diff --git a/tensorflow/core/ops/array_ops.cc b/tensorflow/core/ops/array_ops.cc
index bbdcfd337e2..e528ae47aa7 100644
--- a/tensorflow/core/ops/array_ops.cc
+++ b/tensorflow/core/ops/array_ops.cc
@@ -209,7 +209,7 @@ The input tensors are all required to have size 1 in the first dimension.
For example:
-```prettyprint
+```
# 'x' is [[1, 4]]
# 'y' is [[2, 5]]
# 'z' is [[3, 6]]
@@ -277,7 +277,7 @@ Etc.
For example:
-```prettyprint
+```
# 'x' is [1, 4]
# 'y' is [2, 5]
# 'z' is [3, 6]
@@ -432,7 +432,7 @@ Computes offsets of concat inputs within its output.
For example:
-```prettyprint
+```
# 'x' is [2, 2, 7]
# 'y' is [2, 3, 7]
# 'z' is [2, 5, 7]
@@ -670,7 +670,7 @@ rank 2k with dimensions [D1,..., Dk, D1,..., Dk] where:
For example:
-```prettyprint
+```
# 'diagonal' is [1, 2, 3, 4]
tf.diag(diagonal) ==> [[1, 0, 0, 0]
[0, 2, 0, 0]
@@ -722,7 +722,7 @@ tensor of rank `k` with dimensions `[D1,..., Dk]` where:
For example:
-```prettyprint
+```
# 'input' is [[1, 0, 0, 0]
[0, 2, 0, 0]
[0, 0, 3, 0]
@@ -768,7 +768,7 @@ tensor of rank `k+1` with dimensions [I, J, K, ..., N, N]` where:
For example:
-```prettyprint
+```
# 'diagonal' is [[1, 2, 3, 4], [5, 6, 7, 8]]
and diagonal.shape = (2, 4)
@@ -880,7 +880,7 @@ The input must be at least a matrix.
For example:
-```prettyprint
+```
# 'input' is [[[1, 0, 0, 0]
[0, 2, 0, 0]
[0, 0, 3, 0]
@@ -927,7 +927,7 @@ The indicator function
For example:
-```prettyprint
+```
# if 'input' is [[ 0, 1, 2, 3]
[-1, 0, 1, 2]
[-2, -1, 0, 1]
@@ -946,7 +946,7 @@ tf.matrix_band_part(input, 2, 1) ==> [[ 0, 1, 0, 0]
Useful special cases:
-```prettyprint
+```
tf.matrix_band_part(input, 0, -1) ==> Upper triangular part.
tf.matrix_band_part(input, -1, 0) ==> Lower triangular part.
tf.matrix_band_part(input, 0, 0) ==> Diagonal.
@@ -998,7 +998,7 @@ of `tensor` must equal the number of elements in `dims`. In other words:
For example:
-```prettyprint
+```
# tensor 't' is [[[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]],
@@ -1074,7 +1074,7 @@ once, a InvalidArgument error is raised.
For example:
-```prettyprint
+```
# tensor 't' is [[[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]],
@@ -1245,7 +1245,7 @@ This operation creates a tensor of shape `dims` and fills it with `value`.
For example:
-```prettyprint
+```
# Output tensor has shape [2, 3].
fill([2, 3], 9) ==> [[9, 9, 9]
[9, 9, 9]]
@@ -1354,7 +1354,7 @@ out-of-bound indices result in safe but unspecified behavior, which may include
raising an error.
-
+
)doc");
@@ -1610,7 +1610,7 @@ implied by `shape` must be the same as the number of elements in `tensor`.
For example:
-```prettyprint
+```
# tensor 't' is [1, 2, 3, 4, 5, 6, 7, 8, 9]
# tensor 't' has shape [9]
reshape(t, [3, 3]) ==> [[1, 2, 3],
@@ -1697,7 +1697,7 @@ The values must include 0. There can be no duplicate values or negative values.
For example:
-```prettyprint
+```
# tensor `x` is [3, 4, 0, 2, 1]
invert_permutation(x) ==> [2, 4, 3, 0, 1]
```
@@ -1802,7 +1802,7 @@ in the unique output `y`. In other words:
For example:
-```prettyprint
+```
# tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8]
y, idx = unique(x)
y ==> [1, 2, 4, 7, 8]
@@ -1842,7 +1842,7 @@ contains the count of each element of `y` in `x`. In other words:
For example:
-```prettyprint
+```
# tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8]
y, idx, count = unique_with_counts(x)
y ==> [1, 2, 4, 7, 8]
@@ -1887,7 +1887,7 @@ This operation returns a 1-D integer tensor representing the shape of `input`.
For example:
-```prettyprint
+```
# 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]]
shape(t) ==> [2, 2, 3]
```
@@ -1968,7 +1968,7 @@ slice `i`, with the first `seq_lengths[i]` slices along dimension
For example:
-```prettyprint
+```
# Given this:
batch_dim = 0
seq_dim = 1
@@ -1990,7 +1990,7 @@ output[3, 2:, :, ...] = input[3, 2:, :, ...]
In contrast, if:
-```prettyprint
+```
# Given this:
batch_dim = 2
seq_dim = 0
@@ -2031,7 +2031,7 @@ This operation returns an integer representing the rank of `input`.
For example:
-```prettyprint
+```
# 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]]
# shape of tensor 't' is [2, 2, 3]
rank(t) ==> 3
@@ -2057,7 +2057,7 @@ This operation returns an integer representing the number of elements in
For example:
-```prettyprint
+```
# 't' is [[[1, 1,, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]]]
size(t) ==> 12
```
@@ -2290,7 +2290,7 @@ encoding is best understand by considering a non-trivial example. In
particular,
`foo[1, 2:4, None, ..., :-3:-1, :]` will be encoded as
-```prettyprint
+```
begin = [1, 2, x, x, 0, x] # x denotes don't care (usually 0)
end = [2, 4, x, x, -3, x]
strides = [1, 1, x, x, -1, 1]
@@ -2512,7 +2512,7 @@ the output tensor can vary depending on how many true values there are in
For example:
-```prettyprint
+```
# 'input' tensor is [[True, False]
# [True, False]]
# 'input' has two true values, so output has two coordinates.
@@ -2616,7 +2616,7 @@ The padded size of each dimension D of the output is:
For example:
-```prettyprint
+```
# 't' is [[1, 1], [2, 2]]
# 'paddings' is [[1, 1], [2, 2]]
# rank of 't' is 2
@@ -2655,7 +2655,7 @@ The padded size of each dimension D of the output is:
For example:
-```prettyprint
+```
# 't' is [[1, 2, 3], [4, 5, 6]].
# 'paddings' is [[1, 1]], [2, 2]].
# 'mode' is SYMMETRIC.
@@ -2751,7 +2751,7 @@ The folded size of each dimension D of the output is:
For example:
-```prettyprint
+```
# 't' is [[1, 2, 3], [4, 5, 6], [7, 8, 9]].
# 'paddings' is [[0, 1]], [0, 1]].
# 'mode' is SYMMETRIC.
@@ -2927,7 +2927,7 @@ which will make the shape `[1, height, width, channels]`.
