": limit, "T": T}
opspec := tf.OpSpec{
- Type: "IRFFT",
+ Type: "ResourceCountUpTo",
Input: []tf.Input{
- input, fft_length,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Deserializes a serialized tree ensemble config and replaces current tree
-//
-// ensemble.
-//
-// Arguments:
-// tree_ensemble_handle: Handle to the tree ensemble.
-// stamp_token: Token to use as the new value of the resource stamp.
-// tree_ensemble_serialized: Serialized proto of the ensemble.
-//
-// Returns the created operation.
-func BoostedTreesDeserializeEnsemble(scope *Scope, tree_ensemble_handle tf.Output, stamp_token tf.Output, tree_ensemble_serialized tf.Output) (o *tf.Operation) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "BoostedTreesDeserializeEnsemble",
- Input: []tf.Input{
- tree_ensemble_handle, stamp_token, tree_ensemble_serialized,
- },
- }
- return scope.AddOperation(opspec)
-}
-
-// Creates a tree ensemble model and returns a handle to it.
-//
-// Arguments:
-// tree_ensemble_handle: Handle to the tree ensemble resource to be created.
-// stamp_token: Token to use as the initial value of the resource stamp.
-// tree_ensemble_serialized: Serialized proto of the tree ensemble.
-//
-// Returns the created operation.
-func BoostedTreesCreateEnsemble(scope *Scope, tree_ensemble_handle tf.Output, stamp_token tf.Output, tree_ensemble_serialized tf.Output) (o *tf.Operation) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "BoostedTreesCreateEnsemble",
- Input: []tf.Input{
- tree_ensemble_handle, stamp_token, tree_ensemble_serialized,
- },
- }
- return scope.AddOperation(opspec)
-}
-
-// Creates a dataset that emits the outputs of `input_dataset` `count` times.
-//
-// Arguments:
-//
-// count: A scalar representing the number of times that `input_dataset` should
-// be repeated. A value of `-1` indicates that it should be repeated infinitely.
-//
-//
-func RepeatDataset(scope *Scope, input_dataset tf.Output, count tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"output_types": output_types, "output_shapes": output_shapes}
- opspec := tf.OpSpec{
- Type: "RepeatDataset",
- Input: []tf.Input{
- input_dataset, count,
+ resource,
},
Attrs: attrs,
}
@@ -28520,298 +28172,6 @@ func RepeatDataset(scope *Scope, input_dataset tf.Output, count tf.Output, outpu
return op.Output(0)
}
-// StringJoinAttr is an optional argument to StringJoin.
-type StringJoinAttr func(optionalAttr)
-
-// StringJoinSeparator sets the optional separator attribute to value.
-//
-// value: string, an optional join separator.
-// If not specified, defaults to ""
-func StringJoinSeparator(value string) StringJoinAttr {
- return func(m optionalAttr) {
- m["separator"] = value
- }
-}
-
-// Joins the strings in the given list of string tensors into one tensor;
-//
-// with the given separator (default is an empty separator).
-//
-// Arguments:
-// inputs: A list of string tensors. The tensors must all have the same shape,
-// or be scalars. Scalars may be mixed in; these will be broadcast to the shape
-// of non-scalar inputs.
-func StringJoin(scope *Scope, inputs []tf.Output, optional ...StringJoinAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "StringJoin",
- Input: []tf.Input{
- tf.OutputList(inputs),
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// A container for an iterator resource.
-//
-// Returns A handle to the iterator that can be passed to a "MakeIterator"
-// or "IteratorGetNext" op.
-func Iterator(scope *Scope, shared_name string, container string, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"shared_name": shared_name, "container": container, "output_types": output_types, "output_shapes": output_shapes}
- opspec := tf.OpSpec{
- Type: "Iterator",
-
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Real-valued fast Fourier transform.
-//
-// Computes the 1-dimensional discrete Fourier transform of a real-valued signal
-// over the inner-most dimension of `input`.
-//
-// Since the DFT of a real signal is Hermitian-symmetric, `RFFT` only returns the
-// `fft_length / 2 + 1` unique components of the FFT: the zero-frequency term,
-// followed by the `fft_length / 2` positive-frequency terms.
-//
-// Along the axis `RFFT` is computed on, if `fft_length` is smaller than the
-// corresponding dimension of `input`, the dimension is cropped. If it is larger,
-// the dimension is padded with zeros.
-//
-// Arguments:
-// input: A float32 tensor.