Other examples:
-```prettyprint
+```
# 't' is a tensor of shape [2]
shape(expand_dims(t, 0)) ==> [1, 2]
shape(expand_dims(t, 1)) ==> [2, 1]
@@ -3029,14 +3029,14 @@ dimensions, you can remove specific size 1 dimensions by specifying
For example:
-```prettyprint
+```
# 't' is a tensor of shape [1, 2, 1, 3, 1, 1]
shape(squeeze(t)) ==> [2, 3]
```
Or, to remove specific size 1 dimensions:
-```prettyprint
+```
# 't' is a tensor of shape [1, 2, 1, 3, 1, 1]
shape(squeeze(t, [2, 4])) ==> [1, 2, 3, 1]
```
@@ -3079,14 +3079,14 @@ position of each `out` element in `x`. In other words:
For example, given this input:
-```prettyprint
+```
x = [1, 2, 3, 4, 5, 6]
y = [1, 3, 5]
```
This operation would return:
-```prettyprint
+```
out ==> [2, 4, 6]
idx ==> [1, 3, 5]
```
@@ -3345,34 +3345,34 @@ Some examples:
(1) For the following input of shape `[1, 2, 2, 1]`, `block_shape = [2, 2]`, and
`paddings = [[0, 0], [0, 0]]`:
-```prettyprint
+```
x = [[[[1], [2]], [[3], [4]]]]
```
The output tensor has shape `[4, 1, 1, 1]` and value:
-```prettyprint
+```
[[[[1]]], [[[2]]], [[[3]]], [[[4]]]]
```
(2) For the following input of shape `[1, 2, 2, 3]`, `block_shape = [2, 2]`, and
`paddings = [[0, 0], [0, 0]]`:
-```prettyprint
+```
x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
The output tensor has shape `[4, 1, 1, 3]` and value:
-```prettyprint
+```
[[[1, 2, 3]], [[4, 5, 6]], [[7, 8, 9]], [[10, 11, 12]]]
```
(3) For the following input of shape `[1, 4, 4, 1]`, `block_shape = [2, 2]`, and
`paddings = [[0, 0], [0, 0]]`:
-```prettyprint
+```
x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]],
[[9], [10], [11], [12]],
@@ -3381,7 +3381,7 @@ x = [[[[1], [2], [3], [4]],
The output tensor has shape `[4, 2, 2, 1]` and value:
-```prettyprint
+```
x = [[[[1], [3]], [[9], [11]]],
[[[2], [4]], [[10], [12]]],
[[[5], [7]], [[13], [15]]],
@@ -3391,7 +3391,7 @@ x = [[[[1], [3]], [[9], [11]]],
(4) For the following input of shape `[2, 2, 4, 1]`, block_shape = `[2, 2]`, and
paddings = `[[0, 0], [2, 0]]`:
-```prettyprint
+```
x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]]],
[[[9], [10], [11], [12]],
@@ -3400,7 +3400,7 @@ x = [[[[1], [2], [3], [4]],
The output tensor has shape `[8, 1, 3, 1]` and value:
-```prettyprint
+```
x = [[[[0], [1], [3]]], [[[0], [9], [11]]],
[[[0], [2], [4]]], [[[0], [10], [12]]],
[[[0], [5], [7]]], [[[0], [13], [15]]],
@@ -3474,32 +3474,32 @@ Some examples:
(1) For the following input of shape `[1, 2, 2, 1]` and block_size of 2:
-```prettyprint
+```
x = [[[[1], [2]], [[3], [4]]]]
```
The output tensor has shape `[4, 1, 1, 1]` and value:
-```prettyprint
+```
[[[[1]]], [[[2]]], [[[3]]], [[[4]]]]
```
(2) For the following input of shape `[1, 2, 2, 3]` and block_size of 2:
-```prettyprint
+```
x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
The output tensor has shape `[4, 1, 1, 3]` and value:
-```prettyprint
+```
[[[1, 2, 3]], [[4, 5, 6]], [[7, 8, 9]], [[10, 11, 12]]]
```
(3) For the following input of shape `[1, 4, 4, 1]` and block_size of 2:
-```prettyprint
+```
x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]],
[[9], [10], [11], [12]],
@@ -3508,7 +3508,7 @@ x = [[[[1], [2], [3], [4]],
The output tensor has shape `[4, 2, 2, 1]` and value:
-```prettyprint
+```
x = [[[[1], [3]], [[9], [11]]],
[[[2], [4]], [[10], [12]]],
[[[5], [7]], [[13], [15]]],
@@ -3517,7 +3517,7 @@ x = [[[[1], [3]], [[9], [11]]],
(4) For the following input of shape `[2, 2, 4, 1]` and block_size of 2:
-```prettyprint
+```
x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]]],
[[[9], [10], [11], [12]],
@@ -3526,7 +3526,7 @@ x = [[[[1], [2], [3], [4]],
The output tensor has shape `[8, 1, 2, 1]` and value:
-```prettyprint
+```
x = [[[[1], [3]]], [[[9], [11]]], [[[2], [4]]], [[[10], [12]]],
[[[5], [7]]], [[[13], [15]]], [[[6], [8]]], [[[14], [16]]]]
```
@@ -3612,26 +3612,26 @@ Some examples:
(1) For the following input of shape `[4, 1, 1, 1]`, `block_shape = [2, 2]`, and
`crops = [[0, 0], [0, 0]]`:
-```prettyprint
+```
[[[[1]]], [[[2]]], [[[3]]], [[[4]]]]
```
The output tensor has shape `[1, 2, 2, 1]` and value:
-```prettyprint
+```
x = [[[[1], [2]], [[3], [4]]]]
```
(2) For the following input of shape `[4, 1, 1, 3]`, `block_shape = [2, 2]`, and
`crops = [[0, 0], [0, 0]]`:
-```prettyprint
+```
[[[1, 2, 3]], [[4, 5, 6]], [[7, 8, 9]], [[10, 11, 12]]]
```
The output tensor has shape `[1, 2, 2, 3]` and value:
-```prettyprint
+```
x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
@@ -3639,7 +3639,7 @@ x = [[[[1, 2, 3], [4, 5, 6]],
(3) For the following input of shape `[4, 2, 2, 1]`, `block_shape = [2, 2]`, and
`crops = [[0, 0], [0, 0]]`:
-```prettyprint
+```
x = [[[[1], [3]], [[9], [11]]],
[[[2], [4]], [[10], [12]]],
[[[5], [7]], [[13], [15]]],
@@ -3648,7 +3648,7 @@ x = [[[[1], [3]], [[9], [11]]],
The output tensor has shape `[1, 4, 4, 1]` and value:
-```prettyprint
+```
x = [[[1], [2], [3], [4]],
[[5], [6], [7], [8]],
[[9], [10], [11], [12]],
@@ -3658,7 +3658,7 @@ x = [[[1], [2], [3], [4]],
(4) For the following input of shape `[8, 1, 3, 1]`, `block_shape = [2, 2]`, and
`crops = [[0, 0], [2, 0]]`:
-```prettyprint
+```
x = [[[[0], [1], [3]]], [[[0], [9], [11]]],
[[[0], [2], [4]]], [[[0], [10], [12]]],
[[[0], [5], [7]]], [[[0], [13], [15]]],
@@ -3667,7 +3667,7 @@ x = [[[[0], [1], [3]]], [[[0], [9], [11]]],
The output tensor has shape `[2, 2, 4, 1]` and value:
-```prettyprint
+```
x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]]],
[[[9], [10], [11], [12]],
@@ -3732,32 +3732,32 @@ Some examples:
(1) For the following input of shape `[4, 1, 1, 1]` and block_size of 2:
-```prettyprint
+```
[[[[1]]], [[[2]]], [[[3]]], [[[4]]]]
```
The output tensor has shape `[1, 2, 2, 1]` and value:
-```prettyprint
+```
x = [[[[1], [2]], [[3], [4]]]]
```
(2) For the following input of shape `[4, 1, 1, 3]` and block_size of 2:
-```prettyprint
+```
[[[1, 2, 3]], [[4, 5, 6]], [[7, 8, 9]], [[10, 11, 12]]]
```
The output tensor has shape `[1, 2, 2, 3]` and value:
-```prettyprint
+```
x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
(3) For the following input of shape `[4, 2, 2, 1]` and block_size of 2:
-```prettyprint
+```
x = [[[[1], [3]], [[9], [11]]],
[[[2], [4]], [[10], [12]]],
[[[5], [7]], [[13], [15]]],
@@ -3766,7 +3766,7 @@ x = [[[[1], [3]], [[9], [11]]],
The output tensor has shape `[1, 4, 4, 1]` and value:
-```prettyprint
+```
x = [[[1], [2], [3], [4]],
[[5], [6], [7], [8]],
[[9], [10], [11], [12]],
@@ -3775,14 +3775,14 @@ x = [[[1], [2], [3], [4]],
(4) For the following input of shape `[8, 1, 2, 1]` and block_size of 2:
-```prettyprint
+```
x = [[[[1], [3]]], [[[9], [11]]], [[[2], [4]]], [[[10], [12]]],
[[[5], [7]]], [[[13], [15]]], [[[6], [8]]], [[[14], [16]]]]
```
The output tensor has shape `[2, 2, 4, 1]` and value:
-```prettyprint
+```
x = [[[[1], [3]], [[5], [7]]],
[[[2], [4]], [[10], [12]]],
[[[5], [7]], [[13], [15]]],
@@ -3848,14 +3848,14 @@ purely convolutional models.