-// fft_length: An int32 tensor of shape [1]. The FFT length.
-//
-// Returns A complex64 tensor of the same rank as `input`. The inner-most
-// dimension of `input` is replaced with the `fft_length / 2 + 1` unique
-// frequency components of its 1D Fourier transform.
-//
-// @compatibility(numpy)
-// Equivalent to np.fft.rfft
-// @end_compatibility
-func RFFT(scope *Scope, input tf.Output, fft_length tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "RFFT",
- Input: []tf.Input{
- input, fft_length,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// UnicodeEncodeAttr is an optional argument to UnicodeEncode.
-type UnicodeEncodeAttr func(optionalAttr)
-
-// UnicodeEncodeErrors sets the optional errors attribute to value.
-//
-// value: Error handling policy when there is invalid formatting found in the input.
-// The value of 'strict' will cause the operation to produce a InvalidArgument
-// error on any invalid input formatting. A value of 'replace' (the default) will
-// cause the operation to replace any invalid formatting in the input with the
-// `replacement_char` codepoint. A value of 'ignore' will cause the operation to
-// skip any invalid formatting in the input and produce no corresponding output
-// character.
-// If not specified, defaults to "replace"
-func UnicodeEncodeErrors(value string) UnicodeEncodeAttr {
- return func(m optionalAttr) {
- m["errors"] = value
- }
-}
-
-// UnicodeEncodeReplacementChar sets the optional replacement_char attribute to value.
-//
-// value: The replacement character codepoint to be used in place of any invalid
-// formatting in the input when `errors='replace'`. Any valid unicode codepoint may
-// be used. The default value is the default unicode replacement character is
-// 0xFFFD (U+65533).
-// If not specified, defaults to 65533
-func UnicodeEncodeReplacementChar(value int64) UnicodeEncodeAttr {
- return func(m optionalAttr) {
- m["replacement_char"] = value
- }
-}
-
-// Encode a tensor of ints into unicode strings.
-//
-// Returns a vector of strings, where `output[i]` is constructed by encoding the
-// Unicode codepoints in `input_values[input_splits[i]:input_splits[i+1]]`
-// using `output_encoding`.
-//
-// ---
-//
-// Example:
-//
-// ```
-// input_values = [72, 101, 108, 108, 111, 87, 111, 114, 108, 100]
-// input_splits = [0, 5, 10]
-// output_encoding = 'UTF-8'
-//
-// output = ['Hello', 'World']
-// ```
-//
-// Arguments:
-// input_values: A 1D tensor containing the unicode codepoints that should be encoded.
-// input_splits: A 1D tensor specifying how the unicode codepoints should be split into strings.
-// In particular, `output[i]` is constructed by encoding the codepoints in the
-// slice `input_values[input_splits[i]:input_splits[i+1]]`.
-// output_encoding: Unicode encoding of the output strings. Valid encodings are: `"UTF-8",
-// "UTF-16-BE", and "UTF-32-BE"`.
-//
-// Returns The 1-D Tensor of strings encoded from the provided unicode codepoints.
-func UnicodeEncode(scope *Scope, input_values tf.Output, input_splits tf.Output, output_encoding string, optional ...UnicodeEncodeAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"output_encoding": output_encoding}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "UnicodeEncode",
- Input: []tf.Input{
- input_values, input_splits,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// ArgMaxAttr is an optional argument to ArgMax.
-type ArgMaxAttr func(optionalAttr)
-
-// ArgMaxOutputType sets the optional output_type attribute to value.
-// If not specified, defaults to DT_INT64
-func ArgMaxOutputType(value tf.DataType) ArgMaxAttr {
- return func(m optionalAttr) {
- m["output_type"] = value
- }
-}
-
-// Returns the index with the largest value across dimensions of a tensor.
-//
-// Note that in case of ties the identity of the return value is not guaranteed.
-//
-// Usage:
-// ```python
-// import tensorflow as tf
-// a = [1, 10, 26.9, 2.8, 166.32, 62.3]
-// b = tf.math.argmax(input = a)
-// c = tf.keras.backend.eval(b)
-// # c = 4
-// # here a[4] = 166.32 which is the largest element of a across axis 0
-// ```
-//
-// Arguments:
-//
-// dimension: int32 or int64, must be in the range `[-rank(input), rank(input))`.
-// Describes which dimension of the input Tensor to reduce across. For vectors,
-// use dimension = 0.
-func ArgMax(scope *Scope, input tf.Output, dimension tf.Output, optional ...ArgMaxAttr) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "ArgMax",
- Input: []tf.Input{
- input, dimension,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Adds sparse updates to the variable referenced by `resource`.
-//
-// This operation computes
-//
-// # Scalar indices
-// ref[indices, ...] += updates[...]
-//
-// # Vector indices (for each i)
-// ref[indices[i], ...] += updates[i, ...]
-//
-// # High rank indices (for each i, ..., j)
-// ref[indices[i, ..., j], ...] += updates[i, ..., j, ...]
-//
-// Duplicate entries are handled correctly: if multiple `indices` reference
-// the same location, their contributions add.
-//
-// Requires `updates.shape = indices.shape + ref.shape[1:]` or `updates.shape = []`.
-//
-//
-//
-//
-//
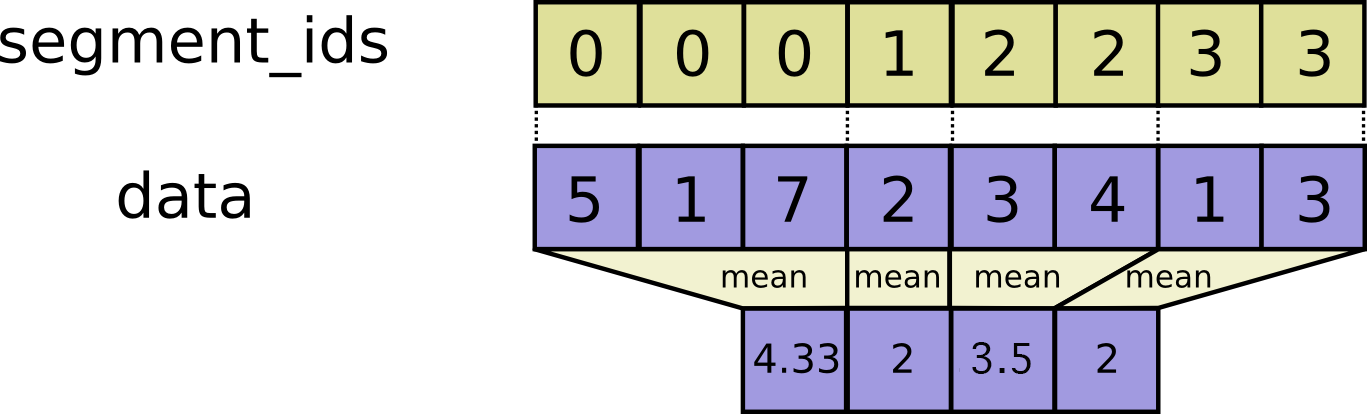
-//
-//
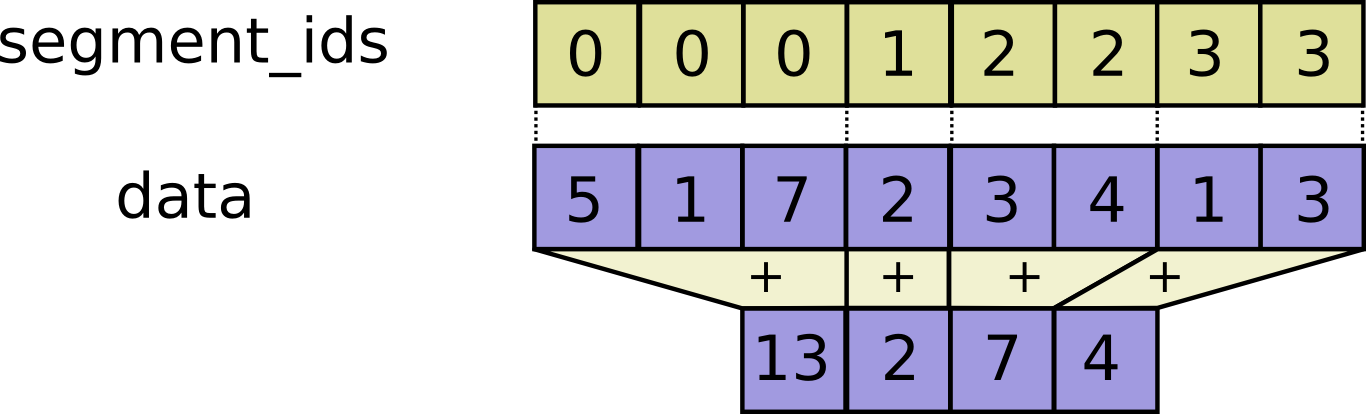
+//
//
-//
-//
+//
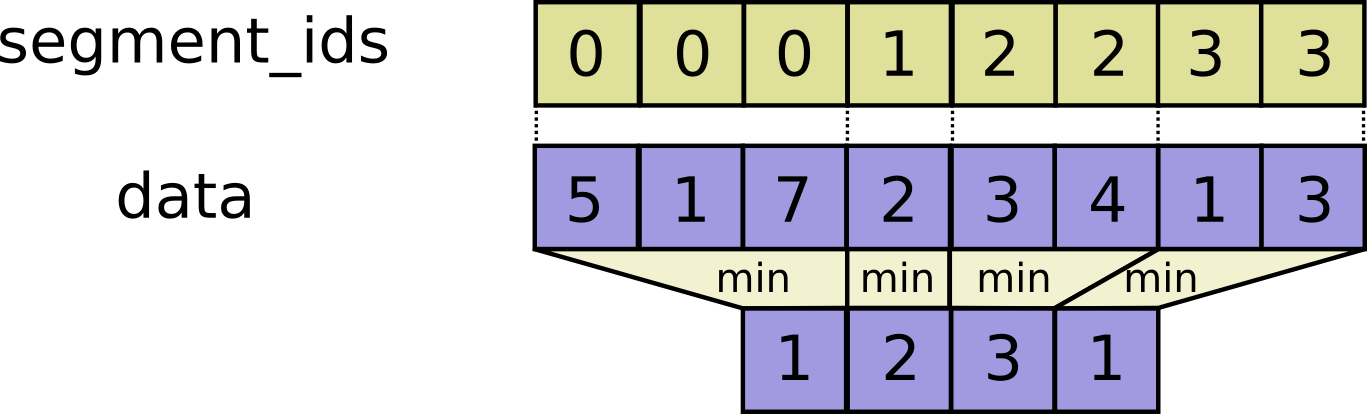
+//
+//
+//
-//
-//
-// Shai Shalev-Shwartz, Tong Zhang. 2012
-//
-// $$Loss Objective = \sum f_{i} (wx_{i}) + (l2 / 2) * |w|^2 + l1 * |w|$$
-//
-// [Adding vs. Averaging in Distributed Primal-Dual Optimization](http://arxiv.org/abs/1502.03508).
-// Chenxin Ma, Virginia Smith, Martin Jaggi, Michael I. Jordan,
-// Peter Richtarik, Martin Takac. 2015
-//
-// [Stochastic Dual Coordinate Ascent with Adaptive Probabilities](https://arxiv.org/abs/1502.08053).
-// Dominik Csiba, Zheng Qu, Peter Richtarik. 2015
-//
-// Arguments:
-// sparse_example_indices: a list of vectors which contain example indices.