For example, given this input of shape `[1, 2, 2, 1]`, and block_size of 2:
-```prettyprint
+```
x = [[[[1], [2]],
[[3], [4]]]]
```
This operation will output a tensor of shape `[1, 1, 1, 4]`:
-```prettyprint
+```
[[[[1, 2, 3, 4]]]]
```
@@ -3866,7 +3866,7 @@ The output element shape is `[1, 1, 4]`.
For an input tensor with larger depth, here of shape `[1, 2, 2, 3]`, e.g.
-```prettyprint
+```
x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
@@ -3874,13 +3874,13 @@ x = [[[[1, 2, 3], [4, 5, 6]],
This operation, for block_size of 2, will return the following tensor of shape
`[1, 1, 1, 12]`
-```prettyprint
+```
[[[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]]]]
```
Similarly, for the following input of shape `[1 4 4 1]`, and a block size of 2:
-```prettyprint
+```
x = [[[[1], [2], [5], [6]],
[[3], [4], [7], [8]],
[[9], [10], [13], [14]],
@@ -3889,7 +3889,7 @@ x = [[[[1], [2], [5], [6]],
the operator will return the following tensor of shape `[1 2 2 4]`:
-```prettyprint
+```
x = [[[[1, 2, 3, 4],
[5, 6, 7, 8]],
[[9, 10, 11, 12],
@@ -3958,14 +3958,14 @@ purely convolutional models.
For example, given this input of shape `[1, 1, 1, 4]`, and a block size of 2:
-```prettyprint
+```
x = [[[[1, 2, 3, 4]]]]
```
This operation will output a tensor of shape `[1, 2, 2, 1]`:
-```prettyprint
+```
[[[[1], [2]],
[[3], [4]]]]
```
@@ -3977,14 +3977,14 @@ The output element shape is `[2, 2, 1]`.
For an input tensor with larger depth, here of shape `[1, 1, 1, 12]`, e.g.
-```prettyprint
+```
x = [[[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]]]]
```
This operation, for block size of 2, will return the following tensor of shape
`[1, 2, 2, 3]`
-```prettyprint
+```
[[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
@@ -3992,7 +3992,7 @@ This operation, for block size of 2, will return the following tensor of shape
Similarly, for the following input of shape `[1 2 2 4]`, and a block size of 2:
-```prettyprint
+```
x = [[[[1, 2, 3, 4],
[5, 6, 7, 8]],
[[9, 10, 11, 12],
@@ -4001,7 +4001,7 @@ x = [[[[1, 2, 3, 4],
the operator will return the following tensor of shape `[1 4 4 1]`:
-```prettyprint
+```
x = [[ [1], [2], [5], [6]],
[ [3], [4], [7], [8]],
[ [9], [10], [13], [14]],
@@ -4775,7 +4775,7 @@ index. For example, say we want to insert 4 scattered elements in a rank-1
tensor with 8 elements.
-
+
In Python, this scatter operation would look like this:
@@ -4798,7 +4798,7 @@ example, if we wanted to insert two slices in the first dimension of a
rank-3 tensor with two matrices of new values.
-
+
In Python, this scatter operation would look like this:
diff --git a/tensorflow/core/ops/data_flow_ops.cc b/tensorflow/core/ops/data_flow_ops.cc
index 8b9c92859d7..b34dd4ae90b 100644
--- a/tensorflow/core/ops/data_flow_ops.cc
+++ b/tensorflow/core/ops/data_flow_ops.cc
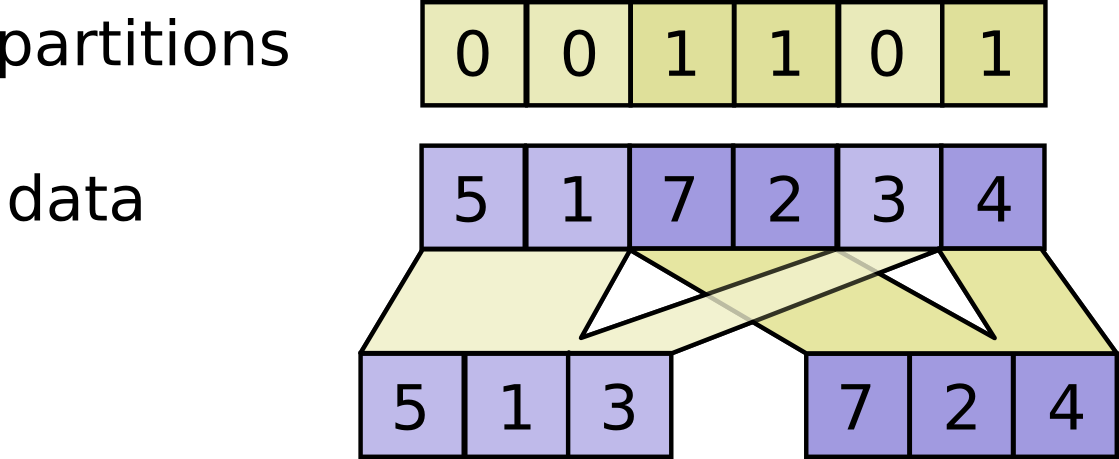
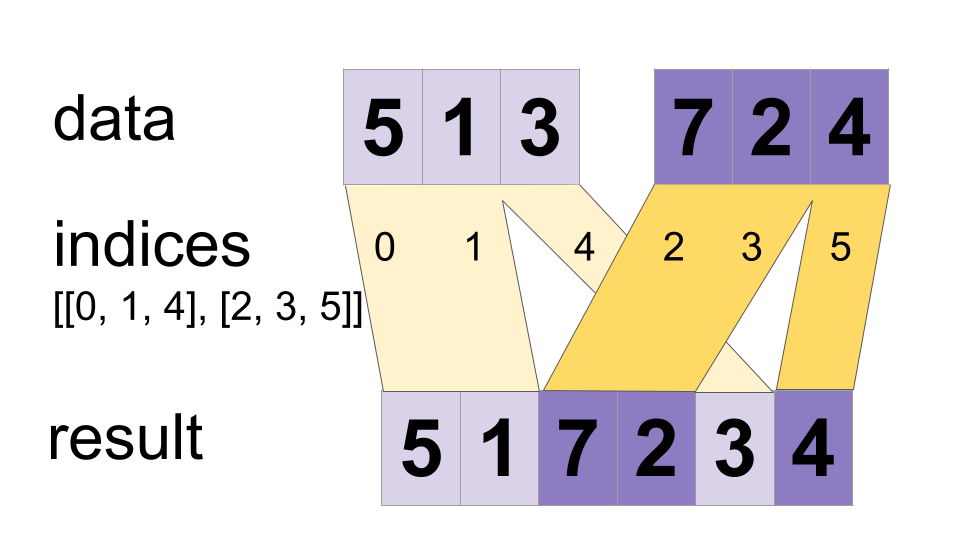
@@ -102,7 +102,7 @@ For example:
```
-
+
partitions: Any shape. Indices in the range `[0, num_partitions)`.