-// sparse_feature_indices: a list of vectors which contain feature indices.
-// sparse_feature_values: a list of vectors which contains feature value
-// associated with each feature group.
-// dense_features: a list of matrices which contains the dense feature values.
-// example_weights: a vector which contains the weight associated with each
-// example.
-// example_labels: a vector which contains the label/target associated with each
-// example.
-// sparse_indices: a list of vectors where each value is the indices which has
-// corresponding weights in sparse_weights. This field maybe omitted for the
-// dense approach.
-// sparse_weights: a list of vectors where each value is the weight associated with
-// a sparse feature group.
-// dense_weights: a list of vectors where the values are the weights associated
-// with a dense feature group.
-// example_state_data: a list of vectors containing the example state data.
-// loss_type: Type of the primal loss. Currently SdcaSolver supports logistic,
-// squared and hinge losses.
-// l1: Symmetric l1 regularization strength.
-// l2: Symmetric l2 regularization strength.
-// num_loss_partitions: Number of partitions of the global loss function.
-// num_inner_iterations: Number of iterations per mini-batch.
-//
-// Returns a list of vectors containing the updated example state
-// data.a list of vectors where each value is the delta
-// weights associated with a sparse feature group.a list of vectors where the values are the delta
-// weights associated with a dense feature group.