@@ -190,7 +190,7 @@ For example:
```
-
+
)doc");
diff --git a/tensorflow/core/ops/resource_variable_ops.cc b/tensorflow/core/ops/resource_variable_ops.cc
index c190b81dde3..c060aa6be91 100644
--- a/tensorflow/core/ops/resource_variable_ops.cc
+++ b/tensorflow/core/ops/resource_variable_ops.cc
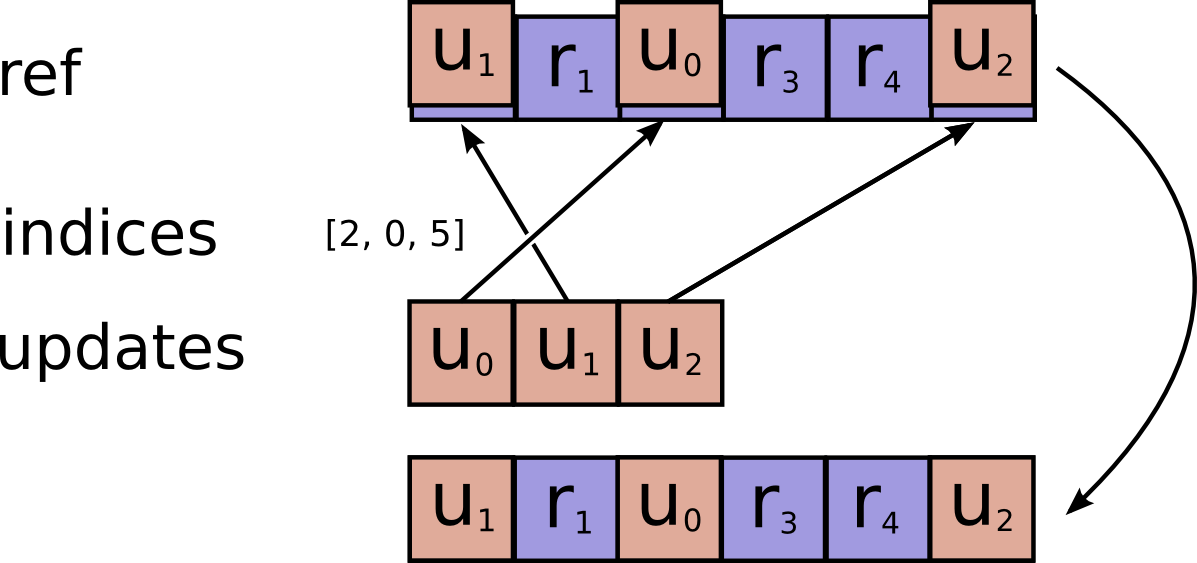
@@ -295,7 +295,7 @@ the same location, their contributions add.
Requires `updates.shape = indices.shape + ref.shape[1:]`.
-
+
resource: Should be from a `Variable` node.
diff --git a/tensorflow/core/ops/state_ops.cc b/tensorflow/core/ops/state_ops.cc
index cfb3ea71411..0890d5fc7c7 100644
--- a/tensorflow/core/ops/state_ops.cc
+++ b/tensorflow/core/ops/state_ops.cc
@@ -288,7 +288,7 @@ for each value is undefined.
Requires `updates.shape = indices.shape + ref.shape[1:]`.
-
+
ref: Should be from a `Variable` node.
@@ -332,7 +332,7 @@ the same location, their contributions add.
Requires `updates.shape = indices.shape + ref.shape[1:]`.
-
+
ref: Should be from a `Variable` node.
@@ -376,7 +376,7 @@ the same location, their (negated) contributions add.
Requires `updates.shape = indices.shape + ref.shape[1:]`.
-
+
ref: Should be from a `Variable` node.
diff --git a/tensorflow/docs_src/api_guides/python/contrib.integrate.md b/tensorflow/docs_src/api_guides/python/contrib.integrate.md
index e6b730b2035..e95b5a2e686 100644
--- a/tensorflow/docs_src/api_guides/python/contrib.integrate.md
+++ b/tensorflow/docs_src/api_guides/python/contrib.integrate.md
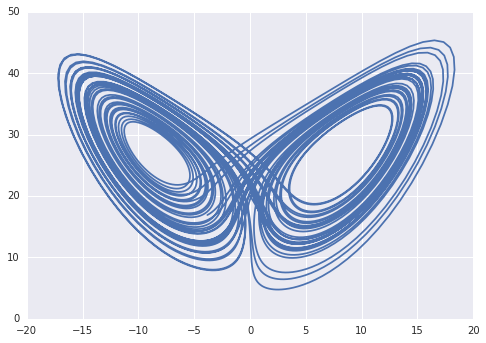
@@ -33,7 +33,7 @@ plt.plot(x, z)
```
-
+
## Ops
diff --git a/tensorflow/docs_src/extend/architecture.md b/tensorflow/docs_src/extend/architecture.md
index 42721eb488c..21816502ace 100644
--- a/tensorflow/docs_src/extend/architecture.md
+++ b/tensorflow/docs_src/extend/architecture.md
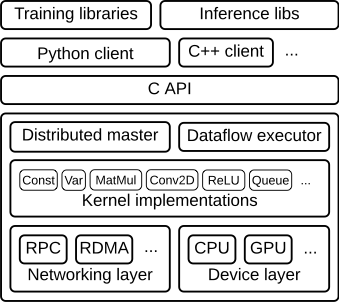
@@ -25,7 +25,7 @@ The TensorFlow runtime is a cross-platform library. Figure 1 illustrates its
general architecture. A C API separates user level code in different languages
from the core runtime.
-{: width="300"}
+{: width="300"}
**Figure 1**
@@ -57,7 +57,7 @@ Other tasks send updates to these parameters as they work on optimizing the
parameters. This particular division of labor between tasks is not required, but
it is common for distributed training.
-{: width="500"}
+{: width="500"}
**Figure 2**
@@ -91,7 +91,7 @@ In Figure 3, the client has built a graph that applies weights (w) to a
feature vector (x), adds a bias term (b) and saves the result in a variable
(s).
-{: width="700"}
+{: width="700"}
**Figure 3**
@@ -114,7 +114,7 @@ a step, it applies standard optimizations such as common subexpression
elimination and constant folding. It then coordinates execution of the
optimized subgraphs across a set of tasks.
-{: width="700"}
+{: width="700"}
**Figure 4**
@@ -123,7 +123,7 @@ Figure 5 shows a possible partition of our example graph. The distributed
master has grouped the model parameters in order to place them together on the
parameter server.
-{: width="700"}
+{: width="700"}
**Figure 5**
@@ -132,14 +132,14 @@ Where graph edges are cut by the partition, the distributed master inserts
send and receive nodes to pass information between the distributed tasks
(Figure 6).
-{: width="700"}
+{: width="700"}
**Figure 6**
The distributed master then ships the graph pieces to the distributed tasks.