-func SdcaOptimizer(scope *Scope, sparse_example_indices []tf.Output, sparse_feature_indices []tf.Output, sparse_feature_values []tf.Output, dense_features []tf.Output, example_weights tf.Output, example_labels tf.Output, sparse_indices []tf.Output, sparse_weights []tf.Output, dense_weights []tf.Output, example_state_data tf.Output, loss_type string, l1 float32, l2 float32, num_loss_partitions int64, num_inner_iterations int64, optional ...SdcaOptimizerAttr) (out_example_state_data tf.Output, out_delta_sparse_weights []tf.Output, out_delta_dense_weights []tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"loss_type": loss_type, "l1": l1, "l2": l2, "num_loss_partitions": num_loss_partitions, "num_inner_iterations": num_inner_iterations}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "SdcaOptimizer",
- Input: []tf.Input{
- tf.OutputList(sparse_example_indices), tf.OutputList(sparse_feature_indices), tf.OutputList(sparse_feature_values), tf.OutputList(dense_features), example_weights, example_labels, tf.OutputList(sparse_indices), tf.OutputList(sparse_weights), tf.OutputList(dense_weights), example_state_data,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- if scope.Err() != nil {
- return
- }
- var idx int
- var err error
- out_example_state_data = op.Output(idx)
- if out_delta_sparse_weights, idx, err = makeOutputList(op, idx, "out_delta_sparse_weights"); err != nil {
- scope.UpdateErr("SdcaOptimizer", err)
- return
- }
- if out_delta_dense_weights, idx, err = makeOutputList(op, idx, "out_delta_dense_weights"); err != nil {
- scope.UpdateErr("SdcaOptimizer", err)
- return
- }
- return out_example_state_data, out_delta_sparse_weights, out_delta_dense_weights
-}
-
-// Saves the input tensors to disk.
-//
-// The size of `tensor_names` must match the number of tensors in `data`. `data[i]`
-// is written to `filename` with name `tensor_names[i]`.
-//
-// See also `SaveSlices`.
-//
-// Arguments:
-// filename: Must have a single element. The name of the file to which we write
-// the tensor.
-// tensor_names: Shape `[N]`. The names of the tensors to be saved.
-// data: `N` tensors to save.
+// filename: scalar. The name of the file to which we write the contents.
+// contents: scalar. The content to be written to the output file.
//
// Returns the created operation.
-func Save(scope *Scope, filename tf.Output, tensor_names tf.Output, data []tf.Output) (o *tf.Operation) {
+func WriteFile(scope *Scope, filename tf.Output, contents tf.Output) (o *tf.Operation) {
if scope.Err() != nil {
return
}
opspec := tf.OpSpec{
- Type: "Save",
+ Type: "WriteFile",
Input: []tf.Input{
- filename, tensor_names, tf.OutputList(data),
+ filename, contents,
},
}
return scope.AddOperation(opspec)
}
-// Computes gradients for SparseSegmentSqrtN.
-//
-// Returns tensor "output" with same shape as grad, except for dimension 0 whose
-// value is output_dim0.
-//
-// Arguments:
-// grad: gradient propagated to the SparseSegmentSqrtN op.
-// indices: indices passed to the corresponding SparseSegmentSqrtN op.
-// segment_ids: segment_ids passed to the corresponding SparseSegmentSqrtN op.
-// output_dim0: dimension 0 of "data" passed to SparseSegmentSqrtN op.
-func SparseSegmentSqrtNGrad(scope *Scope, grad tf.Output, indices tf.Output, segment_ids tf.Output, output_dim0 tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "SparseSegmentSqrtNGrad",
- Input: []tf.Input{
- grad, indices, segment_ids, output_dim0,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
+// RealAttr is an optional argument to Real.
+type RealAttr func(optionalAttr)
-// Generate a sharded filename. The filename is printf formatted as
-//
-// %s-%05d-of-%05d, basename, shard, num_shards.
-func ShardedFilename(scope *Scope, basename tf.Output, shard tf.Output, num_shards tf.Output) (filename tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "ShardedFilename",
- Input: []tf.Input{
- basename, shard, num_shards,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// MapUnstageAttr is an optional argument to MapUnstage.
-type MapUnstageAttr func(optionalAttr)
-
-// MapUnstageCapacity sets the optional capacity attribute to value.
-// If not specified, defaults to 0
-//
-// REQUIRES: value >= 0
-func MapUnstageCapacity(value int64) MapUnstageAttr {
+// RealTout sets the optional Tout attribute to value.