-{: width="700"}
+{: width="700"}
**Figure 7**
@@ -181,7 +181,7 @@ We also have preliminary support for NVIDIA's NCCL library for multi-GPU
communication (see [`tf.contrib.nccl`](
https://www.tensorflow.org/code/tensorflow/contrib/nccl/python/ops/nccl_ops.py)).
-{: width="700"}
+{: width="700"}
**Figure 8**
diff --git a/tensorflow/docs_src/extend/estimators.md b/tensorflow/docs_src/extend/estimators.md
index 28f62e01ab0..c5444c59cab 100644
--- a/tensorflow/docs_src/extend/estimators.md
+++ b/tensorflow/docs_src/extend/estimators.md
@@ -72,7 +72,7 @@ for abalone:
The label to predict is number of rings, as a proxy for abalone age.
- **[“Abalone
+ **[“Abalone
shell”](https://www.flickr.com/photos/thenickster/16641048623/) (by [Nicki Dugan
Pogue](https://www.flickr.com/photos/thenickster/), CC BY-SA 2.0)**
diff --git a/tensorflow/docs_src/get_started/embedding_viz.md b/tensorflow/docs_src/get_started/embedding_viz.md
index f512d5d809b..84245b11bea 100644
--- a/tensorflow/docs_src/get_started/embedding_viz.md
+++ b/tensorflow/docs_src/get_started/embedding_viz.md
@@ -21,7 +21,7 @@ interested in word embeddings,
gives a good introduction.
@@ -173,7 +173,7 @@ last data point in the bottom right:
Note in the example above that the last row doesn't have to be filled. For a
concrete example of a sprite, see
-[this sprite image](../images/mnist_10k_sprite.png) of 10,000 MNIST digits
+[this sprite image](https://www.tensorflow.org/images/mnist_10k_sprite.png) of 10,000 MNIST digits
(100x100).
Note: We currently support sprites up to 8192px X 8192px.
@@ -247,7 +247,7 @@ further analysis on their own with the "Isolate Points" button in the Inspector
pane on the right hand side.
-
+
*Selection of the nearest neighbors of “important” in a word embedding dataset.*
The combination of filtering with custom projection can be powerful. Below, we filtered
@@ -260,10 +260,10 @@ You can see that on the right side we have “ideas”, “science”, “perspe
-
+
-
+
@@ -284,4 +284,4 @@ projection) as a small file. The Projector can then be pointed to a set of one
or more of these files, producing the panel below. Other users can then walk
through a sequence of bookmarks.
-
+
diff --git a/tensorflow/docs_src/get_started/get_started.md b/tensorflow/docs_src/get_started/get_started.md
index 6bee7529d0a..b52adc3790a 100644
--- a/tensorflow/docs_src/get_started/get_started.md
+++ b/tensorflow/docs_src/get_started/get_started.md
@@ -123,7 +123,7 @@ TensorFlow provides a utility called TensorBoard that can display a picture of
the computational graph. Here is a screenshot showing how TensorBoard
visualizes the graph:
-
+
As it stands, this graph is not especially interesting because it always
produces a constant result. A graph can be parameterized to accept external
@@ -154,7 +154,7 @@ resulting in the output
In TensorBoard, the graph looks like this:
-
+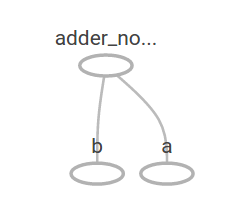
We can make the computational graph more complex by adding another operation.
For example,
@@ -170,7 +170,7 @@ produces the output
The preceding computational graph would look as follows in TensorBoard:
-
+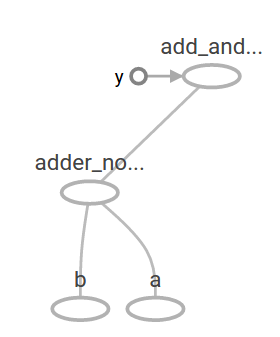
In machine learning we will typically want a model that can take arbitrary
inputs, such as the one above. To make the model trainable, we need to be able
@@ -336,7 +336,7 @@ program your loss will not be exactly the same, because the model is initialized
with random values.
This more complicated program can still be visualized in TensorBoard
-
+
## `tf.contrib.learn`
diff --git a/tensorflow/docs_src/get_started/graph_viz.md b/tensorflow/docs_src/get_started/graph_viz.md
index b69103299ea..06ec427b757 100644
--- a/tensorflow/docs_src/get_started/graph_viz.md
+++ b/tensorflow/docs_src/get_started/graph_viz.md
@@ -2,7 +2,7 @@
TensorFlow computation graphs are powerful but complicated. The graph visualization can help you understand and debug them. Here's an example of the visualization at work.
-
+
*Visualization of a TensorFlow graph.*
To see your own graph, run TensorBoard pointing it to the log directory of the job, click on the graph tab on the top pane and select the appropriate run using the menu at the upper left corner. For in depth information on how to run TensorBoard and make sure you are logging all the necessary information, see @{$summaries_and_tensorboard$TensorBoard: Visualizing Learning}.
@@ -43,10 +43,10 @@ expanded states.
-
+
-
+
@@ -87,10 +87,10 @@ and the auxiliary area.
-
+
-
+
@@ -114,10 +114,10 @@ specific set of nodes.
-
+
-
+
@@ -135,15 +135,15 @@ for constants and summary nodes. To summarize, here's a table of node symbols:
Symbol | Meaning
--- | ---
- | *High-level* node representing a name scope. Double-click to expand a high-level node.
- | Sequence of numbered nodes that are not connected to each other.
- | Sequence of numbered nodes that are connected to each other.
- | An individual operation node.
- | A constant.
- | A summary node.
- | Edge showing the data flow between operations.
- | Edge showing the control dependency between operations.
- | A reference edge showing that the outgoing operation node can mutate the incoming tensor.
+ | *High-level* node representing a name scope. Double-click to expand a high-level node.
+ | Sequence of numbered nodes that are not connected to each other.
+ | Sequence of numbered nodes that are connected to each other.
+ | An individual operation node.
+ | A constant.
+ | A summary node.
+ | Edge showing the data flow between operations.
+ | Edge showing the control dependency between operations.
+ | A reference edge showing that the outgoing operation node can mutate the incoming tensor.
## Interaction {#interaction}
@@ -161,10 +161,10 @@ right corner of the visualization.
-
+
-
+
@@ -207,10 +207,10 @@ The images below give an illustration for a piece of a real-life graph.
-
+
-
+
@@ -233,7 +233,7 @@ The images below show the CIFAR-10 model with tensor shape information:
-
+
@@ -303,13 +303,13 @@ tensor output sizes.
-
+
-
+
-
+
diff --git a/tensorflow/docs_src/get_started/mnist/beginners.md b/tensorflow/docs_src/get_started/mnist/beginners.md
index 2da2c19ea60..624d9164748 100644
--- a/tensorflow/docs_src/get_started/mnist/beginners.md
+++ b/tensorflow/docs_src/get_started/mnist/beginners.md
@@ -15,7 +15,7 @@ MNIST is a simple computer vision dataset. It consists of images of handwritten
digits like these:
-
+
It also includes labels for each image, telling us which digit it is. For
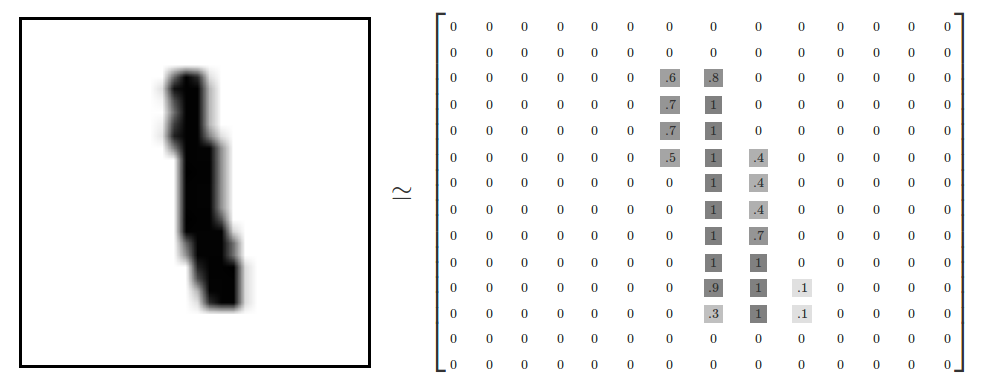
@@ -88,7 +88,7 @@ Each image is 28 pixels by 28 pixels. We can interpret this as a big array of
numbers:
-
+
We can flatten this array into a vector of 28x28 = 784 numbers. It doesn't
@@ -110,7 +110,7 @@ Each entry in the tensor is a pixel intensity between 0 and 1, for a particular
pixel in a particular image.
-
+
Each image in MNIST has a corresponding label, a number between 0 and 9
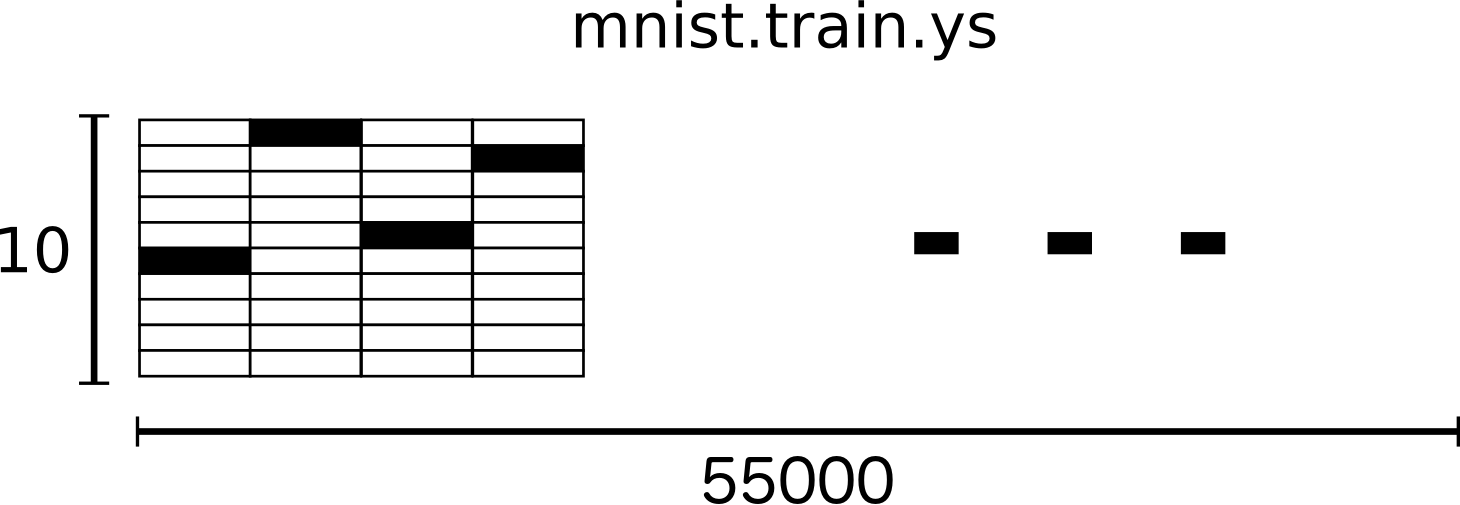
@@ -124,7 +124,7 @@ vector which is 1 in the \\(n\\)th dimension. For example, 3 would be
`[55000, 10]` array of floats.
-
+
We're now ready to actually make our model!
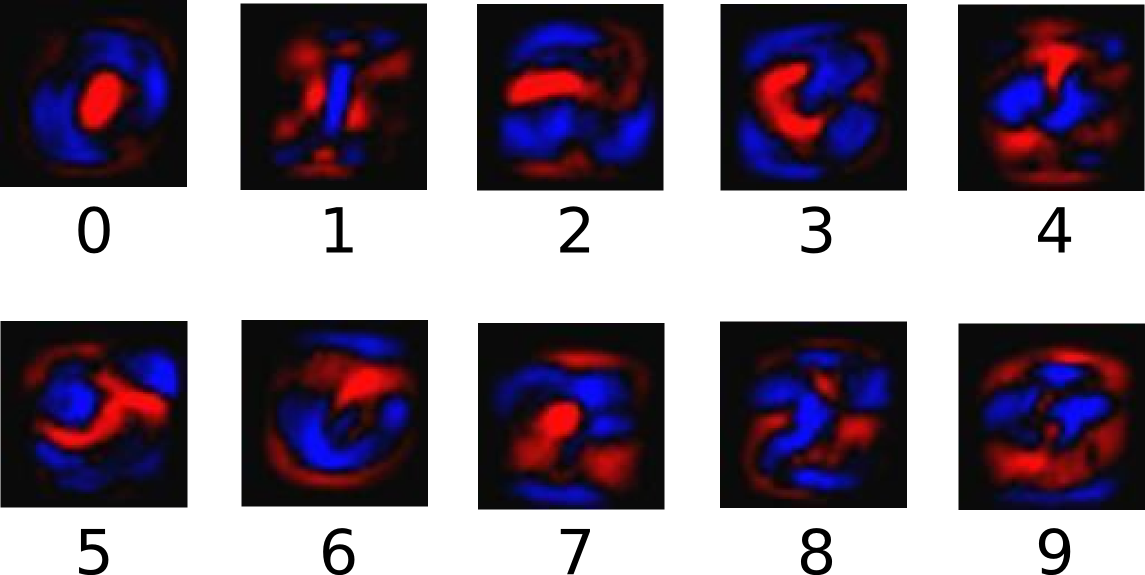
@@ -157,7 +157,7 @@ classes. Red represents negative weights, while blue represents positive
weights.