+// If not specified, defaults to DT_FLOAT
+func RealTout(value tf.DataType) RealAttr {
return func(m optionalAttr) {
- m["capacity"] = value
+ m["Tout"] = value
}
}
-// MapUnstageMemoryLimit sets the optional memory_limit attribute to value.
-// If not specified, defaults to 0
+// Returns the real part of a complex number.
//
-// REQUIRES: value >= 0
-func MapUnstageMemoryLimit(value int64) MapUnstageAttr {
- return func(m optionalAttr) {
- m["memory_limit"] = value
- }
-}
-
-// MapUnstageContainer sets the optional container attribute to value.
-// If not specified, defaults to ""
-func MapUnstageContainer(value string) MapUnstageAttr {
- return func(m optionalAttr) {
- m["container"] = value
- }
-}
-
-// MapUnstageSharedName sets the optional shared_name attribute to value.
-// If not specified, defaults to ""
-func MapUnstageSharedName(value string) MapUnstageAttr {
- return func(m optionalAttr) {
- m["shared_name"] = value
- }
-}
-
-// Op removes and returns the values associated with the key
-//
-// from the underlying container. If the underlying container
-// does not contain this key, the op will block until it does.
-func MapUnstage(scope *Scope, key tf.Output, indices tf.Output, dtypes []tf.DataType, optional ...MapUnstageAttr) (values []tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"dtypes": dtypes}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "MapUnstage",
- Input: []tf.Input{
- key, indices,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- if scope.Err() != nil {
- return
- }
- var idx int
- var err error
- if values, idx, err = makeOutputList(op, idx, "values"); err != nil {
- scope.UpdateErr("MapUnstage", err)
- return
- }
- return values
-}
-
-// Creates a dataset that contains the unique elements of `input_dataset`.
-func ExperimentalUniqueDataset(scope *Scope, input_dataset tf.Output, output_types []tf.DataType, output_shapes []tf.Shape) (handle tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{"output_types": output_types, "output_shapes": output_shapes}
- opspec := tf.OpSpec{
- Type: "ExperimentalUniqueDataset",
- Input: []tf.Input{
- input_dataset,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// TFRecordReaderV2Attr is an optional argument to TFRecordReaderV2.
-type TFRecordReaderV2Attr func(optionalAttr)
-
-// TFRecordReaderV2Container sets the optional container attribute to value.
-//
-// value: If non-empty, this reader is placed in the given container.
-// Otherwise, a default container is used.
-// If not specified, defaults to ""
-func TFRecordReaderV2Container(value string) TFRecordReaderV2Attr {
- return func(m optionalAttr) {
- m["container"] = value
- }
-}
-
-// TFRecordReaderV2SharedName sets the optional shared_name attribute to value.
-//
-// value: If non-empty, this reader is named in the given bucket
-// with this shared_name. Otherwise, the node name is used instead.
-// If not specified, defaults to ""
-func TFRecordReaderV2SharedName(value string) TFRecordReaderV2Attr {
- return func(m optionalAttr) {
- m["shared_name"] = value
- }
-}
-
-// TFRecordReaderV2CompressionType sets the optional compression_type attribute to value.
-// If not specified, defaults to ""
-func TFRecordReaderV2CompressionType(value string) TFRecordReaderV2Attr {
- return func(m optionalAttr) {
- m["compression_type"] = value
- }
-}
-
-// A Reader that outputs the records from a TensorFlow Records file.
-//
-// Returns The handle to reference the Reader.
-func TFRecordReaderV2(scope *Scope, optional ...TFRecordReaderV2Attr) (reader_handle tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "TFRecordReaderV2",
-
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Returns up to `num_records` (key, value) pairs produced by a Reader.
-//
-// Will dequeue from the input queue if necessary (e.g. when the
-// Reader needs to start reading from a new file since it has finished
-// with the previous file).
-// It may return less than `num_records` even before the last batch.
-//
-// Arguments:
-// reader_handle: Handle to a `Reader`.
-// queue_handle: Handle to a `Queue`, with string work items.
-// num_records: number of records to read from `Reader`.
-//
-// Returns A 1-D tensor.A 1-D tensor.
-func ReaderReadUpToV2(scope *Scope, reader_handle tf.Output, queue_handle tf.Output, num_records tf.Output) (keys tf.Output, values tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "ReaderReadUpToV2",
- Input: []tf.Input{
- reader_handle, queue_handle, num_records,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0), op.Output(1)
-}
-
-// Inverse fast Fourier transform.