-
+
We also add some extra evidence called a bias. Basically, we want to be able
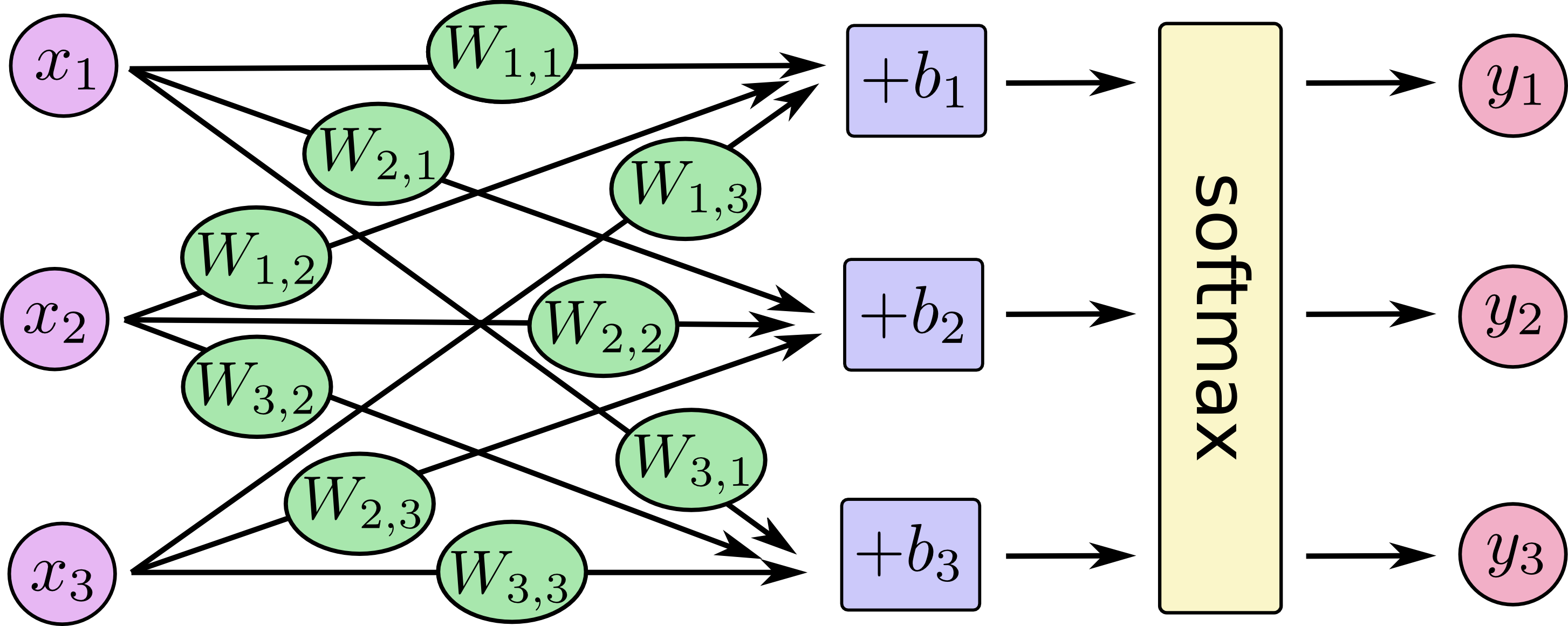
@@ -202,13 +202,13 @@ although with a lot more \\(x\\)s. For each output, we compute a weighted sum of
the \\(x\\)s, add a bias, and then apply softmax.
-
+
If we write that out as equations, we get:
-
@@ -217,7 +217,7 @@ and vector addition. This is helpful for computational efficiency. (It's also
a useful way to think.)
-
diff --git a/tensorflow/docs_src/get_started/mnist/mechanics.md b/tensorflow/docs_src/get_started/mnist/mechanics.md
index b55a5c19ff9..48d9a395f28 100644
--- a/tensorflow/docs_src/get_started/mnist/mechanics.md
+++ b/tensorflow/docs_src/get_started/mnist/mechanics.md
@@ -34,7 +34,7 @@ MNIST is a classic problem in machine learning. The problem is to look at
greyscale 28x28 pixel images of handwritten digits and determine which digit
the image represents, for all the digits from zero to nine.
-
+
For more information, refer to [Yann LeCun's MNIST page](http://yann.lecun.com/exdb/mnist/)
or [Chris Olah's visualizations of MNIST](http://colah.github.io/posts/2014-10-Visualizing-MNIST/).
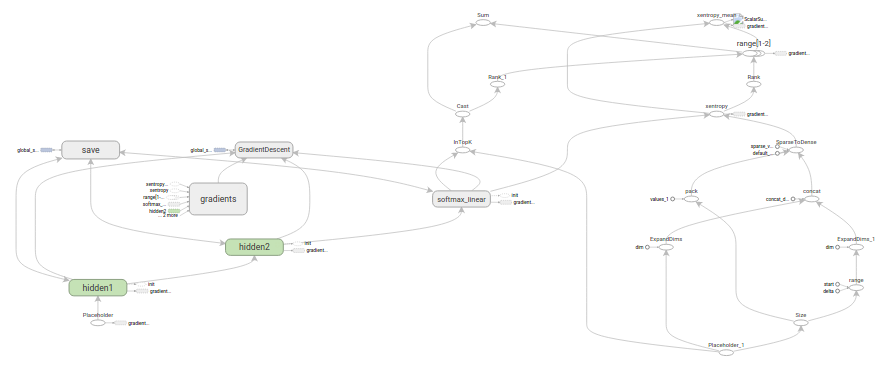
@@ -90,7 +90,7 @@ loss.
and apply gradients.
-
+
### Inference
@@ -384,7 +384,7 @@ summary_writer.add_summary(summary_str, step)
When the events files are written, TensorBoard may be run against the training
folder to display the values from the summaries.
-
+
**NOTE**: For more info about how to build and run Tensorboard, please see the accompanying tutorial @{$summaries_and_tensorboard$Tensorboard: Visualizing Learning}.
diff --git a/tensorflow/docs_src/get_started/monitors.md b/tensorflow/docs_src/get_started/monitors.md
index 7db88c89812..cb4ef70eebf 100644
--- a/tensorflow/docs_src/get_started/monitors.md
+++ b/tensorflow/docs_src/get_started/monitors.md
@@ -401,6 +401,6 @@ Then navigate to `http://0.0.0.0:`*``* in your browser, where
If you click on the accuracy field, you'll see an image like the following,
which shows accuracy plotted against step count:
-
+
For more on using TensorBoard, see @{$summaries_and_tensorboard$TensorBoard: Visualizing Learning} and @{$graph_viz$TensorBoard: Graph Visualization}.
diff --git a/tensorflow/docs_src/get_started/summaries_and_tensorboard.md b/tensorflow/docs_src/get_started/summaries_and_tensorboard.md
index 6e06c9e41e4..45d43e7a6e7 100644
--- a/tensorflow/docs_src/get_started/summaries_and_tensorboard.md
+++ b/tensorflow/docs_src/get_started/summaries_and_tensorboard.md
@@ -8,7 +8,7 @@ your TensorFlow graph, plot quantitative metrics about the execution of your
graph, and show additional data like images that pass through it. When
TensorBoard is fully configured, it looks like this:
-
+
 +
+
 +
+
 +
+
 +
+
 +
+
 +
+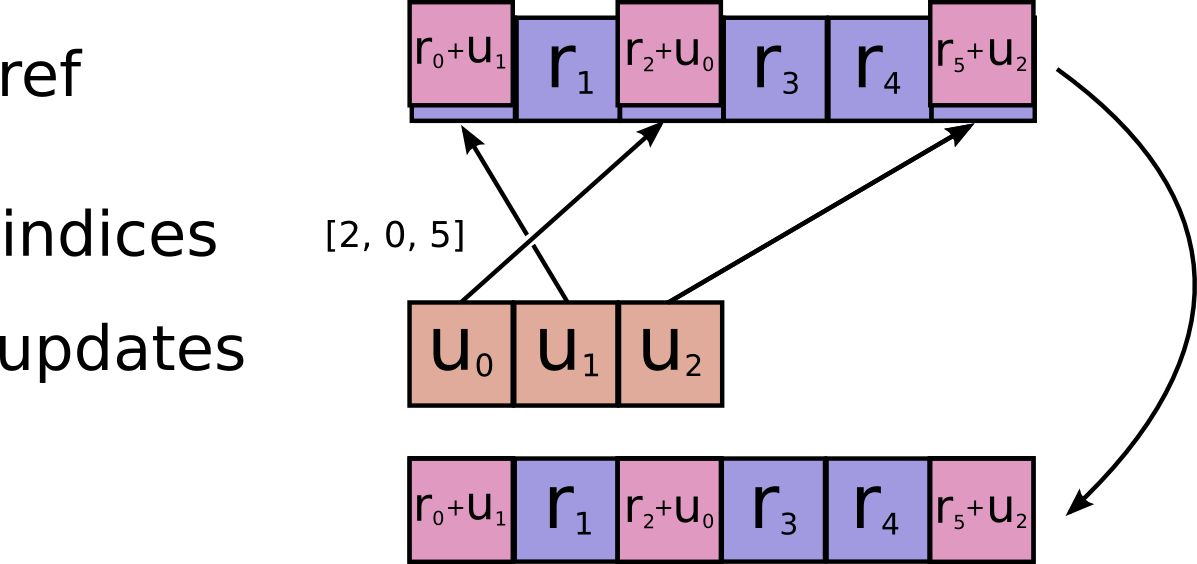
 +
+
 +
+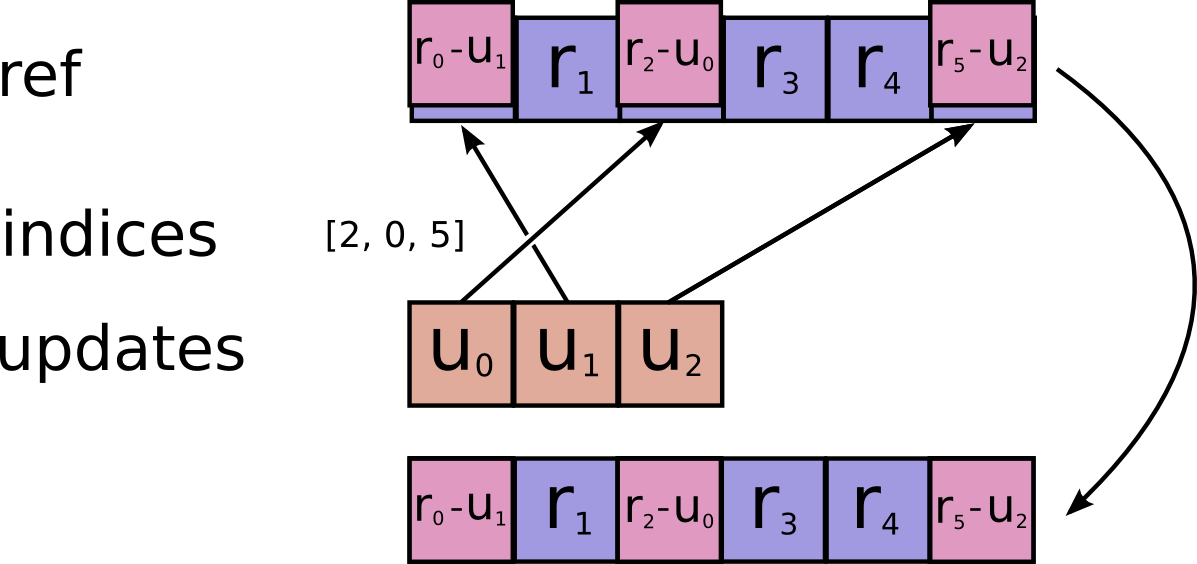
 +
+
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+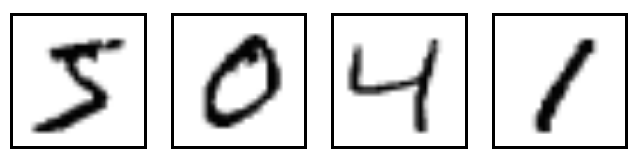
 +
+
 +
+
 +
+
 +
+
 +
+
![[y1, y2, y3] = softmax(W11*x1 + W12*x2 + W13*x3 + b1, W21*x1 + W22*x2 + W23*x3 + b2, W31*x1 + W32*x2 + W33*x3 + b3)](../../images/softmax-regression-scalarequation.png)
![[y1, y2, y3] = softmax([[W11, W12, W13], [W21, W22, W23], [W31, W32, W33]]*[x1, x2, x3] + [b1, b2, b3])](../../images/softmax-regression-vectorequation.png)
 +
+ 
 +
+ diff --git a/tensorflow/docs_src/get_started/get_started.md b/tensorflow/docs_src/get_started/get_started.md
index 6bee7529d0a..b52adc3790a 100644
--- a/tensorflow/docs_src/get_started/get_started.md
+++ b/tensorflow/docs_src/get_started/get_started.md
@@ -123,7 +123,7 @@ TensorFlow provides a utility called TensorBoard that can display a picture of
the computational graph. Here is a screenshot showing how TensorBoard
visualizes the graph:
-
+
As it stands, this graph is not especially interesting because it always
produces a constant result. A graph can be parameterized to accept external
@@ -154,7 +154,7 @@ resulting in the output
In TensorBoard, the graph looks like this:
-
+
We can make the computational graph more complex by adding another operation.
For example,
@@ -170,7 +170,7 @@ produces the output
The preceding computational graph would look as follows in TensorBoard:
-
+
In machine learning we will typically want a model that can take arbitrary
inputs, such as the one above. To make the model trainable, we need to be able
@@ -336,7 +336,7 @@ program your loss will not be exactly the same, because the model is initialized
with random values.
This more complicated program can still be visualized in TensorBoard
-
+
## `tf.contrib.learn`
diff --git a/tensorflow/docs_src/get_started/graph_viz.md b/tensorflow/docs_src/get_started/graph_viz.md
index b69103299ea..06ec427b757 100644
--- a/tensorflow/docs_src/get_started/graph_viz.md
+++ b/tensorflow/docs_src/get_started/graph_viz.md
@@ -2,7 +2,7 @@
TensorFlow computation graphs are powerful but complicated. The graph visualization can help you understand and debug them. Here's an example of the visualization at work.
-
+
*Visualization of a TensorFlow graph.*
To see your own graph, run TensorBoard pointing it to the log directory of the job, click on the graph tab on the top pane and select the appropriate run using the menu at the upper left corner. For in depth information on how to run TensorBoard and make sure you are logging all the necessary information, see @{$summaries_and_tensorboard$TensorBoard: Visualizing Learning}.
@@ -43,10 +43,10 @@ expanded states.
diff --git a/tensorflow/docs_src/get_started/get_started.md b/tensorflow/docs_src/get_started/get_started.md
index 6bee7529d0a..b52adc3790a 100644
--- a/tensorflow/docs_src/get_started/get_started.md
+++ b/tensorflow/docs_src/get_started/get_started.md
@@ -123,7 +123,7 @@ TensorFlow provides a utility called TensorBoard that can display a picture of
the computational graph. Here is a screenshot showing how TensorBoard
visualizes the graph:
-
+
As it stands, this graph is not especially interesting because it always
produces a constant result. A graph can be parameterized to accept external
@@ -154,7 +154,7 @@ resulting in the output
In TensorBoard, the graph looks like this:
-
+
We can make the computational graph more complex by adding another operation.
For example,
@@ -170,7 +170,7 @@ produces the output
The preceding computational graph would look as follows in TensorBoard:
-
+
In machine learning we will typically want a model that can take arbitrary
inputs, such as the one above. To make the model trainable, we need to be able
@@ -336,7 +336,7 @@ program your loss will not be exactly the same, because the model is initialized
with random values.
This more complicated program can still be visualized in TensorBoard
-
+
## `tf.contrib.learn`
diff --git a/tensorflow/docs_src/get_started/graph_viz.md b/tensorflow/docs_src/get_started/graph_viz.md
index b69103299ea..06ec427b757 100644
--- a/tensorflow/docs_src/get_started/graph_viz.md
+++ b/tensorflow/docs_src/get_started/graph_viz.md
@@ -2,7 +2,7 @@
TensorFlow computation graphs are powerful but complicated. The graph visualization can help you understand and debug them. Here's an example of the visualization at work.
-
+
*Visualization of a TensorFlow graph.*
To see your own graph, run TensorBoard pointing it to the log directory of the job, click on the graph tab on the top pane and select the appropriate run using the menu at the upper left corner. For in depth information on how to run TensorBoard and make sure you are logging all the necessary information, see @{$summaries_and_tensorboard$TensorBoard: Visualizing Learning}.
@@ -43,10 +43,10 @@ expanded states.