-//
-// Computes the inverse 1-dimensional discrete Fourier transform over the
-// inner-most dimension of `input`.
-//
-// Arguments:
-// input: A complex tensor.
-//
-// Returns A complex tensor of the same shape as `input`. The inner-most
-// dimension of `input` is replaced with its inverse 1D Fourier transform.
-//
-// @compatibility(numpy)
-// Equivalent to np.fft.ifft
-// @end_compatibility
-func IFFT(scope *Scope, input tf.Output) (output tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "IFFT",
- Input: []tf.Input{
- input,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// TensorSummaryAttr is an optional argument to TensorSummary.
-type TensorSummaryAttr func(optionalAttr)
-
-// TensorSummaryDescription sets the optional description attribute to value.
-//
-// value: A json-encoded SummaryDescription proto.
-// If not specified, defaults to ""
-func TensorSummaryDescription(value string) TensorSummaryAttr {
- return func(m optionalAttr) {
- m["description"] = value
- }
-}
-
-// TensorSummaryLabels sets the optional labels attribute to value.
-//
-// value: An unused list of strings.
-// If not specified, defaults to <>
-func TensorSummaryLabels(value []string) TensorSummaryAttr {
- return func(m optionalAttr) {
- m["labels"] = value
- }
-}
-
-// TensorSummaryDisplayName sets the optional display_name attribute to value.
-//
-// value: An unused string.
-// If not specified, defaults to ""
-func TensorSummaryDisplayName(value string) TensorSummaryAttr {
- return func(m optionalAttr) {
- m["display_name"] = value
- }
-}
-
-// Outputs a `Summary` protocol buffer with a tensor.
-//
-// This op is being phased out in favor of TensorSummaryV2, which lets callers pass
-// a tag as well as a serialized SummaryMetadata proto string that contains
-// plugin-specific data. We will keep this op to maintain backwards compatibility.
-//
-// Arguments:
-// tensor: A tensor to serialize.
-func TensorSummary(scope *Scope, tensor tf.Output, optional ...TensorSummaryAttr) (summary tf.Output) {
- if scope.Err() != nil {
- return
- }
- attrs := map[string]interface{}{}
- for _, a := range optional {
- a(attrs)
- }
- opspec := tf.OpSpec{
- Type: "TensorSummary",
- Input: []tf.Input{
- tensor,
- },
- Attrs: attrs,
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Returns the number of records this Reader has produced.
-//
-// This is the same as the number of ReaderRead executions that have
-// succeeded.
-//
-// Arguments:
-// reader_handle: Handle to a Reader.
-func ReaderNumRecordsProducedV2(scope *Scope, reader_handle tf.Output) (records_produced tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "ReaderNumRecordsProducedV2",
- Input: []tf.Input{
- reader_handle,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Splits a tensor into a list.
-//
-// list[i] corresponds to lengths[i] tensors from the input tensor.
-// The tensor must have rank at least 1 and contain exactly sum(lengths) elements.
-//
-// tensor: The input tensor.
-// element_shape: A shape compatible with that of elements in the tensor.
-// lengths: Vector of sizes of the 0th dimension of tensors in the list.
-// output_handle: The list.
-func TensorListSplit(scope *Scope, tensor tf.Output, element_shape tf.Output, lengths tf.Output) (output_handle tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "TensorListSplit",
- Input: []tf.Input{
- tensor, element_shape, lengths,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Returns the number of work units this Reader has finished processing.
-//
-// Arguments:
-// reader_handle: Handle to a Reader.
-func ReaderNumWorkUnitsCompletedV2(scope *Scope, reader_handle tf.Output) (units_completed tf.Output) {
- if scope.Err() != nil {
- return
- }
- opspec := tf.OpSpec{
- Type: "ReaderNumWorkUnitsCompletedV2",
- Input: []tf.Input{
- reader_handle,
- },
- }
- op := scope.AddOperation(opspec)
- return op.Output(0)
-}
-
-// Computes the maximum along segments of a tensor.
-//
-// Read
-// [the section on segmentation](https://tensorflow.org/api_docs/python/tf/math#Segmentation)
-// for an explanation of segments.
-//
-// Computes a tensor such that
-// \\(output_i = \max_j(data_j)\\) where `max` is over `j` such
-// that `segment_ids[j] == i`.
-//
-// If the max is empty for a given segment ID `i`, `output[i] = 0`.
-//
-//
-//
-//
-//
-//
+//
+//